A Two-Stage Adaptation of Large Language Models for Text Ranking
2311.16720
0
0
Abstract
Text ranking is a critical task in information retrieval. Recent advances in pre-trained language models (PLMs), especially large language models (LLMs), present new opportunities for applying them to text ranking. While supervised fine-tuning (SFT) with ranking data has been widely explored to better align PLMs with text ranking goals, previous studies have focused primarily on encoder-only and encoder-decoder PLMs. Research on leveraging decoder-only LLMs for text ranking remains scarce. An exception to this is RankLLaMA, which uses direct SFT to explore LLaMA's potential for text ranking. In this work, we propose a two-stage progressive paradigm to better adapt LLMs to text ranking. First, we conduct continual pre-training (CPT) of LLMs on a large weakly-supervised corpus. Second, we perform SFT, and propose an improved optimization strategy building upon RankLLaMA. Our experimental results on multiple benchmarks show that our approach outperforms previous methods in both in-domain and out-domain scenarios.
Create account to get full access
Overview
- This paper proposes a novel approach called "RankingGPT" to enhance the text ranking capabilities of large language models (LLMs).
- The researchers introduce a progressive enhancement framework that incrementally refines the LLM's ranking performance through fine-tuning on specific datasets and tasks.
- The goal is to create a versatile and robust text ranking model that can perform well across a variety of domains and applications.
Plain English Explanation
The researchers have developed a new way to improve the ability of large language models (LLMs) to rank and organize text data. LLMs are powerful AI systems that can understand and generate human-like text, but they don't always excel at specific tasks like ranking or sorting text.
The key idea behind RankingGPT is a "progressive enhancement" approach. This means the researchers start with a basic LLM and then fine-tune or customize it, step-by-step, to become better at text ranking. They do this by training the model on different datasets and tasks related to ranking, gradually improving its capabilities.
The goal is to create a versatile LLM-based text ranking system that works well across many different domains and applications. This could be useful for all kinds of real-world tasks, like organizing search results, translating content between languages, or boosting the translation abilities of LLMs.
Technical Explanation
The researchers propose a progressive enhancement framework for improving the text ranking capabilities of large language models (LLMs). This involves a series of fine-tuning steps, where the LLM is trained on increasingly specialized datasets and tasks related to text ranking.
The process starts with a base LLM, which is then fine-tuned on a general text ranking task using a large, diverse dataset. This establishes a strong foundation for ranking performance. Next, the model is further fine-tuned on more specialized datasets and tasks, such as preference learning or budget-constrained re-ranking.
Through this incremental refinement, the LLM gradually develops more nuanced and robust text ranking abilities. The researchers demonstrate the effectiveness of this approach through extensive experiments, showing that RankingGPT outperforms standard LLM-based ranking methods across a variety of benchmark datasets and tasks.
Critical Analysis
The progressive enhancement framework proposed in this paper is a clever and systematic way to enhance the text ranking capabilities of large language models. By breaking down the training process into incremental steps, the researchers are able to steadily improve the model's performance without sacrificing too much generalization.
However, the paper does acknowledge some potential limitations. For example, the fine-tuning process can be computationally expensive, and the model may struggle to adapt to completely novel domains or tasks that are substantially different from the ones it was trained on. Additionally, the researchers note that further research is needed to understand the transferability of the learned ranking capabilities across different LLM architectures and domains.
It would also be valuable to see more analysis on the model's robustness to noisy or adversarial inputs, as well as its interpretability and transparency in how it arrives at ranking decisions. These are important considerations for real-world deployment of such systems.
Overall, the RankingGPT approach represents a promising step forward in enhancing the text ranking abilities of large language models. The researchers have demonstrated the potential of progressive enhancement, and further refinements and evaluations could lead to even more powerful and versatile text ranking solutions.
Conclusion
The RankingGPT paper presents a novel framework for improving the text ranking capabilities of large language models through a progressive enhancement approach. By fine-tuning the LLM on increasingly specialized datasets and tasks, the researchers are able to steadily enhance the model's ranking performance across a variety of domains.
This work has important implications for a wide range of applications that rely on effective text ranking, from personalized search to cross-lingual content understanding. The progressive enhancement strategy could also be applied to other specialized tasks, helping to transform powerful language models into more versatile and capable AI assistants.
While the paper highlights some potential limitations, the RankingGPT approach represents a significant step forward in empowering large language models to excel at text ranking. Continued research and refinement in this area could lead to even more advanced and practical solutions for organizing and understanding large volumes of textual data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024

A Practice-Friendly Two-Stage LLM-Enhanced Paradigm in Sequential Recommendation
Dugang Liu, Shenxian Xian, Xiaolin Lin, Xiaolian Zhang, Hong Zhu, Yuan Fang, Zhen Chen, Zhong Ming
0
0
The training paradigm integrating large language models (LLM) is gradually reshaping sequential recommender systems (SRS) and has shown promising results. However, most existing LLM-enhanced methods rely on rich textual information on the item side and instance-level supervised fine-tuning (SFT) to inject collaborative information into LLM, which is inefficient and limited in many applications. To alleviate these problems, this paper proposes a novel practice-friendly two-stage LLM-enhanced paradigm (TSLRec) for SRS. Specifically, in the information reconstruction stage, we design a new user-level SFT task for collaborative information injection with the assistance of a pre-trained SRS model, which is more efficient and compatible with limited text information. We aim to let LLM try to infer the latent category of each item and reconstruct the corresponding user's preference distribution for all categories from the user's interaction sequence. In the information augmentation stage, we feed each item into LLM to obtain a set of enhanced embeddings that combine collaborative information and LLM inference capabilities. These embeddings can then be used to help train various future SRS models. Finally, we verify the effectiveness and efficiency of our TSLRec on three SRS benchmark datasets.
6/4/2024
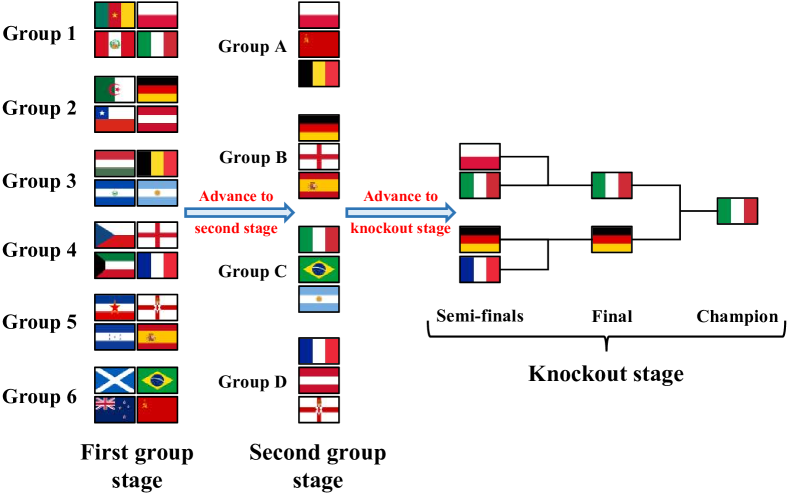
TourRank: Utilizing Large Language Models for Documents Ranking with a Tournament-Inspired Strategy
Yiqun Chen, Qi Liu, Yi Zhang, Weiwei Sun, Daiting Shi, Jiaxin Mao, Dawei Yin
0
0
Large Language Models (LLMs) are increasingly employed in zero-shot documents ranking, yielding commendable results. However, several significant challenges still persist in LLMs for ranking: (1) LLMs are constrained by limited input length, precluding them from processing a large number of documents simultaneously; (2) The output document sequence is influenced by the input order of documents, resulting in inconsistent ranking outcomes; (3) Achieving a balance between cost and ranking performance is quite challenging. To tackle these issues, we introduce a novel documents ranking method called TourRank, which is inspired by the tournament mechanism. This approach alleviates the impact of LLM's limited input length through intelligent grouping, while the tournament-like points system ensures robust ranking, mitigating the influence of the document input sequence. We test TourRank with different LLMs on the TREC DL datasets and the BEIR benchmark. Experimental results show that TourRank achieves state-of-the-art performance at a reasonable cost.
6/18/2024

New!Re-Ranking Step by Step: Investigating Pre-Filtering for Re-Ranking with Large Language Models
Baharan Nouriinanloo, Maxime Lamothe
0
0
Large Language Models (LLMs) have been revolutionizing a myriad of natural language processing tasks with their diverse zero-shot capabilities. Indeed, existing work has shown that LLMs can be used to great effect for many tasks, such as information retrieval (IR), and passage ranking. However, current state-of-the-art results heavily lean on the capabilities of the LLM being used. Currently, proprietary, and very large LLMs such as GPT-4 are the highest performing passage re-rankers. Hence, users without the resources to leverage top of the line LLMs, or ones that are closed source, are at a disadvantage. In this paper, we investigate the use of a pre-filtering step before passage re-ranking in IR. Our experiments show that by using a small number of human generated relevance scores, coupled with LLM relevance scoring, it is effectively possible to filter out irrelevant passages before re-ranking. Our experiments also show that this pre-filtering then allows the LLM to perform significantly better at the re-ranking task. Indeed, our results show that smaller models such as Mixtral can become competitive with much larger proprietary models (e.g., ChatGPT and GPT-4).
6/28/2024