Real Risks of Fake Data: Synthetic Data, Diversity-Washing and Consent Circumvention
2405.01820
0
0
🏅
Abstract
Machine learning systems require representations of the real world for training and testing - they require data, and lots of it. Collecting data at scale has logistical and ethical challenges, and synthetic data promises a solution to these challenges. Instead of needing to collect photos of real people's faces to train a facial recognition system, a model creator could create and use photo-realistic, synthetic faces. The comparative ease of generating this synthetic data rather than relying on collecting data has made it a common practice. We present two key risks of using synthetic data in model development. First, we detail the high risk of false confidence when using synthetic data to increase dataset diversity and representation. We base this in the examination of a real world use-case of synthetic data, where synthetic datasets were generated for an evaluation of facial recognition technology. Second, we examine how using synthetic data risks circumventing consent for data usage. We illustrate this by considering the importance of consent to the U.S. Federal Trade Commission's regulation of data collection and affected models. Finally, we discuss how these two risks exemplify how synthetic data complicates existing governance and ethical practice; by decoupling data from those it impacts, synthetic data is prone to consolidating power away those most impacted by algorithmically-mediated harm.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Machine learning systems require large datasets to train and test models
- Collecting real-world data at scale poses logistical and ethical challenges
- Synthetic data promises to address these challenges by generating realistic, artificial data
Plain English Explanation
Machine learning models need lots of data to learn and improve. This could be things like photos of people's faces to train a facial recognition system. Collecting this real-world data can be difficult and raise ethical concerns. Instead, researchers can generate synthetic data - artificial but realistic-looking data that mimics the real thing. This can be easier than gathering huge amounts of real data.
However, the paper identifies two key risks of relying too much on synthetic data:
-
False confidence: Using synthetic data to increase dataset diversity and representation can give a false sense of how well the model will perform in the real world. The paper cites a real-world example where synthetic faces were used to test a facial recognition system, leading to overconfidence.
-
Consent issues: Synthetic data risks bypassing the need for consent from the individuals whose data is being used. But consent is important for data collection regulations, like from the FTC in the US.
These risks show how synthetic data can complicate existing ethical and governance practices around data use. By separating the data from the people it's based on, synthetic data can concentrate power away from those impacted by algorithmic systems.
Technical Explanation
The paper examines two key risks of using synthetic data in machine learning model development:
-
Risk of False Confidence: The authors detail how synthetic data can lead to overconfidence in model performance, using a real-world case study. They analyze a scenario where synthetic faces were used to evaluate facial recognition technology, finding that the synthetic dataset provided much higher performance metrics compared to testing on real faces. This highlights the risk of overfitting to synthetic data and the potential for models trained on synthetic data to underperform in the real world.
-
Risk of Circumventing Consent: The paper also explores how the use of synthetic data can bypass the need for consent from the individuals whose data is being used to train models. The authors illustrate this by considering the importance of consent in data collection regulations, such as those enforced by the U.S. Federal Trade Commission. By decoupling the data from the people it represents, synthetic data can consolidate power away from those most impacted by algorithmically-mediated harm.
The paper argues that these two risks exemplify how synthetic data can complicate existing governance and ethical practices around data use in machine learning. By creating synthetic datasets that appear more diverse and representative, researchers may gain a false sense of confidence in their models' performance. Additionally, the ease of generating synthetic data can lead to the circumvention of consent requirements, potentially concentrating power away from the people affected by the deployed models.
Critical Analysis
The paper raises important concerns about the potential risks of over-reliance on synthetic data in machine learning model development. The authors provide a compelling real-world case study to illustrate the danger of overconfidence when testing on synthetic data, which is a valuable lesson for researchers and practitioners.
However, the paper does not delve into potential mitigations or best practices for using synthetic data responsibly. While it highlights the consent and governance issues, it could have explored strategies for maintaining accountability and transparency when deploying models trained on synthetic data.
Additionally, the paper could have acknowledged the potential benefits of synthetic data, such as its ability to address data scarcity, privacy concerns, and biases in real-world datasets. A more balanced discussion of the tradeoffs could have strengthened the analysis.
Overall, the paper makes a valuable contribution by drawing attention to critical risks that the machine learning community should carefully consider as the use of synthetic data becomes more prevalent.
Conclusion
This paper highlights two key risks of overrelying on synthetic data in machine learning model development: the potential for false confidence in model performance and the ability to circumvent consent requirements for data usage.
The authors provide a compelling real-world example of how synthetic data can lead to overconfident evaluations of facial recognition technology, underscoring the danger of overfitting to non-representative synthetic datasets. They also illustrate how the ease of generating synthetic data can bypass the important principle of consent, which is a cornerstone of data privacy regulations.
These risks exemplify how the increasing use of synthetic data can complicate existing governance and ethical practices around the development and deployment of algorithmic systems. As machine learning continues to rely more heavily on synthetic data, the research community must grapple with these issues to ensure the responsible and accountable use of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Best Practices and Lessons Learned on Synthetic Data for Language Models
Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, Andrew M. Dai
0
0
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
4/12/2024
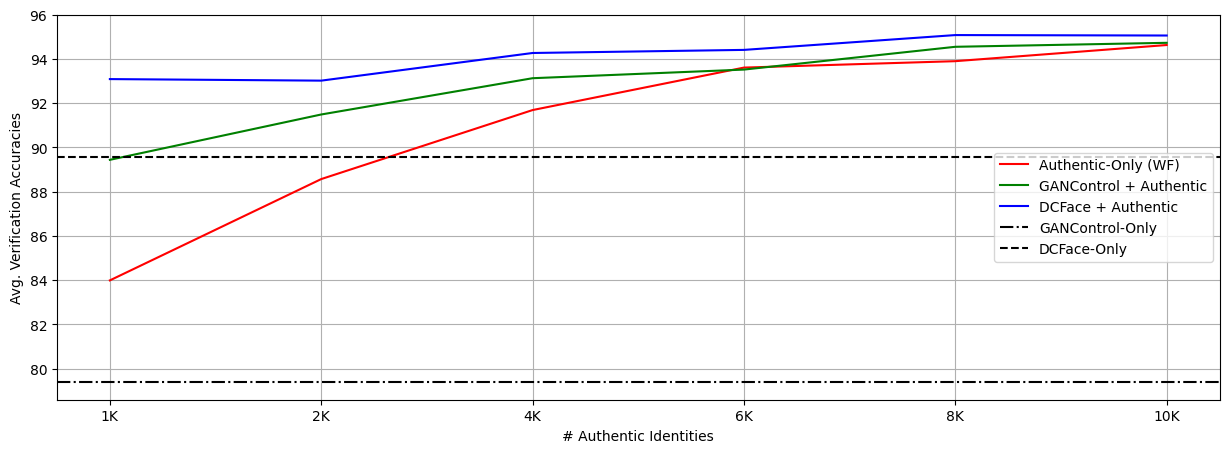
If It's Not Enough, Make It So: Reducing Authentic Data Demand in Face Recognition through Synthetic Faces
Andrea Atzori, Fadi Boutros, Naser Damer, Gianni Fenu, Mirko Marras
0
0
Recent advances in deep face recognition have spurred a growing demand for large, diverse, and manually annotated face datasets. Acquiring authentic, high-quality data for face recognition has proven to be a challenge, primarily due to privacy concerns. Large face datasets are primarily sourced from web-based images, lacking explicit user consent. In this paper, we examine whether and how synthetic face data can be used to train effective face recognition models with reduced reliance on authentic images, thereby mitigating data collection concerns. First, we explored the performance gap among recent state-of-the-art face recognition models, trained with synthetic data only and authentic (scarce) data only. Then, we deepened our analysis by training a state-of-the-art backbone with various combinations of synthetic and authentic data, gaining insights into optimizing the limited use of the latter for verification accuracy. Finally, we assessed the effectiveness of data augmentation approaches on synthetic and authentic data, with the same goal in mind. Our results highlighted the effectiveness of FR trained on combined datasets, particularly when combined with appropriate augmentation techniques.
4/29/2024
📊
Massively Annotated Datasets for Assessment of Synthetic and Real Data in Face Recognition
Pedro C. Neto, Rafael M. Mamede, Carolina Albuquerque, Tiago Gonc{c}alves, Ana F. Sequeira
0
0
Face recognition applications have grown in parallel with the size of datasets, complexity of deep learning models and computational power. However, while deep learning models evolve to become more capable and computational power keeps increasing, the datasets available are being retracted and removed from public access. Privacy and ethical concerns are relevant topics within these domains. Through generative artificial intelligence, researchers have put efforts into the development of completely synthetic datasets that can be used to train face recognition systems. Nonetheless, the recent advances have not been sufficient to achieve performance comparable to the state-of-the-art models trained on real data. To study the drift between the performance of models trained on real and synthetic datasets, we leverage a massive attribute classifier (MAC) to create annotations for four datasets: two real and two synthetic. From these annotations, we conduct studies on the distribution of each attribute within all four datasets. Additionally, we further inspect the differences between real and synthetic datasets on the attribute set. When comparing through the Kullback-Leibler divergence we have found differences between real and synthetic samples. Interestingly enough, we have verified that while real samples suffice to explain the synthetic distribution, the opposite could not be further from being true.
4/24/2024
📊
Synthetic Data Generation for Bridging Sim2Real Gap in a Production Environment
Parth Rawal, Mrunal Sompura, Wolfgang Hintze
0
0
Synthetic data is being used lately for training deep neural networks in computer vision applications such as object detection, object segmentation and 6D object pose estimation. Domain randomization hereby plays an important role in reducing the simulation to reality gap. However, this generalization might not be effective in specialized domains like a production environment involving complex assemblies. Either the individual parts, trained with synthetic images, are integrated in much larger assemblies making them indistinguishable from their counterparts and result in false positives or are partially occluded just enough to give rise to false negatives. Domain knowledge is vital in these cases and if conceived effectively while generating synthetic data, can show a considerable improvement in bridging the simulation to reality gap. This paper focuses on synthetic data generation procedures for parts and assemblies used in a production environment. The basic procedures for synthetic data generation and their various combinations are evaluated and compared on images captured in a production environment, where results show up to 15% improvement using combinations of basic procedures. Reducing the simulation to reality gap in this way can aid to utilize the true potential of robot assisted production using artificial intelligence.
5/13/2024