RayFormer: Improving Query-Based Multi-Camera 3D Object Detection via Ray-Centric Strategies

0

Sign in to get full access
Overview
- RayFormer is a novel approach to improve query-based multi-camera 3D object detection
- It uses "ray-centric" strategies to better leverage information from multiple camera views
- The key innovations include a ray-based query representation and a ray-aware transformer module
Plain English Explanation
The paper proposes a new method called RayFormer to enhance 3D object detection when using multiple camera views. In a typical multi-camera setup, cameras-as-rays-pose-estimation-via-ray each camera can be thought of as a "ray" that captures information about the 3D scene.
RayFormer aims to better utilize this ray-based representation by introducing two key ideas:
-
Ray-based Query Representation: Instead of using a single point or box to represent an object of interest, RayFormer represents the query as a set of rays. This allows the model to capture more spatial information about the object's 3D shape and location.
-
Ray-aware Transformer Module: RayFormer uses a specialized transformer architecture that is designed to operate directly on the ray-based representation. This enables the model to reason about the 3D relationships between different rays, improving the final object detection.
By incorporating these ray-centric strategies, RayFormer is able to outperform previous query-based multi-camera 3D object detection approaches, as demonstrated through experiments on standard benchmarks.
Technical Explanation
The core of RayFormer is a novel query representation and a specialized transformer module that can effectively leverage this representation.
Ray-based Query Representation: Instead of using a single point or bounding box to represent an object query, RayFormer represents the query as a set of rays. Each ray originates from the camera center and passes through a specific point in the 2D image plane. This ray-based representation allows the model to capture more spatial information about the 3D shape and location of the object.
Ray-aware Transformer Module: RayFormer uses a transformer-based architecture that is designed to operate directly on the ray-based query representation. The transformer module includes several specialized components:
-
Ray Encoding: The ray-based query is first encoded into a set of ray features, which capture information about the 3D position, orientation, and appearance of each ray.
-
Ray-Ray Attention: The transformer module computes attention scores between pairs of rays, allowing the model to reason about the 3D relationships between different parts of the object.
-
Ray-Image Attention: The transformer module also computes attention between the rays and features extracted from the multi-view camera images. This enables the model to effectively integrate the 2D visual information with the 3D ray-based representation.
By leveraging these ray-centric strategies, RayFormer is able to outperform previous query-based methods on standard 3D object detection benchmarks, demonstrating the benefits of this approach.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the RayFormer approach, including comparisons to state-of-the-art multi-camera 3D object detection methods on several benchmark datasets. The results showcase the advantages of the ray-based query representation and the ray-aware transformer module.
However, the paper does not discuss potential limitations or areas for future research in depth. For example, it would be interesting to understand how RayFormer's performance scales with the number of camera views or the complexity of the 3D scenes. Additionally, the paper could explore how RayFormer's architecture and design choices might be extended to other 3D perception tasks beyond object detection.
Overall, the RayFormer paper presents a compelling and innovative approach to multi-camera 3D object detection that could have significant implications for real-world applications such as autonomous driving and robotics. Further research and development in this direction could lead to even more powerful 3D perception systems.
Conclusion
The RayFormer paper introduces a novel approach to query-based multi-camera 3D object detection that leverages a ray-centric representation and specialized transformer architecture. By representing the object query as a set of rays and designing a transformer module to reason about these ray-based features, RayFormer is able to outperform previous state-of-the-art methods on standard benchmarks.
This work highlights the potential benefits of incorporating 3D spatial reasoning into deep learning models for multi-camera perception tasks. As viewformer-exploring-spatiotemporal-modeling-multi-view-3d and duospacenet-leveraging-both-birds-eye-view-perspective have also shown, exploring novel neural network architectures that can effectively leverage multi-view and 3D information is a promising direction for advancing the state-of-the-art in scaling-multi-camera-3d-object-detection-through computer vision and robotics applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RayFormer: Improving Query-Based Multi-Camera 3D Object Detection via Ray-Centric Strategies
Xiaomeng Chu, Jiajun Deng, Guoliang You, Yifan Duan, Yao Li, Yanyong Zhang
The recent advances in query-based multi-camera 3D object detection are featured by initializing object queries in the 3D space, and then sampling features from perspective-view images to perform multi-round query refinement. In such a framework, query points near the same camera ray are likely to sample similar features from very close pixels, resulting in ambiguous query features and degraded detection accuracy. To this end, we introduce RayFormer, a camera-ray-inspired query-based 3D object detector that aligns the initialization and feature extraction of object queries with the optical characteristics of cameras. Specifically, RayFormer transforms perspective-view image features into bird's eye view (BEV) via the lift-splat-shoot method and segments the BEV map to sectors based on the camera rays. Object queries are uniformly and sparsely initialized along each camera ray, facilitating the projection of different queries onto different areas in the image to extract distinct features. Besides, we leverage the instance information of images to supplement the uniformly initialized object queries by further involving additional queries along the ray from 2D object detection boxes. To extract unique object-level features that cater to distinct queries, we design a ray sampling method that suitably organizes the distribution of feature sampling points on both images and bird's eye view. Extensive experiments are conducted on the nuScenes dataset to validate our proposed ray-inspired model design. The proposed RayFormer achieves 55.5% mAP and 63.3% NDS, respectively. Our codes will be made available.
Read more7/30/2024

0
Learning High-resolution Vector Representation from Multi-Camera Images for 3D Object Detection
Zhili Chen, Shuangjie Xu, Maosheng Ye, Zian Qian, Xiaoyi Zou, Dit-Yan Yeung, Qifeng Chen
The Bird's-Eye-View (BEV) representation is a critical factor that directly impacts the 3D object detection performance, but the traditional BEV grid representation induces quadratic computational cost as the spatial resolution grows. To address this limitation, we present a new camera-based 3D object detector with high-resolution vector representation: VectorFormer. The presented high-resolution vector representation is combined with the lower-resolution BEV representation to efficiently exploit 3D geometry from multi-camera images at a high resolution through our two novel modules: vector scattering and gathering. To this end, the learned vector representation with richer scene contexts can serve as the decoding query for final predictions. We conduct extensive experiments on the nuScenes dataset and demonstrate state-of-the-art performance in NDS and inference time. Furthermore, we investigate query-BEV-based methods incorporated with our proposed vector representation and observe a consistent performance improvement.
Read more7/23/2024
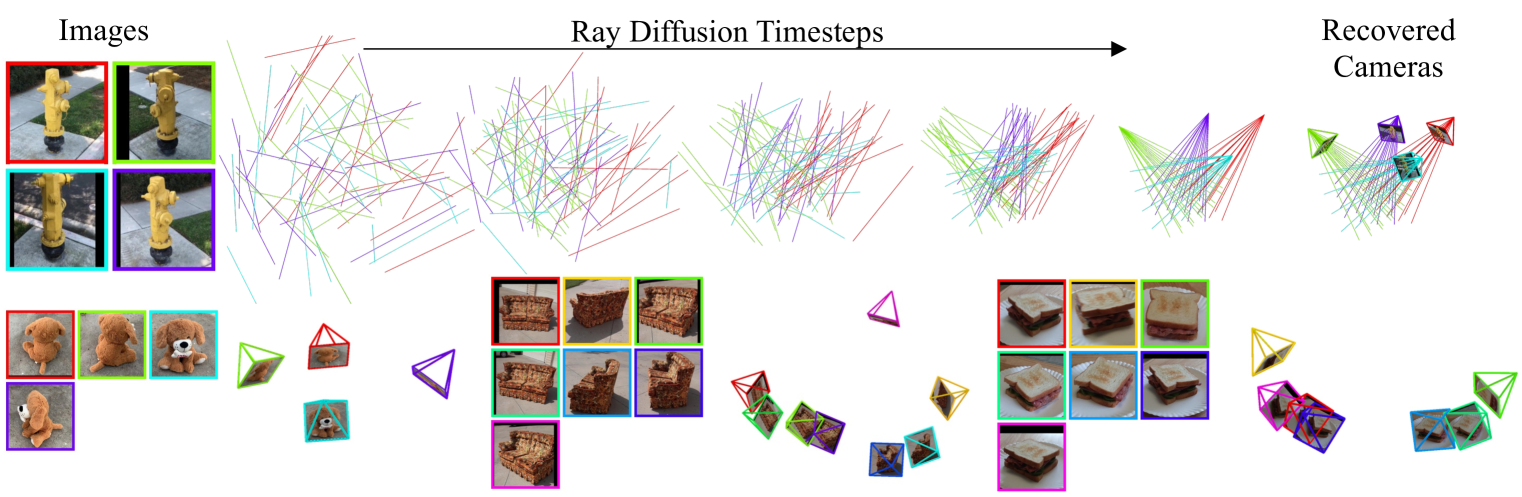
0
Cameras as Rays: Pose Estimation via Ray Diffusion
Jason Y. Zhang, Amy Lin, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, Shubham Tulsiani
Estimating camera poses is a fundamental task for 3D reconstruction and remains challenging given sparsely sampled views (<10). In contrast to existing approaches that pursue top-down prediction of global parametrizations of camera extrinsics, we propose a distributed representation of camera pose that treats a camera as a bundle of rays. This representation allows for a tight coupling with spatial image features improving pose precision. We observe that this representation is naturally suited for set-level transformers and develop a regression-based approach that maps image patches to corresponding rays. To capture the inherent uncertainties in sparse-view pose inference, we adapt this approach to learn a denoising diffusion model which allows us to sample plausible modes while improving performance. Our proposed methods, both regression- and diffusion-based, demonstrate state-of-the-art performance on camera pose estimation on CO3D while generalizing to unseen object categories and in-the-wild captures.
Read more4/5/2024

0
Mesh-based Object Tracking for Dynamic Semantic 3D Scene Graphs via Ray Tracing
Lennart Niecksch, Alexander Mock, Felix Igelbrink, Thomas Wiemann, Joachim Hertzberg
In this paper, we present a novel method for 3D geometric scene graph generation using range sensors and RGB cameras. We initially detect instance-wise keypoints with a YOLOv8s model to compute 6D pose estimates of known objects by solving PnP. We use a ray tracing approach to track a geometric scene graph consisting of mesh models of object instances. In contrast to classical point-to-point matching, this leads to more robust results, especially under occlusions between objects instances. We show that using this hybrid strategy leads to robust self-localization, pre-segmentation of the range sensor data and accurate pose tracking of objects using the same environmental representation. All detected objects are integrated into a semantic scene graph. This scene graph then serves as a front end to a semantic mapping framework to allow spatial reasoning.
Read more8/12/2024