Re-Ranking Step by Step: Investigating Pre-Filtering for Re-Ranking with Large Language Models
2406.18740
0
0

Abstract
Large Language Models (LLMs) have been revolutionizing a myriad of natural language processing tasks with their diverse zero-shot capabilities. Indeed, existing work has shown that LLMs can be used to great effect for many tasks, such as information retrieval (IR), and passage ranking. However, current state-of-the-art results heavily lean on the capabilities of the LLM being used. Currently, proprietary, and very large LLMs such as GPT-4 are the highest performing passage re-rankers. Hence, users without the resources to leverage top of the line LLMs, or ones that are closed source, are at a disadvantage. In this paper, we investigate the use of a pre-filtering step before passage re-ranking in IR. Our experiments show that by using a small number of human generated relevance scores, coupled with LLM relevance scoring, it is effectively possible to filter out irrelevant passages before re-ranking. Our experiments also show that this pre-filtering then allows the LLM to perform significantly better at the re-ranking task. Indeed, our results show that smaller models such as Mixtral can become competitive with much larger proprietary models (e.g., ChatGPT and GPT-4).
Create account to get full access
Overview
- This paper investigates the use of pre-filtering techniques to improve the performance of large language models (LLMs) in re-ranking tasks.
- The authors explore different pre-filtering approaches to reduce the search space for LLM-based re-ranking, aiming to enhance efficiency and effectiveness.
- The paper presents experiments on benchmark datasets for product search and web search, evaluating the impact of pre-filtering on the performance of LLM-based re-ranking.
Plain English Explanation
When using large language models (LLMs) for tasks like product search or web search, the models need to consider a large number of potential results. This can be computationally expensive and time-consuming. The authors of this paper investigated ways to "pre-filter" the results, reducing the number of options the LLM has to consider.
By applying various pre-filtering techniques, such as using keyword matching or consolidating ranking predictions from multiple models, the researchers aimed to make the LLM-based re-ranking process more efficient. The goal was to maintain or even improve the overall performance of the search system, while reducing the computational load on the LLM.
The paper presents experiments on standard datasets for product search and web search, comparing the performance of LLM-based re-ranking with and without the pre-filtering steps. The results show that the pre-filtering techniques can indeed help improve the efficiency and effectiveness of the LLM-based re-ranking, providing insights for future research and real-world applications.
Technical Explanation
The paper explores the use of pre-filtering techniques to enhance the performance of large language models (LLMs) in re-ranking tasks. The authors investigate various pre-filtering approaches to reduce the search space for the LLM-based re-ranking, with the goal of improving both efficiency and effectiveness.
The proposed pre-filtering methods include techniques such as using keyword matching to select relevant documents, consolidating ranking predictions from multiple models, and two-stage adaptation of LLMs for specific tasks. These pre-filtering steps aim to narrow down the candidate set that the LLM-based re-ranking algorithm needs to consider, potentially improving the overall performance of the search system.
The authors evaluate the impact of these pre-filtering techniques on benchmark datasets for product search and web search. They compare the performance of LLM-based re-ranking with and without the pre-filtering steps, measuring metrics such as Normalized Discounted Cumulative Gain (NDCG) and Precision@k.
The results demonstrate that the pre-filtering approaches can indeed enhance the efficiency and effectiveness of the LLM-based re-ranking, offering insights for future research and practical applications in search and information retrieval.
Critical Analysis
The paper provides a thorough investigation into the use of pre-filtering techniques to improve the performance of large language models (LLMs) in re-ranking tasks. The authors acknowledge that LLMs can be computationally expensive when applied to large search spaces, and their exploration of pre-filtering methods is a reasonable approach to address this challenge.
One potential limitation of the study is the reliance on specific benchmark datasets for product search and web search. While these datasets are commonly used in the field, the generalizability of the findings to other domains or real-world scenarios may be limited. Additionally, the paper does not provide a comprehensive analysis of the trade-offs between the pre-filtering approaches, such as the impact on result diversity or the potential for introducing bias.
Further research could explore the performance of these pre-filtering techniques on a broader range of datasets and tasks, as well as investigate the impact on recommendation diversity when using LLMs in re-ranking. Additionally, a deeper analysis of the computational efficiency and scalability of the proposed methods would help assess their practical applicability in real-world search and recommendation systems.
Conclusion
This paper presents a valuable contribution to the understanding of how pre-filtering techniques can be leveraged to improve the performance of large language models (LLMs) in re-ranking tasks. The authors demonstrate that by applying various pre-filtering approaches, such as keyword matching, model consolidation, and two-stage adaptation, the efficiency and effectiveness of LLM-based re-ranking can be enhanced.
The findings from this research provide insights that can inform the development of more efficient and effective search and recommendation systems, particularly in domains where LLMs are employed. The insights gained can also inspire further research into the integration of pre-filtering techniques with LLMs to address the computational challenges and optimize the overall performance of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
0
0
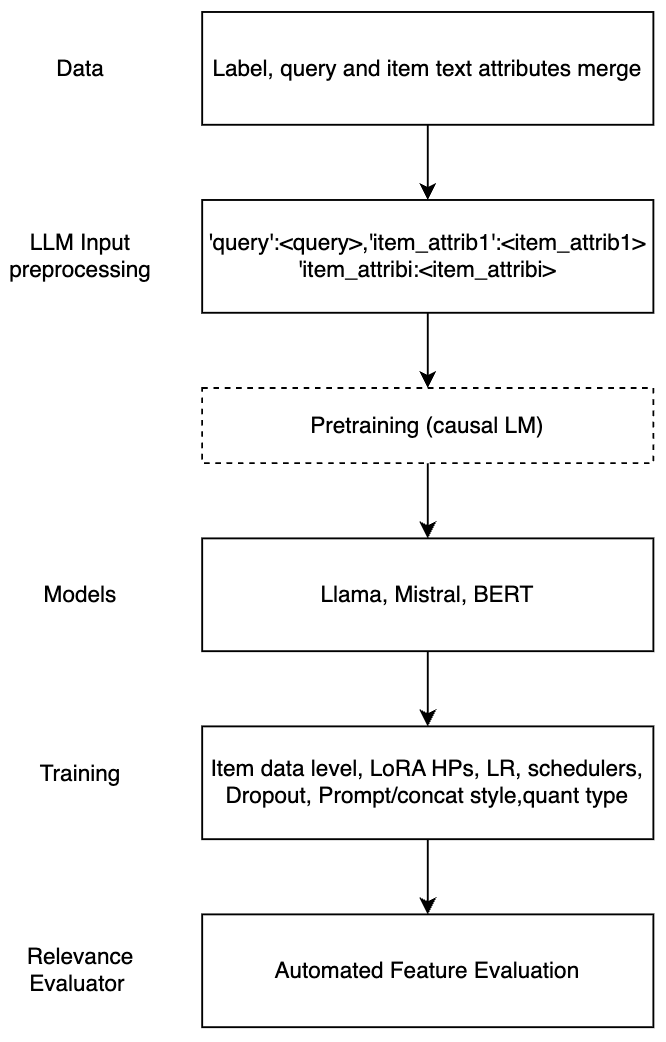
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
6/4/2024

Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing
Le Yan, Zhen Qin, Honglei Zhuang, Rolf Jagerman, Xuanhui Wang, Michael Bendersky, Harrie Oosterhuis
0
0
The powerful generative abilities of large language models (LLMs) show potential in generating relevance labels for search applications. Previous work has found that directly asking about relevancy, such as ``How relevant is document A to query Q?, results in sub-optimal ranking. Instead, the pairwise ranking prompting (PRP) approach produces promising ranking performance through asking about pairwise comparisons, e.g., ``Is document A more relevant than document B to query Q?. Thus, while LLMs are effective at their ranking ability, this is not reflected in their relevance label generation. In this work, we propose a post-processing method to consolidate the relevance labels generated by an LLM with its powerful ranking abilities. Our method takes both LLM generated relevance labels and pairwise preferences. The labels are then altered to satisfy the pairwise preferences of the LLM, while staying as close to the original values as possible. Our experimental results indicate that our approach effectively balances label accuracy and ranking performance. Thereby, our work shows it is possible to combine both the ranking and labeling abilities of LLMs through post-processing.
4/19/2024
A Two-Stage Adaptation of Large Language Models for Text Ranking
Longhui Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, Meishan Zhang, Min Zhang
0
0
Text ranking is a critical task in information retrieval. Recent advances in pre-trained language models (PLMs), especially large language models (LLMs), present new opportunities for applying them to text ranking. While supervised fine-tuning (SFT) with ranking data has been widely explored to better align PLMs with text ranking goals, previous studies have focused primarily on encoder-only and encoder-decoder PLMs. Research on leveraging decoder-only LLMs for text ranking remains scarce. An exception to this is RankLLaMA, which uses direct SFT to explore LLaMA's potential for text ranking. In this work, we propose a two-stage progressive paradigm to better adapt LLMs to text ranking. First, we conduct continual pre-training (CPT) of LLMs on a large weakly-supervised corpus. Second, we perform SFT, and propose an improved optimization strategy building upon RankLLaMA. Our experimental results on multiple benchmarks show that our approach outperforms previous methods in both in-domain and out-domain scenarios.
6/4/2024
Large Language Model-guided Document Selection
Xiang Kong, Tom Gunter, Ruoming Pang
0
0
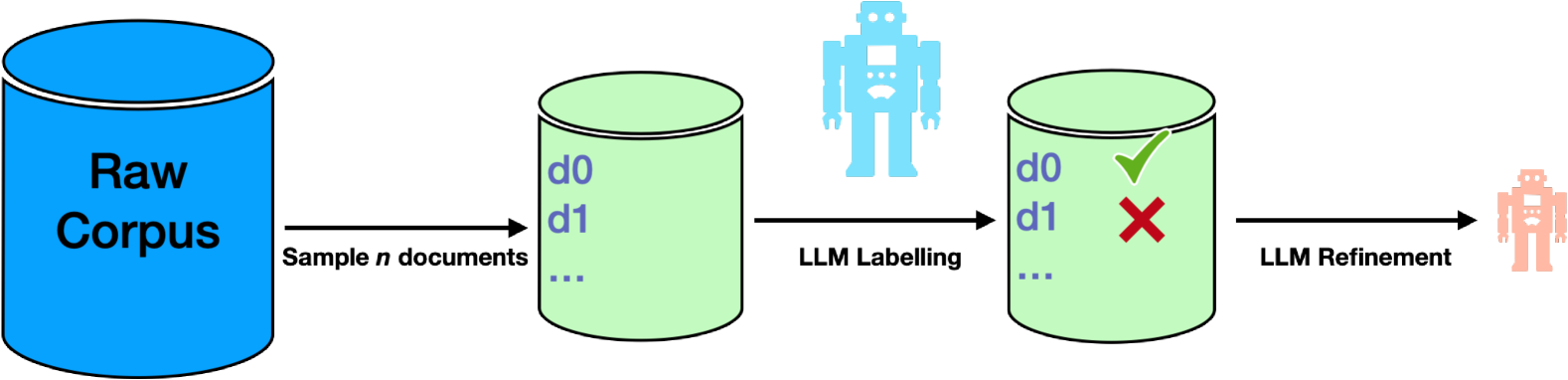
Large Language Model (LLM) pre-training exhausts an ever growing compute budget, yet recent research has demonstrated that careful document selection enables comparable model quality with only a fraction of the FLOPs. Inspired by efforts suggesting that domain-specific training document selection is in fact an interpretable process [Gunasekar et al., 2023], as well as research showing that instruction-finetuned LLMs are adept zero-shot data labelers [Gilardi et al.,2023], we explore a promising direction for scalable general-domain document selection; employing a prompted LLM as a document grader, we distill quality labels into a classifier model, which is applied at scale to a large, and already heavily-filtered, web-crawl-derived corpus autonomously. Following the guidance of this classifier, we drop 75% of the corpus and train LLMs on the remaining data. Results across multiple benchmarks show that: 1. Filtering allows us to quality-match a model trained on the full corpus across diverse benchmarks with at most 70% of the FLOPs, 2. More capable LLM labelers and classifier models lead to better results that are less sensitive to the labeler's prompt, 3. In-context learning helps to boost the performance of less-capable labeling models. In all cases we use open-source datasets, models, recipes, and evaluation frameworks, so that results can be reproduced by the community.
6/10/2024