RDRec: Rationale Distillation for LLM-based Recommendation
2405.10587
0
0
🌀
Abstract
Large language model (LLM)-based recommender models that bridge users and items through textual prompts for effective semantic reasoning have gained considerable attention. However, few methods consider the underlying rationales behind interactions, such as user preferences and item attributes, limiting the reasoning capability of LLMs for recommendations. This paper proposes a rationale distillation recommender (RDRec), a compact model designed to learn rationales generated by a larger language model (LM). By leveraging rationales from reviews related to users and items, RDRec remarkably specifies their profiles for recommendations. Experiments show that RDRec achieves state-of-the-art (SOTA) performance in both top-N and sequential recommendations. Our source code is released at https://github.com/WangXFng/RDRec.
Create account to get full access
Overview
- This paper proposes a new recommender system model called Rationale Distillation Recommender (RDRec) that leverages textual rationales to improve the reasoning capabilities of large language models (LLMs) for making recommendations.
- Traditional recommender systems often struggle to capture the underlying reasons behind user-item interactions, limiting the effectiveness of LLM-based models.
- RDRec aims to address this limitation by distilling rationales from a larger language model to better understand user preferences and item attributes, leading to more accurate recommendations.
Plain English Explanation
Rationale Distillation Recommender (RDRec) is a new type of recommender system that uses the power of large language models (LLMs) to make better recommendations. Traditional recommender systems can struggle to understand why users like or dislike certain items, which limits their ability to make good suggestions. RDRec tries to overcome this by learning the "rationales" or reasons behind user-item interactions from a larger language model. By understanding these rationales, RDRec can build more detailed profiles of users and items, leading to more accurate recommendations.
For example, imagine you're looking for a new book to read. A traditional recommender system might suggest books based on your past reading history or what other users with similar tastes have liked. But RDRec would also consider the reasons why you enjoyed certain books in the past, such as the writing style, the themes explored, or the characters. By understanding these rationales, RDRec can make more personalized recommendations that better match your preferences.
Overall, the key idea behind RDRec is to leverage the rich textual information available, such as reviews, to build a more comprehensive understanding of users and items, leading to better recommendations. This approach has been shown to outperform other state-of-the-art recommender systems in both top-N and sequential recommendations.
Technical Explanation
The paper proposes the Rationale Distillation Recommender (RDRec), a novel recommender system model that aims to bridge users and items through textual prompts for effective semantic reasoning. Unlike traditional recommender systems, RDRec focuses on learning the underlying rationales behind user-item interactions, such as user preferences and item attributes, to enhance the reasoning capabilities of large language models (LLMs) for making recommendations.
The key innovation of RDRec is its ability to distill rationales from a larger language model and incorporate them into a compact model for recommendations. By leveraging the rationales generated by the larger language model, RDRec can better specify the profiles of users and items, leading to more accurate and personalized recommendations.
The authors conduct extensive experiments to evaluate the performance of RDRec, demonstrating that it achieves state-of-the-art (SOTA) results in both top-N and sequential recommendation tasks. The paper also discusses the process of distilling algorithmic reasoning from LLMs and the potential implications of this approach for the field of recommender systems.
Critical Analysis
The paper presents a well-designed and empirically validated approach to improving recommender systems by leveraging the reasoning capabilities of large language models. The authors' focus on learning the underlying rationales behind user-item interactions is a novel and promising direction for enhancing the performance of LLM-based recommender models.
One potential limitation of the RDRec approach is the reliance on textual data, such as reviews, to derive the necessary rationales. In scenarios where such textual information is scarce or unavailable, the effectiveness of RDRec may be diminished. The authors could explore ways to incorporate other types of data, such as user demographics or item metadata, to further improve the model's performance.
Additionally, the paper does not delve deeply into the interpretability of the rationales learned by RDRec. Understanding the specific reasons behind the model's recommendations could be valuable for users, especially in sensitive domains like healthcare or finance. Future research could investigate methods to explain the algorithmic reasoning behind RDRec's recommendations in a more transparent manner.
Overall, the RDRec model represents an exciting advancement in the field of recommender systems, highlighting the potential of leveraging textual rationales to enhance the reasoning capabilities of large language models. The authors' work opens up new avenues for further research and development in this area.
Conclusion
The Rationale Distillation Recommender (RDRec) proposed in this paper offers a novel approach to improving the performance of large language model-based recommender systems. By distilling rationales from a larger language model and incorporating them into a compact model, RDRec is able to better understand the underlying reasons behind user-item interactions, leading to more accurate and personalized recommendations.
The paper's findings demonstrate the effectiveness of RDRec in both top-N and sequential recommendation tasks, suggesting that this approach could have significant implications for the field of recommender systems. As language models continue to advance and textual data becomes more widely available, the ability to leverage rationales for effective semantic reasoning will likely become increasingly important for building intelligent and user-centric recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
QCRD: Quality-guided Contrastive Rationale Distillation for Large Language Models
Wei Wang, Zhaowei Li, Qi Xu, Yiqing Cai, Hang Song, Qi Qi, Ran Zhou, Zhida Huang, Tao Wang, Li Xiao
0
0
Deploying large language models (LLMs) poses challenges in terms of resource limitations and inference efficiency. To address these challenges, recent research has focused on using smaller task-specific language models, which are enhanced by distilling the knowledge rationales generated by LLMs. However, previous works mostly emphasize the effectiveness of positive knowledge, while overlooking the knowledge noise and the exploration of negative knowledge. In this paper, we first propose a general approach called quality-guided contrastive rationale distillation for reasoning capacity learning, considering contrastive learning perspectives. For the learning of positive knowledge, we collect positive rationales through self-consistency to denoise the LLM rationales generated by temperature sampling. For the negative knowledge distillation, we generate negative rationales using temperature sampling for the iteration-before smaller language models themselves. Finally, a contrastive loss is designed to better distill the positive and negative rationales into the smaller language model, where an online-update discriminator is used to judge the qualities of rationales and assign weights for better optimizing the training process. Through extensive experiments on multiple reasoning tasks, we demonstrate that our method consistently outperforms the previous distillation methods and produces higher-quality rationales.
5/24/2024
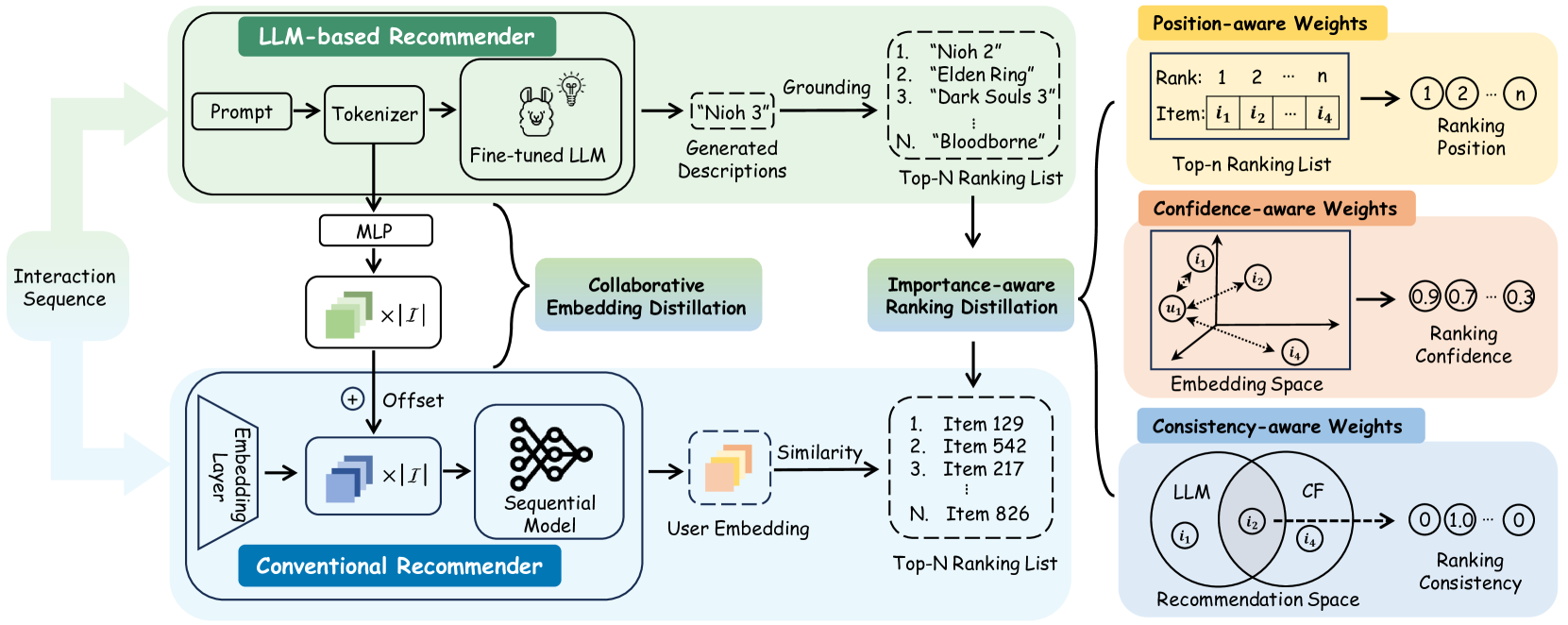
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, Jiawei Chen
0
0
Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
5/6/2024
🤔
Efficient End-to-End Visual Document Understanding with Rationale Distillation
Wang Zhu, Alekh Agarwal, Mandar Joshi, Robin Jia, Jesse Thomason, Kristina Toutanova
0
0
Understanding visually situated language requires interpreting complex layouts of textual and visual elements. Pre-processing tools, such as optical character recognition (OCR), can map document image inputs to textual tokens, then large language models (LLMs) can reason over text. However, such methods have high computational and engineering complexity. Can small pretrained image-to-text models accurately understand visual documents through similar recognition and reasoning steps instead? We propose Rationale Distillation (RD), which incorporates the outputs of OCR tools, LLMs, and larger multimodal models as intermediate rationales, and trains a small student model to predict both rationales and answers. On three visual document understanding benchmarks representing infographics, scanned documents, and figures, our Pix2Struct (282M parameters) student model finetuned with RD outperforms the base model by 4-5% absolute accuracy with only 1% higher computational cost.
4/3/2024

DELRec: Distilling Sequential Pattern to Enhance LLM-based Recommendation
Guohao Sun, Haoyi Zhang
0
0
Sequential recommendation (SR) tasks enhance recommendation accuracy by capturing the connection between users' past interactions and their changing preferences. Conventional models often focus solely on capturing sequential patterns within the training data, neglecting the broader context and semantic information embedded in item titles from external sources. This limits their predictive power and adaptability. Recently, large language models (LLMs) have shown promise in SR tasks due to their advanced understanding capabilities and strong generalization abilities. Researchers have attempted to enhance LLMs' recommendation performance by incorporating information from SR models. However, previous approaches have encountered problems such as 1) only influencing LLMs at the result level; 2) increased complexity of LLMs recommendation methods leading to reduced interpretability; 3) incomplete understanding and utilization of SR models information by LLMs. To address these problems, we proposes a novel framework, DELRec, which aims to extract knowledge from SR models and enable LLMs to easily comprehend and utilize this supplementary information for more effective sequential recommendations. DELRec consists of two main stages: 1) SR Models Pattern Distilling, focusing on extracting behavioral patterns exhibited by SR models using soft prompts through two well-designed strategies; 2) LLMs-based Sequential Recommendation, aiming to fine-tune LLMs to effectively use the distilled auxiliary information to perform SR tasks. Extensive experimental results conducted on three real datasets validate the effectiveness of the DELRec framework.
6/19/2024