Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing
2404.11791
0
0

Abstract
The powerful generative abilities of large language models (LLMs) show potential in generating relevance labels for search applications. Previous work has found that directly asking about relevancy, such as How relevant is document A to query Q?, results in sub-optimal ranking. Instead, the pairwise ranking prompting (PRP) approach produces promising ranking performance through asking about pairwise comparisons, e.g., Is document A more relevant than document B to query Q?. Thus, while LLMs are effective at their ranking ability, this is not reflected in their relevance label generation. In this work, we propose a post-processing method to consolidate the relevance labels generated by an LLM with its powerful ranking abilities. Our method takes both LLM generated relevance labels and pairwise preferences. The labels are then altered to satisfy the pairwise preferences of the LLM, while staying as close to the original values as possible. Our experimental results indicate that our approach effectively balances label accuracy and ranking performance. Thereby, our work shows it is possible to combine both the ranking and labeling abilities of LLMs through post-processing.
Create account to get full access
Overview
- This paper explores a technique for consolidating the ranking and relevance predictions of large language models through post-processing.
- The authors propose a novel approach to improve the performance of large language models in tasks like information retrieval and text generation.
- The technique involves adjusting the model's output to better align with human judgments of relevance and ranking, potentially enhancing the model's real-world applicability.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have shown impressive capabilities in a variety of natural language processing tasks. However, their outputs don't always match human perceptions of relevance and ranking.
For example, an LLM might generate a response that's technically correct but not the most useful or appropriate for a given context. This paper introduces a post-processing technique to address this issue.
The key idea is to adjust the model's output in a way that better aligns with human judgments. This could involve:
- Boosting the scores of responses that are more relevant or higher-ranking
- Reducing the scores of responses that are less relevant or lower-ranking
- Recalibrating the model's confidence levels to match human expectations
By applying this post-processing step, the authors aim to consolidate the model's predictions and make them more useful in real-world applications like information retrieval and text generation.
Technical Explanation
The paper proposes a post-processing approach to improve the ranking and relevance predictions of large language models. The key steps are:
- Data Collection: The authors collect a dataset of human judgments on the relevance and ranking of model outputs for various natural language tasks.
- Model Training: They train a separate model to predict human judgments based on the features of the original model's outputs.
- Post-Processing: When applying the LLM to new inputs, the authors use the trained model to adjust the original outputs, boosting or reducing their scores to better match human perceptions of relevance and ranking.
The authors evaluate their approach on several benchmark datasets, comparing the performance of the original LLM to the post-processed version. They find that the post-processing step consistently improves the model's ability to generate relevant and high-ranking responses, as judged by human raters.
Critical Analysis
The paper presents a promising approach to address a key challenge in the deployment of large language models - the mismatch between model outputs and human judgments of relevance and ranking. By incorporating a post-processing step, the authors aim to make LLM predictions more useful and trustworthy in real-world applications.
However, the paper does not fully address the potential limitations of this approach. For example, the post-processing model may not generalize well to new domains or tasks, and the approach relies on the availability of high-quality human judgment data, which can be costly to obtain.
Additionally, the paper does not discuss the potential ethical implications of this technique, such as the risk of further entrenching human biases in the model's outputs or the potential for abuse in the context of information retrieval or text generation.
Conclusion
This paper presents a novel approach to consolidate the ranking and relevance predictions of large language models through post-processing. By adjusting the model's outputs to better align with human judgments, the authors aim to improve the real-world usefulness and trustworthiness of LLM predictions.
The technique shows promise in addressing a key challenge in deploying large language models, but further research is needed to address its limitations and potential ethical implications. As LLMs continue to advance, techniques like this one may play an important role in bridging the gap between model capabilities and human preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
0
0
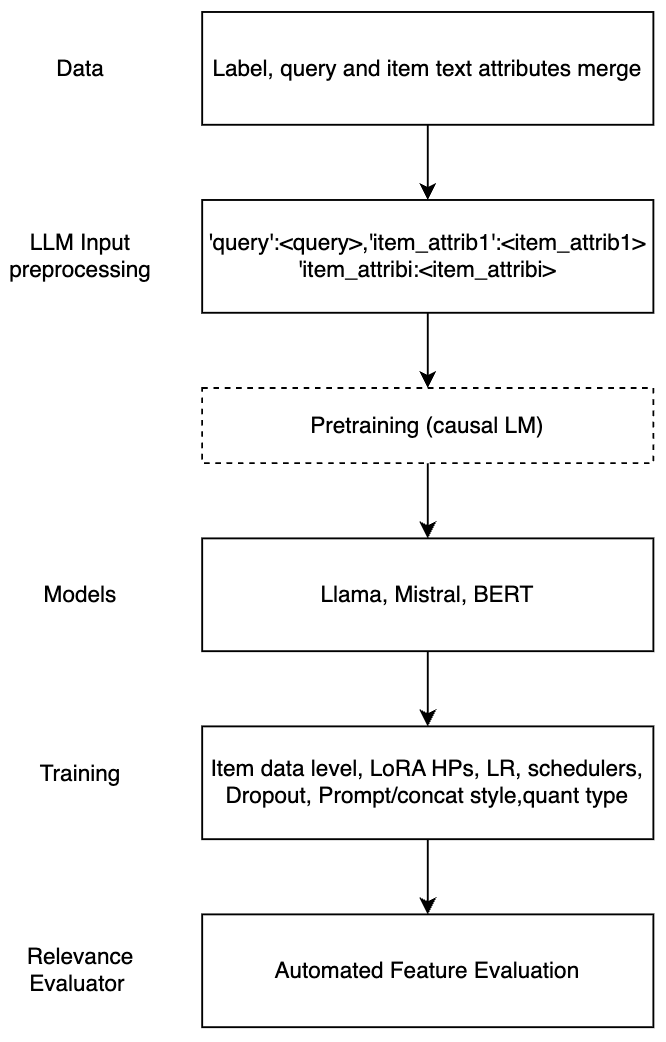
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
6/4/2024

Re-Ranking Step by Step: Investigating Pre-Filtering for Re-Ranking with Large Language Models
Baharan Nouriinanloo, Maxime Lamothe
0
0
Large Language Models (LLMs) have been revolutionizing a myriad of natural language processing tasks with their diverse zero-shot capabilities. Indeed, existing work has shown that LLMs can be used to great effect for many tasks, such as information retrieval (IR), and passage ranking. However, current state-of-the-art results heavily lean on the capabilities of the LLM being used. Currently, proprietary, and very large LLMs such as GPT-4 are the highest performing passage re-rankers. Hence, users without the resources to leverage top of the line LLMs, or ones that are closed source, are at a disadvantage. In this paper, we investigate the use of a pre-filtering step before passage re-ranking in IR. Our experiments show that by using a small number of human generated relevance scores, coupled with LLM relevance scoring, it is effectively possible to filter out irrelevant passages before re-ranking. Our experiments also show that this pre-filtering then allows the LLM to perform significantly better at the re-ranking task. Indeed, our results show that smaller models such as Mixtral can become competitive with much larger proprietary models (e.g., ChatGPT and GPT-4).
6/28/2024
Query Performance Prediction using Relevance Judgments Generated by Large Language Models
Chuan Meng, Negar Arabzadeh, Arian Askari, Mohammad Aliannejadi, Maarten de Rijke
0
0
Query performance prediction (QPP) aims to estimate the retrieval quality of a search system for a query without human relevance judgments. Previous QPP methods typically return a single scalar value and do not require the predicted values to approximate a specific information retrieval (IR) evaluation measure, leading to certain drawbacks: (i) a single scalar is insufficient to accurately represent different IR evaluation measures, especially when metrics do not highly correlate, and (ii) a single scalar limits the interpretability of QPP methods because solely using a scalar is insufficient to explain QPP results. To address these issues, we propose a QPP framework using automatically generated relevance judgments (QPP-GenRE), which decomposes QPP into independent subtasks of predicting the relevance of each item in a ranked list to a given query. This allows us to predict any IR evaluation measure using the generated relevance judgments as pseudo-labels. This also allows us to interpret predicted IR evaluation measures, and identify, track and rectify errors in generated relevance judgments to improve QPP quality. We predict an item's relevance by using open-source large language models (LLMs) to ensure scientific reproducibility. We face two main challenges: (i) excessive computational costs of judging an entire corpus for predicting a metric considering recall, and (ii) limited performance in prompting open-source LLMs in a zero-/few-shot manner. To solve the challenges, we devise an approximation strategy to predict an IR measure considering recall and propose to fine-tune open-source LLMs using human-labeled relevance judgments. Experiments on the TREC 2019-2022 deep learning tracks show that QPP-GenRE achieves state-of-the-art QPP quality for both lexical and neural rankers.
6/18/2024
💬
Prediction-Powered Ranking of Large Language Models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, Manuel Gomez Rodriguez
0
0
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
5/24/2024