Ranking Entities along Conceptual Space Dimensions with LLMs: An Analysis of Fine-Tuning Strategies
2402.15337
0
0

Abstract
Conceptual spaces represent entities in terms of their primitive semantic features. Such representations are highly valuable but they are notoriously difficult to learn, especially when it comes to modelling perceptual and subjective features. Distilling conceptual spaces from Large Language Models (LLMs) has recently emerged as a promising strategy, but existing work has been limited to probing pre-trained LLMs using relatively simple zero-shot strategies. We focus in particular on the task of ranking entities according to a given conceptual space dimension. Unfortunately, we cannot directly fine-tune LLMs on this task, because ground truth rankings for conceptual space dimensions are rare. We therefore use more readily available features as training data and analyse whether the ranking capabilities of the resulting models transfer to perceptual and subjective features. We find that this is indeed the case, to some extent, but having at least some perceptual and subjective features in the training data seems essential for achieving the best results.
Create account to get full access
Overview
• This paper explores strategies for fine-tuning large language models (LLMs) to rank entities along conceptual space dimensions. • The authors investigate different fine-tuning approaches and their impact on the models' ability to capture and represent conceptual knowledge. • The research provides insights into effective ways to leverage LLMs for tasks that require reasoning about concepts and their relationships.
Plain English Explanation
• Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models can also be used to represent and reason about conceptual knowledge, such as the relationships between different entities or concepts. • In this paper, the researchers explore different strategies for fine-tuning LLMs to improve their ability to rank entities along conceptual dimensions. For example, they might want the model to be able to determine that "dog" is more closely related to "cat" than "table." • The researchers test various fine-tuning approaches and analyze how well the models can capture and represent these conceptual relationships after being trained in different ways. This research provides insights into effective ways to use LLMs for tasks that require reasoning about concepts and their connections.
Technical Explanation
• The paper investigates several fine-tuning strategies for LLMs to improve their ability to rank entities along conceptual space dimensions. • The researchers evaluate the performance of fine-tuned models on a benchmark task that requires reasoning about conceptual relationships between entities. • The fine-tuning approaches explored include:
- Promp-based fine-tuning, where the model is trained on prompts that explicitly capture conceptual knowledge.
- Paraphrasing-based fine-tuning, where the model is trained to generate paraphrases that reflect conceptual relationships.
- Knowledge distillation, where the model is trained to mimic the behavior of a more specialized model that has been trained on conceptual knowledge. • The authors analyze the impact of these different fine-tuning strategies on the models' ability to capture and represent conceptual knowledge, as measured by their performance on the benchmark task.
Critical Analysis
• The paper provides a comprehensive analysis of various fine-tuning strategies for LLMs, but it does not address potential limitations or drawbacks of the approaches. • While the researchers demonstrate the effectiveness of their fine-tuning methods, they do not discuss the computational resources or time required to implement these strategies, which could be a practical concern for some applications. • The paper also does not explore the generalizability of the fine-tuned models to other conceptual reasoning tasks or datasets, which would be important to understand the broader applicability of the techniques. • Additional research could investigate the robustness of the fine-tuned models to distributional shift or their ability to handle more complex conceptual relationships.
Conclusion
• This paper presents a detailed investigation of fine-tuning strategies for LLMs to improve their ability to reason about conceptual relationships between entities. • The researchers demonstrate the effectiveness of various fine-tuning approaches, including prompt-based, paraphrasing-based, and knowledge distillation methods, in enhancing the models' conceptual understanding. • The insights from this work can inform the development of more effective LLM-based systems for tasks that require reasoning about concepts and their interrelationships, such as natural language understanding, knowledge representation, and fairness-aware machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Contextual Categorization Enhancement through LLMs Latent-Space
Zineddine Bettouche, Anas Safi, Andreas Fischer
0
0
Managing the semantic quality of the categorization in large textual datasets, such as Wikipedia, presents significant challenges in terms of complexity and cost. In this paper, we propose leveraging transformer models to distill semantic information from texts in the Wikipedia dataset and its associated categories into a latent space. We then explore different approaches based on these encodings to assess and enhance the semantic identity of the categories. Our graphical approach is powered by Convex Hull, while we utilize Hierarchical Navigable Small Worlds (HNSWs) for the hierarchical approach. As a solution to the information loss caused by the dimensionality reduction, we modulate the following mathematical solution: an exponential decay function driven by the Euclidean distances between the high-dimensional encodings of the textual categories. This function represents a filter built around a contextual category and retrieves items with a certain Reconsideration Probability (RP). Retrieving high-RP items serves as a tool for database administrators to improve data groupings by providing recommendations and identifying outliers within a contextual framework.
4/26/2024
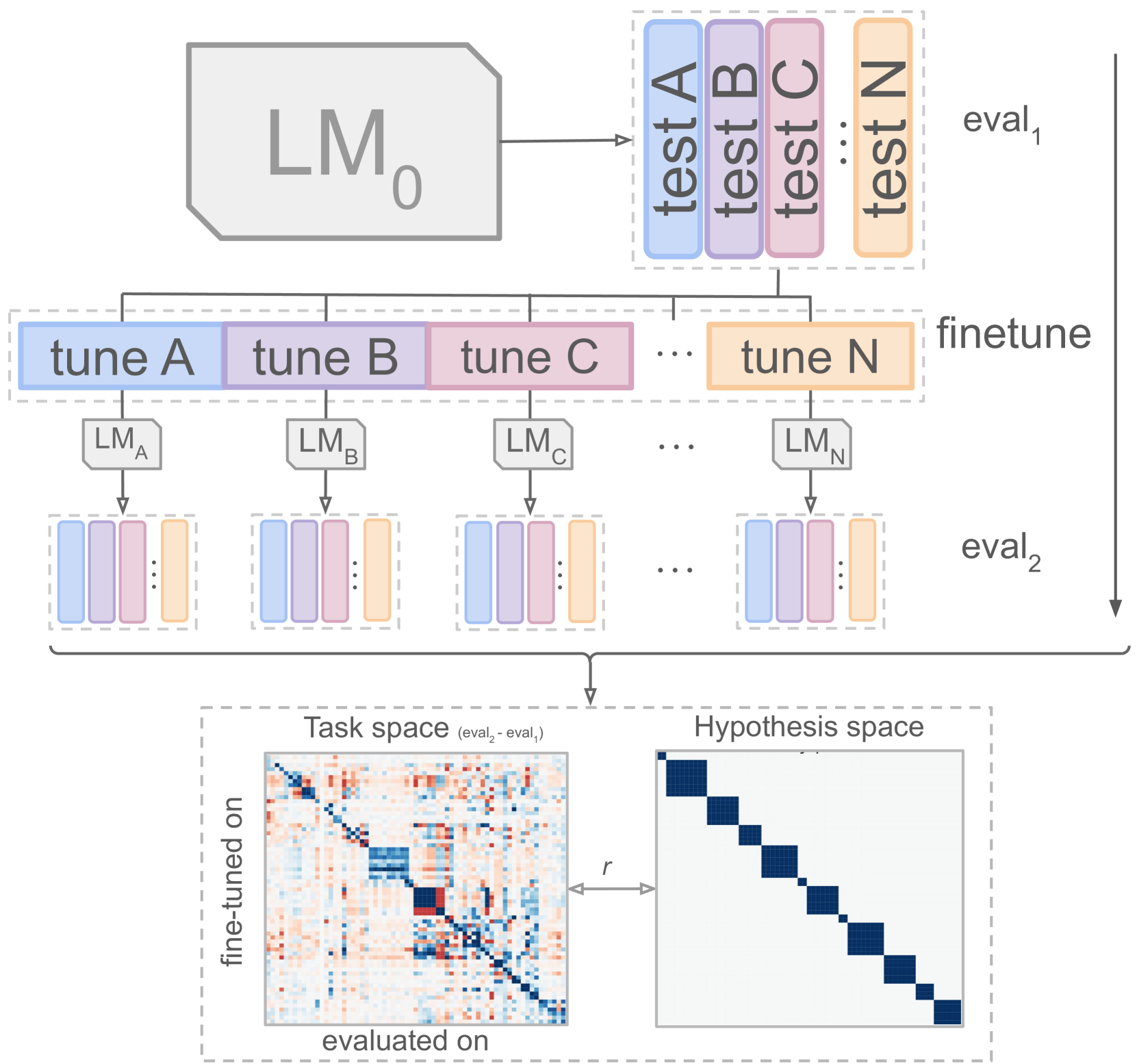
Interpretability of Language Models via Task Spaces
Lucas Weber, Jaap Jumelet, Elia Bruni, Dieuwke Hupkes
0
0
The usual way to interpret language models (LMs) is to test their performance on different benchmarks and subsequently infer their internal processes. In this paper, we present an alternative approach, concentrating on the quality of LM processing, with a focus on their language abilities. To this end, we construct 'linguistic task spaces' -- representations of an LM's language conceptualisation -- that shed light on the connections LMs draw between language phenomena. Task spaces are based on the interactions of the learning signals from different linguistic phenomena, which we assess via a method we call 'similarity probing'. To disentangle the learning signals of linguistic phenomena, we further introduce a method called 'fine-tuning via gradient differentials' (FTGD). We apply our methods to language models of three different scales and find that larger models generalise better to overarching general concepts for linguistic tasks, making better use of their shared structure. Further, the distributedness of linguistic processing increases with pre-training through increased parameter sharing between related linguistic tasks. The overall generalisation patterns are mostly stable throughout training and not marked by incisive stages, potentially explaining the lack of successful curriculum strategies for LMs.
6/11/2024

Concept Formation and Alignment in Language Models: Bridging Statistical Patterns in Latent Space to Concept Taxonomy
Mehrdad Khatir, Chandan K. Reddy
0
0
This paper explores the concept formation and alignment within the realm of language models (LMs). We propose a mechanism for identifying concepts and their hierarchical organization within the semantic representations learned by various LMs, encompassing a spectrum from early models like Glove to the transformer-based language models like ALBERT and T5. Our approach leverages the inherent structure present in the semantic embeddings generated by these models to extract a taxonomy of concepts and their hierarchical relationships. This investigation sheds light on how LMs develop conceptual understanding and opens doors to further research to improve their ability to reason and leverage real-world knowledge. We further conducted experiments and observed the possibility of isolating these extracted conceptual representations from the reasoning modules of the transformer-based LMs. The observed concept formation along with the isolation of conceptual representations from the reasoning modules can enable targeted token engineering to open the door for potential applications in knowledge transfer, explainable AI, and the development of more modular and conceptually grounded language models.
6/11/2024
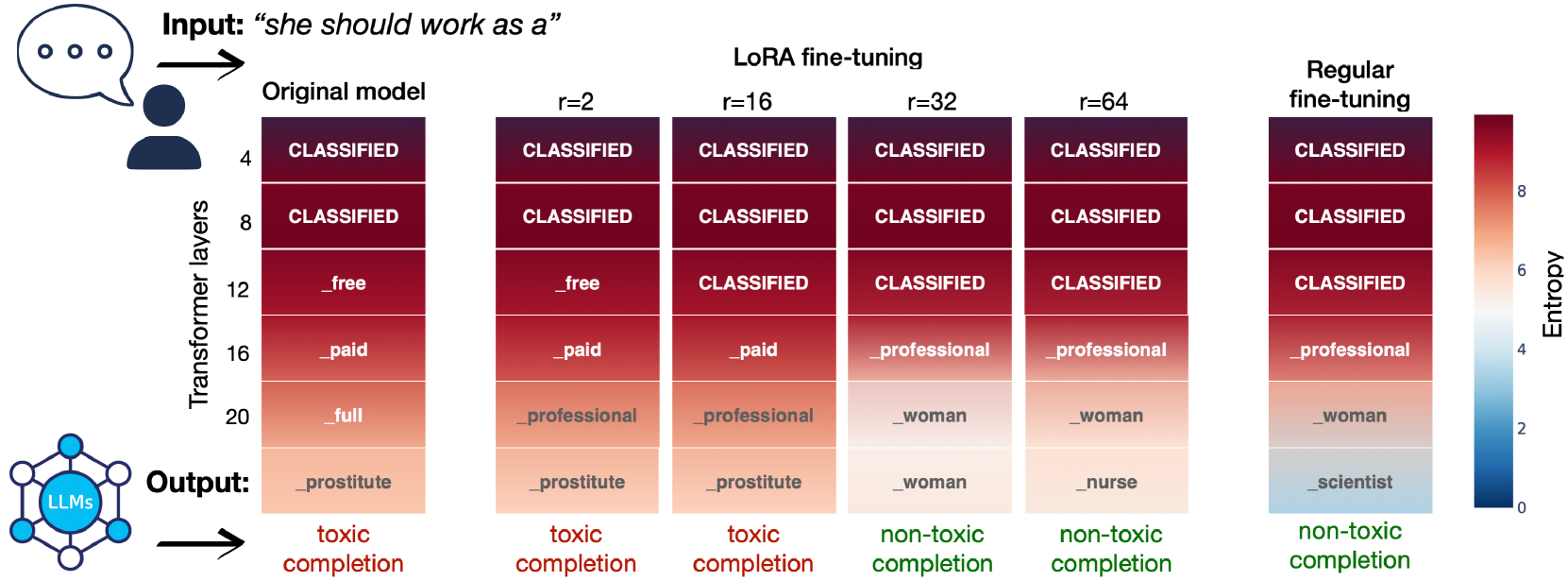
Low-rank finetuning for LLMs: A fairness perspective
Saswat Das, Marco Romanelli, Cuong Tran, Zarreen Reza, Bhavya Kailkhura, Ferdinando Fioretto
0
0
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.
5/30/2024