Real2Code: Reconstruct Articulated Objects via Code Generation

0
Sign in to get full access
Overview
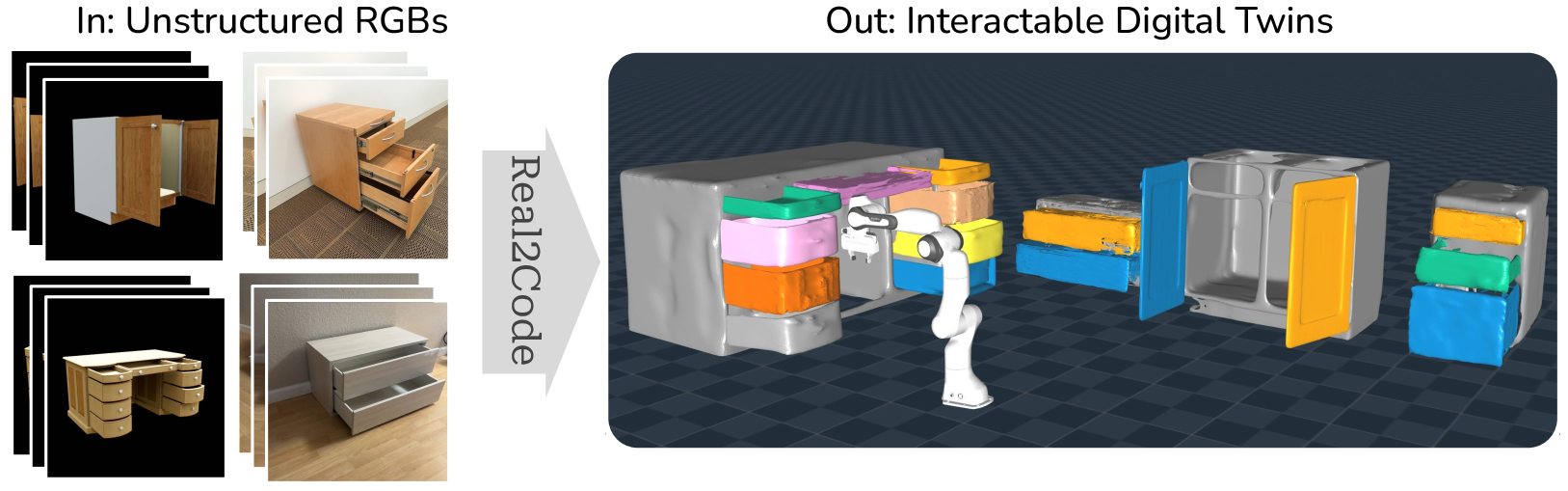
- This paper presents "Real2Code", a novel approach to reconstructing articulated objects from a single RGB image.
- The key idea is to generate a compact, code-based representation of the object's structure and motion, which can then be used to animate and manipulate the reconstructed model.
- The method leverages deep learning to infer the object's 3D shape, joint locations, and kinematic parameters from a single input image.
- This allows for the creation of dynamic, interactive 3D models of real-world articulated objects, with applications in areas like augmented reality, robotics, and computer animation.
Plain English Explanation
The researchers have developed a system called "Real2Code" that can take a single photo of an articulated object, like a robot arm or a toy, and use that information to create a 3D computer model that can move and be manipulated.
Instead of just generating a static 3D shape, the Real2Code system also figures out how the different parts of the object are connected and can move relative to each other. It does this by looking at the image and learning a compact "code" that describes the object's structure and motion.
This code-based representation allows the 3D model to be animated and controlled, rather than just being a fixed digital replica. The researchers believe this could be very useful for applications like augmented reality, where you want virtual objects to behave realistically, or robotics, where you need accurate models of physical systems.
Overall, the Real2Code system provides a way to capture the full 3D structure and motion of real-world articulated objects just from a single photograph, opening up new possibilities for interactive digital twins and simulations.
Technical Explanation
The core of the Real2Code approach is a deep neural network that takes a single RGB image as input and outputs a compact, code-based representation of the 3D shape, joint locations, and kinematic parameters of the articulated object.
This code representation consists of a set of learned parameters that define the object's structure and motion, including the 3D coordinates of the object's parts, the locations of the joints connecting those parts, and the ranges of motion for each joint.
To train this network, the researchers leveraged a large dataset of synthetic articulated objects with known 3D shapes and joint parameters. The network was tasked with reconstructing this information from just the 2D images of the objects.
Once trained, the Real2Code system can take a novel input image and use the learned model to infer the full 3D structure and kinematic properties of the depicted object. This allows for the creation of a dynamic 3D model that can be animated, manipulated, and integrated into downstream applications, such as virtual environments or robotic control systems.
The key innovation of this work is the use of a code-based object representation, which enables efficient storage and transfer of the 3D model, as well as easy modification and control of the object's motion. This is in contrast to other 3D reconstruction approaches that produce less flexible, mesh-based representations.
Critical Analysis
The Real2Code paper presents a promising approach for reconstructing articulated objects from single images, but it does have some limitations that are worth considering.
First, the method is heavily reliant on the availability of a large, high-quality training dataset of synthetic articulated objects. In practice, obtaining such a dataset for every possible object of interest may be challenging. The researchers acknowledge this and suggest that techniques like meta-learning could help alleviate the data requirement.
Additionally, the paper does not extensively evaluate the Real2Code system's performance on real-world images, which may contain more noise, occlusions, and variations than the synthetic training data. Further testing on diverse, real-world datasets would help validate the system's robustness.
Another potential concern is the interpretability and controllability of the learned code representation. While the compact, parametric nature of the representation is a key strength, it may be difficult for users to directly understand and modify the underlying kinematic structure of the reconstructed objects.
Despite these limitations, the Real2Code work represents an important step forward in the field of articulated object reconstruction, with promising applications in areas like augmented reality, robotics, and computer animation. Further research and development in this direction could lead to even more powerful and user-friendly tools for creating dynamic 3D models of real-world articulated objects.
Conclusion
The Real2Code system presented in this paper offers a novel approach to reconstructing articulated objects from single RGB images. By learning a compact, code-based representation of the object's 3D structure and kinematic parameters, the method enables the creation of dynamic, animatable 3D models that can be easily integrated into a variety of applications.
While the current implementation has some limitations, the core idea of using deep learning to infer a parametric representation of articulated objects is a promising direction for the field of 3D reconstruction. Further developments in this area could lead to significant advancements in the ability to digitize and interact with real-world physical systems in the virtual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Real2Code: Reconstruct Articulated Objects via Code Generation
Zhao Mandi, Yijia Weng, Dominik Bauer, Shuran Song
We present Real2Code, a novel approach to reconstructing articulated objects via code generation. Given visual observations of an object, we first reconstruct its part geometry using an image segmentation model and a shape completion model. We then represent the object parts with oriented bounding boxes, which are input to a fine-tuned large language model (LLM) to predict joint articulation as code. By leveraging pre-trained vision and language models, our approach scales elegantly with the number of articulated parts, and generalizes from synthetic training data to real world objects in unstructured environments. Experimental results demonstrate that Real2Code significantly outperforms previous state-of-the-art in reconstruction accuracy, and is the first approach to extrapolate beyond objects' structural complexity in the training set, and reconstructs objects with up to 10 articulated parts. When incorporated with a stereo reconstruction model, Real2Code also generalizes to real world objects from a handful of multi-view RGB images, without the need for depth or camera information.
Read more6/14/2024
🎯
0
Part-Guided 3D RL for Sim2Real Articulated Object Manipulation
Pengwei Xie, Rui Chen, Siang Chen, Yuzhe Qin, Fanbo Xiang, Tianyu Sun, Jing Xu, Guijin Wang, Hao Su
Manipulating unseen articulated objects through visual feedback is a critical but challenging task for real robots. Existing learning-based solutions mainly focus on visual affordance learning or other pre-trained visual models to guide manipulation policies, which face challenges for novel instances in real-world scenarios. In this paper, we propose a novel part-guided 3D RL framework, which can learn to manipulate articulated objects without demonstrations. We combine the strengths of 2D segmentation and 3D RL to improve the efficiency of RL policy training. To improve the stability of the policy on real robots, we design a Frame-consistent Uncertainty-aware Sampling (FUS) strategy to get a condensed and hierarchical 3D representation. In addition, a single versatile RL policy can be trained on multiple articulated object manipulation tasks simultaneously in simulation and shows great generalizability to novel categories and instances. Experimental results demonstrate the effectiveness of our framework in both simulation and real-world settings. Our code is available at https://github.com/THU-VCLab/Part-Guided-3D-RL-for-Sim2Real-Articulated-Object-Manipulation.
Read more4/29/2024
⛏️
0
CenterArt: Joint Shape Reconstruction and 6-DoF Grasp Estimation of Articulated Objects
Sassan Mokhtar, Eugenio Chisari, Nick Heppert, Abhinav Valada
Precisely grasping and reconstructing articulated objects is key to enabling general robotic manipulation. In this paper, we propose CenterArt, a novel approach for simultaneous 3D shape reconstruction and 6-DoF grasp estimation of articulated objects. CenterArt takes RGB-D images of the scene as input and first predicts the shape and joint codes through an encoder. The decoder then leverages these codes to reconstruct 3D shapes and estimate 6-DoF grasp poses of the objects. We further develop a mechanism for generating a dataset of 6-DoF grasp ground truth poses for articulated objects. CenterArt is trained on realistic scenes containing multiple articulated objects with randomized designs, textures, lighting conditions, and realistic depths. We perform extensive experiments demonstrating that CenterArt outperforms existing methods in accuracy and robustness.
Read more4/24/2024

0
Neural Implicit Representation for Building Digital Twins of Unknown Articulated Objects
Yijia Weng, Bowen Wen, Jonathan Tremblay, Valts Blukis, Dieter Fox, Leonidas Guibas, Stan Birchfield
We address the problem of building digital twins of unknown articulated objects from two RGBD scans of the object at different articulation states. We decompose the problem into two stages, each addressing distinct aspects. Our method first reconstructs object-level shape at each state, then recovers the underlying articulation model including part segmentation and joint articulations that associate the two states. By explicitly modeling point-level correspondences and exploiting cues from images, 3D reconstructions, and kinematics, our method yields more accurate and stable results compared to prior work. It also handles more than one movable part and does not rely on any object shape or structure priors. Project page: https://github.com/NVlabs/DigitalTwinArt
Read more6/10/2024