RAM: Towards an Ever-Improving Memory System by Learning from Communications
2404.12045
0
0
💬
Abstract
We introduce RAM, an innovative RAG-based framework with an ever-improving memory. Inspired by humans' pedagogical process, RAM utilizes recursively reasoning-based retrieval and experience reflections to continually update the memory and learn from users' communicative feedback, namely communicative learning. Extensive experiments with both simulated and real users demonstrate significant improvements over traditional RAG and self-knowledge methods, particularly excelling in handling false premise and multi-hop questions. Furthermore, RAM exhibits promising adaptability to various feedback and retrieval method chain types, showcasing its potential for advancing AI capabilities in dynamic knowledge acquisition and lifelong learning.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces RAM, a novel RAG-based framework with an ever-improving memory
- Inspired by humans' pedagogical process, RAM uses recursively reasoning-based retrieval and experience reflections to continuously update its memory and learn from user feedback
- Experiments show significant improvements over traditional RAG and self-knowledge methods, especially in handling false premises and multi-hop questions
- RAM exhibits adaptability to various feedback and retrieval method chains, showcasing its potential for advancing AI capabilities in dynamic knowledge acquisition and lifelong learning
Plain English Explanation
The research paper introduces a new AI system called RAM, which stands for "Recursively-Updating Augmented Memory". RAM is based on a technique called Retrieval Augmented Generation (RAG), but with an important twist - it has an "ever-improving memory" that can learn and adapt over time.
The key idea behind RAM is to mimic the way humans learn. When we encounter new information, we don't just passively store it - we actively reflect on it, make connections to what we already know, and update our understanding. RAM tries to do something similar. It uses "recursively reasoning-based retrieval" to pull relevant information from its memory, and then it "learns from users' communicative feedback" to continually refine and expand that memory.
In experiments, RAM performed significantly better than traditional RAG systems, especially on tricky tasks like answering questions that have false premises or require multiple steps of reasoning. The researchers also found that RAM was adaptable - it could work with different types of feedback and retrieval methods, suggesting it has a lot of potential for real-world applications that require dynamic knowledge acquisition and lifelong learning.
Technical Explanation
The key innovation in RAM is its use of "recursively reasoning-based retrieval" and "experience reflections" to continually update its internal memory. Rather than simply retrieving information from a static knowledge base, RAM dynamically reasons about the current task and query to identify the most relevant information to retrieve from its ever-evolving memory.
This retrieval process is coupled with a "communicative learning" approach, where RAM learns from the feedback and interactions it receives from users. When a user provides input or corrects RAM, the system reflects on that experience and updates its memory accordingly. This allows RAM to gradually improve its knowledge and reasoning capabilities over time, in a way that resembles how humans learn.
The researchers evaluated RAM in both simulated and real-world settings, and found that it outperformed traditional RAG systems as well as models relying on self-generated knowledge. RAM was particularly adept at handling false premises and multi-hop questions, suggesting its reasoning and memory capabilities are more robust than previous approaches.
Interestingly, the researchers also found that RAM exhibited promising adaptability to different types of feedback and retrieval method chains. This indicates that the core RAM framework has the potential to be applied to a wide range of memory-augmented AI systems and retrieval-augmented agents, advancing the state of the art in dynamic knowledge acquisition and lifelong learning.
Critical Analysis
The RAM framework represents a significant step forward in developing AI systems that can continually learn and adapt, much like humans do. By incorporating recursive reasoning and experience reflections, RAM is able to go beyond simply retrieving information from a static knowledge base and instead dynamically reason about the current task and update its internal understanding.
That said, the paper does not delve deeply into the specific mechanisms underlying RAM's memory updates and learning process. While the high-level approach is clear, more details on the algorithms and heuristics used would be helpful for fully evaluating the system's capabilities and limitations.
Additionally, the experiments in the paper were conducted in relatively constrained settings, such as simulated conversations and a limited set of question types. It would be valuable to see how RAM performs in more open-ended, real-world scenarios that involve a wider range of tasks and interactions.
Another area for further exploration is the scalability of the RAM approach. As the system's memory and knowledge base grow, the computational and memory requirements for the recursive reasoning and experience reflection processes may become prohibitive. Investigating techniques to maintain efficiency as the system evolves would be an important area of future research.
Conclusion
Overall, the RAM framework represents a promising step towards developing AI systems that can dynamically acquire and refine knowledge in a manner akin to human learning. By leveraging recursive reasoning and communicative feedback, RAM is able to outperform traditional approaches on tasks that require robust reasoning and adaptability.
The adaptability and potential for lifelong learning demonstrated by RAM suggest that this line of research could lead to significant advancements in AI capabilities, with applications ranging from conversational agents to embodied AI systems. As the field continues to evolve, the insights and techniques developed in this work may prove invaluable for creating AI systems that can truly learn and grow alongside their human users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
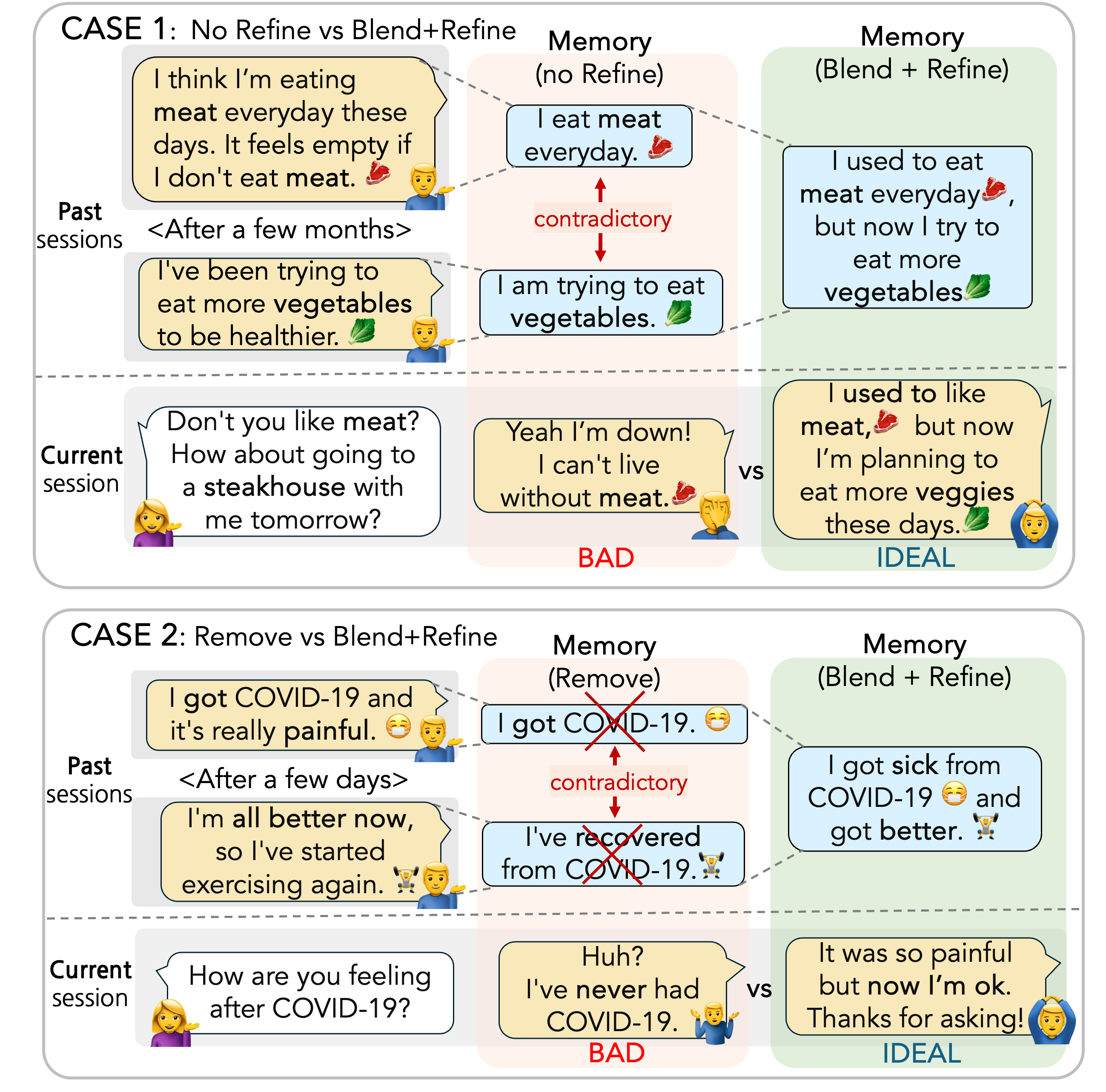
Ever-Evolving Memory by Blending and Refining the Past
Seo Hyun Kim, Keummin Ka, Yohan Jo, Seung-won Hwang, Dongha Lee, Jinyoung Yeo
0
0
For a human-like chatbot, constructing a long-term memory is crucial. However, current large language models often lack this capability, leading to instances of missing important user information or redundantly asking for the same information, thereby diminishing conversation quality. To effectively construct memory, it is crucial to seamlessly connect past and present information, while also possessing the ability to forget obstructive information. To address these challenges, we propose CREEM, a novel memory system for long-term conversation. Improving upon existing approaches that construct memory based solely on current sessions, CREEM blends past memories during memory formation. Additionally, we introduce a refining process to handle redundant or outdated information. Unlike traditional paradigms, we view responding and memory construction as inseparable tasks. The blending process, which creates new memories, also serves as a reasoning step for response generation by informing the connection between past and present. Through evaluation, we demonstrate that CREEM enhances both memory and response qualities in multi-session personalized dialogues.
4/9/2024
🛸
Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures
Ruiyang Qin, Zheyu Yan, Dewen Zeng, Zhenge Jia, Dancheng Liu, Jianbo Liu, Zhi Zheng, Ningyuan Cao, Kai Ni, Jinjun Xiong, Yiyu Shi
0
0
Large Language Models (LLMs) deployed on edge devices learn through fine-tuning and updating a certain portion of their parameters. Although such learning methods can be optimized to reduce resource utilization, the overall required resources remain a heavy burden on edge devices. Instead, Retrieval-Augmented Generation (RAG), a resource-efficient LLM learning method, can improve the quality of the LLM-generated content without updating model parameters. However, the RAG-based LLM may involve repetitive searches on the profile data in every user-LLM interaction. This search can lead to significant latency along with the accumulation of user data. Conventional efforts to decrease latency result in restricting the size of saved user data, thus reducing the scalability of RAG as user data continuously grows. It remains an open question: how to free RAG from the constraints of latency and scalability on edge devices? In this paper, we propose a novel framework to accelerate RAG via Computing-in-Memory (CiM) architectures. It accelerates matrix multiplications by performing in-situ computation inside the memory while avoiding the expensive data transfer between the computing unit and memory. Our framework, Robust CiM-backed RAG (RoCR), utilizing a novel contrastive learning-based training method and noise-aware training, can enable RAG to efficiently search profile data with CiM. To the best of our knowledge, this is the first work utilizing CiM to accelerate RAG.
5/9/2024

MemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory
Ali Modarressi, Abdullatif Koksal, Ayyoob Imani, Mohsen Fayyaz, Hinrich Schutze
0
0
While current large language models (LLMs) demonstrate some capabilities in knowledge-intensive tasks, they are limited by relying on their parameters as an implicit storage mechanism. As a result, they struggle with infrequent knowledge and temporal degradation. In addition, the uninterpretable nature of parametric memorization makes it challenging to understand and prevent hallucination. Parametric memory pools and model editing are only partial solutions. Retrieval Augmented Generation (RAG) $unicode{x2013}$ though non-parametric $unicode{x2013}$ has its own limitations: it lacks structure, complicates interpretability and makes it hard to effectively manage stored knowledge. In this paper, we introduce MemLLM, a novel method of enhancing LLMs by integrating a structured and explicit read-and-write memory module. MemLLM tackles the aforementioned challenges by enabling dynamic interaction with the memory and improving the LLM's capabilities in using stored knowledge. Our experiments indicate that MemLLM enhances the LLM's performance and interpretability, in language modeling in general and knowledge-intensive tasks in particular. We see MemLLM as an important step towards making LLMs more grounded and factual through memory augmentation.
4/19/2024
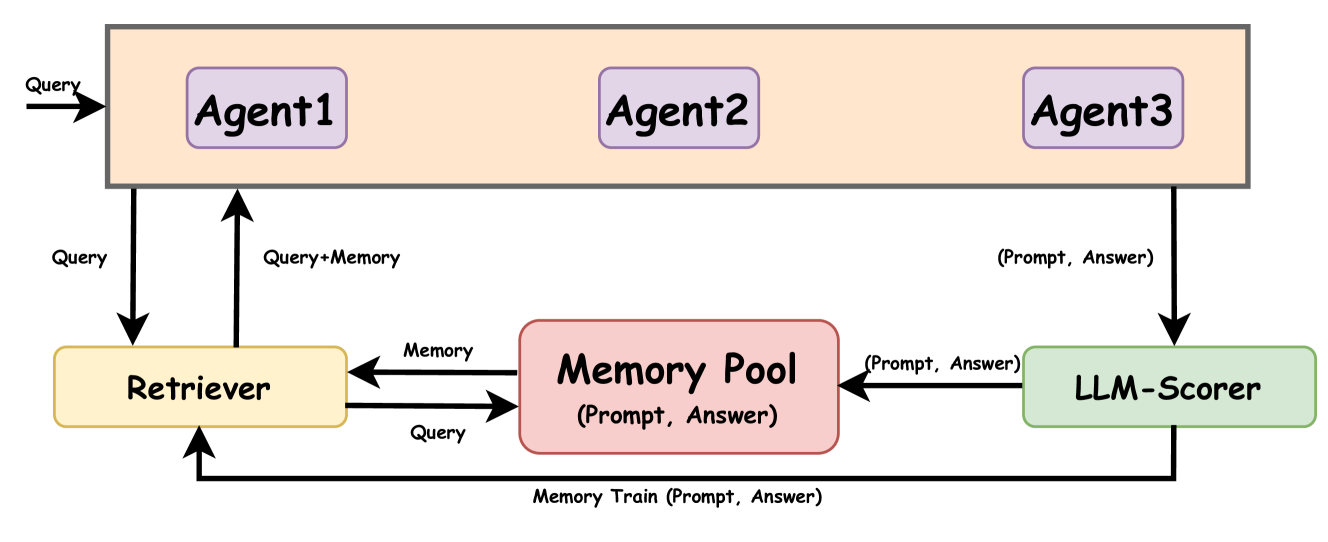
Memory Sharing for Large Language Model based Agents
Hang Gao, Yongfeng Zhang
0
0
In the realm of artificial intelligence, the adaptation of Large Language Model (LLM)-based agents to execute tasks via natural language prompts represents a significant advancement, notably eliminating the need for explicit retraining or fine tuning for fixed-answer tasks such as common sense questions and yes/no queries. However, the application of In-context Learning to open-ended challenges, such as poetry creation, reveals substantial limitations due to the comprehensiveness of the provided examples and agent's ability to understand the content expressed in the problem, leading to outputs that often diverge significantly from expected results. Addressing this gap, our study introduces the Memory-Sharing (MS) framework for LLM multi-agents, which utilizes a real-time memory storage and retrieval system to enhance the In-context Learning process. Each memory within this system captures both the posed query and the corresponding real-time response from an LLM-based agent, aggregating these memories from a broad spectrum of similar agents to enrich the memory pool shared by all agents. This framework not only aids agents in identifying the most relevant examples for specific tasks but also evaluates the potential utility of their memories for future applications by other agents. Empirical validation across three distinct domains involving specialized functions of agents demonstrates that the MS framework significantly improve the agent's performance regrading the open-ended questions. Furthermore, we also discuss what type of memory pool and what retrieval strategy in MS can better help agents, offering a future develop direction of MS. The code and data are available at: https://github.com/GHupppp/MemorySharingLLM
4/16/2024