Reading Between the Lines: Modeling User Behavior and Costs in AI-Assisted Programming
2210.14306
2
0
📉
Abstract
Code-recommendation systems, such as Copilot and CodeWhisperer, have the potential to improve programmer productivity by suggesting and auto-completing code. However, to fully realize their potential, we must understand how programmers interact with these systems and identify ways to improve that interaction. To seek insights about human-AI collaboration with code recommendations systems, we studied GitHub Copilot, a code-recommendation system used by millions of programmers daily. We developed CUPS, a taxonomy of common programmer activities when interacting with Copilot. Our study of 21 programmers, who completed coding tasks and retrospectively labeled their sessions with CUPS, showed that CUPS can help us understand how programmers interact with code-recommendation systems, revealing inefficiencies and time costs. Our insights reveal how programmers interact with Copilot and motivate new interface designs and metrics.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers studied how programmers interact with code-recommendation systems, like GitHub Copilot, to understand how to improve these systems.
- They developed a taxonomy called CUPS to categorize common programmer activities when using Copilot.
- Their study of 21 programmers showed that CUPS can reveal inefficiencies and time costs in how programmers use Copilot, providing insights to inform better interface designs and metrics.
Plain English Explanation
Code-recommendation systems, such as GitHub Copilot and CodeWhisperer, have the potential to boost programmer productivity by suggesting and auto-completing code. However, to fully realize this potential, we need to understand how programmers actually interact with these systems.
The researchers in this study looked closely at how programmers use GitHub Copilot, a popular code-recommendation system used by millions daily. They developed a framework called CUPS to categorize the common activities programmers engage in when working with Copilot. By observing 21 programmers completing coding tasks and having them label their sessions using CUPS, the researchers gained insights into the inefficiencies and time costs of how programmers currently interact with Copilot.
These insights can inspire new interface designs and metrics to improve the human-AI collaboration between programmers and code-recommendation systems. For example, the study could lead to Copilot updates that streamline the most common programmer activities or provide better feedback on when Copilot's suggestions are most valuable.
Technical Explanation
The researchers conducted a qualitative study to understand how programmers interact with the code-recommendation system, GitHub Copilot. They developed a taxonomy called CUPS (Create, Understand, Pause, and Scan) to categorize the common activities programmers engage in when using Copilot.
To gather data, the researchers had 21 programmers complete coding tasks while using Copilot. After each session, the participants retrospectively labeled their activities using the CUPS taxonomy. The researchers then analyzed the labeled sessions to gain insights into how programmers interact with Copilot.
The study revealed several key findings:
- Programmers spent significant time Scanning Copilot's suggestions, but often did not Create code based on those suggestions.
- There were frequent Pauses in the coding process as programmers evaluated Copilot's suggestions, indicating potential inefficiencies.
- Programmers had difficulty Understanding how Copilot generated its suggestions, limiting their ability to fully leverage the system.
These insights suggest opportunities to improve the design of code-recommendation systems and the metrics used to evaluate their performance. For example, interfaces could be designed to better highlight when Copilot's suggestions are most valuable, or feedback could be provided to help programmers understand the system's reasoning.
Critical Analysis
The researchers provide a thorough and thoughtful analysis of how programmers interact with the GitHub Copilot code-recommendation system. The CUPS taxonomy they developed seems like a useful framework for categorizing common programmer activities and identifying areas for improvement.
One potential limitation of the study is the relatively small sample size of 21 programmers. While the qualitative insights are valuable, a larger-scale study could provide more robust and generalizable findings. Additionally, the researchers only looked at Copilot usage within the context of specific coding tasks, so the findings may not fully capture how programmers use the system in their day-to-day work.
Further research could also explore the potential for code-recommendation systems to inadvertently leak sensitive information or how well these systems perform on more complex real-world programming tasks. Addressing these kinds of concerns will be crucial as code-recommendation systems become more widely adopted.
Overall, this study provides valuable insights that can inform the design and evaluation of future code-recommendation systems, helping to unlock their full potential to improve programmer productivity and collaboration.
Conclusion
This research offers important insights into how programmers interact with code-recommendation systems like GitHub Copilot. By developing a taxonomy of common programmer activities and observing real users, the researchers were able to identify inefficiencies and time costs in the current user experience.
These findings can guide the design of better interfaces and metrics for evaluating the performance of code-recommendation systems. As these AI-powered tools become more prevalent, it will be crucial to ensure they seamlessly integrate with programmers' existing workflows and decision-making processes.
Overall, this study highlights the value of studying human-AI collaboration in the context of software development. Continuing to explore these interactions will be key to unlocking the full potential of code-recommendation systems and other AI-powered tools for programmers.
Related Papers
💬
When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming
Hussein Mozannar, Gagan Bansal, Adam Fourney, Eric Horvitz
0
0
AI powered code-recommendation systems, such as Copilot and CodeWhisperer, provide code suggestions inside a programmer's environment (e.g., an IDE) with the aim of improving productivity. We pursue mechanisms for leveraging signals about programmers' acceptance and rejection of code suggestions to guide recommendations. We harness data drawn from interactions with GitHub Copilot, a system used by millions of programmers, to develop interventions that can save time for programmers. We introduce a utility-theoretic framework to drive decisions about suggestions to display versus withhold. The approach, conditional suggestion display from human feedback (CDHF), relies on a cascade of models that provide the likelihood that recommended code will be accepted. These likelihoods are used to selectively hide suggestions, reducing both latency and programmer verification time. Using data from 535 programmers, we perform a retrospective evaluation of CDHF and show that we can avoid displaying a significant fraction of suggestions that would have been rejected. We further demonstrate the importance of incorporating the programmer's latent unobserved state in decisions about when to display suggestions through an ablation study. Finally, we showcase how using suggestion acceptance as a reward signal for guiding the display of suggestions can lead to suggestions of reduced quality, indicating an unexpected pitfall.
4/23/2024
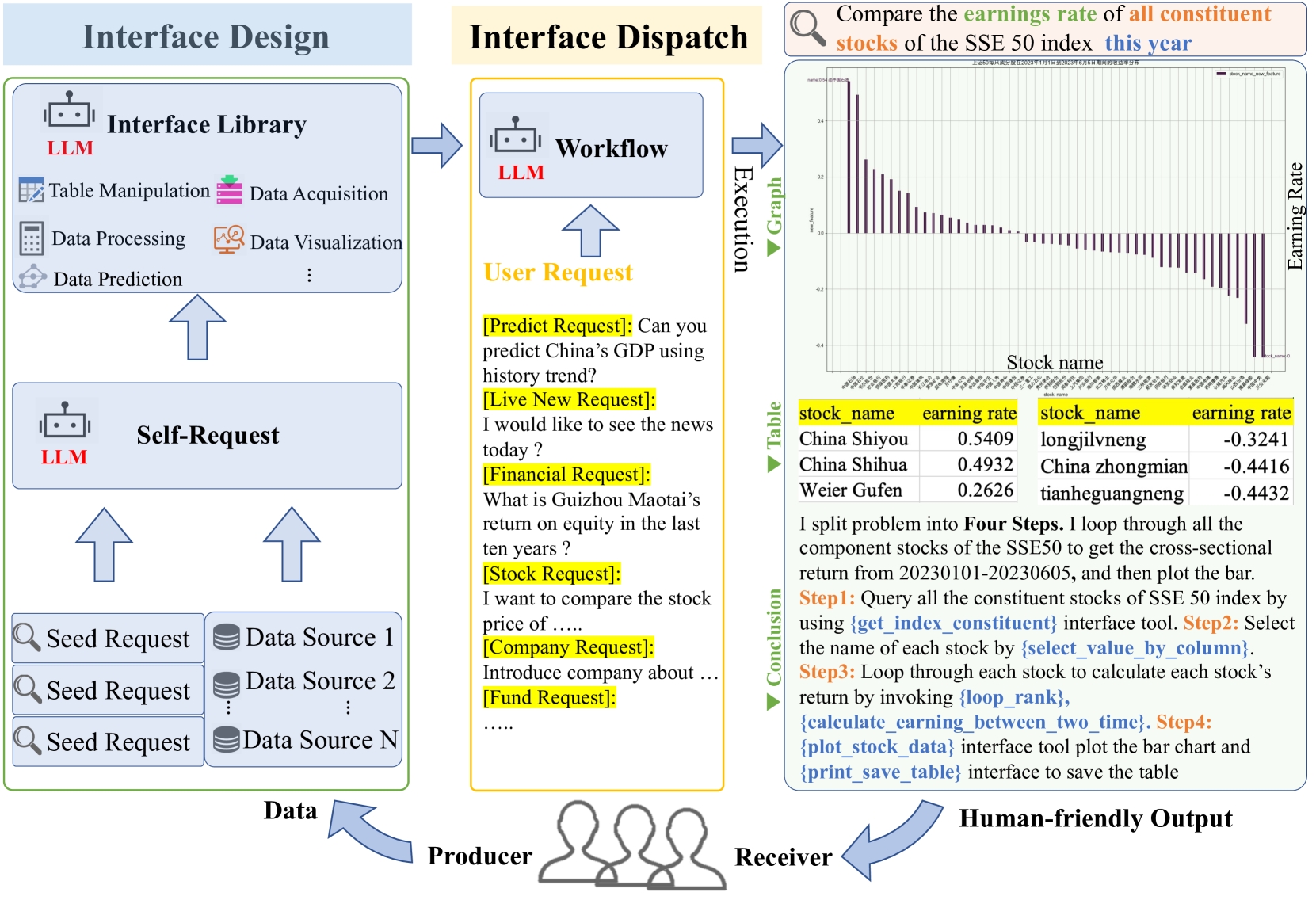
Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow
Wenqi Zhang, Yongliang Shen, Weiming Lu, Yueting Zhuang
0
0
Various industries such as finance, meteorology, and energy produce vast amounts of heterogeneous data every day. There is a natural demand for humans to manage, process, and display data efficiently. However, it necessitates labor-intensive efforts and a high level of expertise for these data-related tasks. Considering large language models (LLMs) showcase promising capabilities in semantic understanding and reasoning, we advocate that the deployment of LLMs could autonomously manage and process massive amounts of data while interacting and displaying in a human-friendly manner. Based on this, we propose Data-Copilot, an LLM-based system that connects numerous data sources on one end and caters to diverse human demands on the other end. Acting as an experienced expert, Data-Copilot autonomously transforms raw data into multi-form output that best matches the user's intent. Specifically, it first designs multiple universal interfaces to satisfy diverse data-related requests, like querying, analysis, prediction, and visualization. In real-time response, it automatically deploys a concise workflow by invoking corresponding interfaces. The whole process is fully controlled by Data-Copilot, without human assistance. We release Data-Copilot-1.0 using massive Chinese financial data, e.g., stocks, funds, and news. Experiments indicate it achieves reliable performance with lower token consumption, showing promising application prospects.
5/8/2024
📈
Rethinking Software Engineering in the Foundation Model Era: From Task-Driven AI Copilots to Goal-Driven AI Pair Programmers
Ahmed E. Hassan (Jack), Gustavo A. Oliva (Jack), Dayi Lin (Jack), Boyuan Chen (Jack), Zhen Ming (Jack), Jiang
0
0
The advent of Foundation Models (FMs) and AI-powered copilots has transformed the landscape of software development, offering unprecedented code completion capabilities and enhancing developer productivity. However, the current task-driven nature of these copilots falls short in addressing the broader goals and complexities inherent in software engineering (SE). In this paper, we propose a paradigm shift towards goal-driven AI-powered pair programmers that collaborate with human developers in a more holistic and context-aware manner. We envision AI pair programmers that are goal-driven, human partners, SE-aware, and self-learning. These AI partners engage in iterative, conversation-driven development processes, aligning closely with human goals and facilitating informed decision-making. We discuss the desired attributes of such AI pair programmers and outline key challenges that must be addressed to realize this vision. Ultimately, our work represents a shift from AI-augmented SE to AI-transformed SE by replacing code completion with a collaborative partnership between humans and AI that enhances both productivity and software quality.
4/17/2024

CodeCloak: A Method for Evaluating and Mitigating Code Leakage by LLM Code Assistants
Amit Finkman, Eden Bar-Kochva, Avishag Shapira, Dudu Mimran, Yuval Elovici, Asaf Shabtai
0
0
LLM-based code assistants are becoming increasingly popular among developers. These tools help developers improve their coding efficiency and reduce errors by providing real-time suggestions based on the developer's codebase. While beneficial, these tools might inadvertently expose the developer's proprietary code to the code assistant service provider during the development process. In this work, we propose two complementary methods to mitigate the risk of code leakage when using LLM-based code assistants. The first is a technique for reconstructing a developer's original codebase from code segments sent to the code assistant service (i.e., prompts) during the development process, enabling assessment and evaluation of the extent of code leakage to third parties (or adversaries). The second is CodeCloak, a novel deep reinforcement learning agent that manipulates the prompts before sending them to the code assistant service. CodeCloak aims to achieve the following two contradictory goals: (i) minimizing code leakage, while (ii) preserving relevant and useful suggestions for the developer. Our evaluation, employing GitHub Copilot, StarCoder, and CodeLlama LLM-based code assistants models, demonstrates the effectiveness of our CodeCloak approach on a diverse set of code repositories of varying sizes, as well as its transferability across different models. In addition, we generate a realistic simulated coding environment to thoroughly analyze code leakage risks and evaluate the effectiveness of our proposed mitigation techniques under practical development scenarios.
4/16/2024