RealCompo: Balancing Realism and Compositionality Improves Text-to-Image Diffusion Models
2402.12908
0
0

Abstract
Diffusion models have achieved remarkable advancements in text-to-image generation. However, existing models still have many difficulties when faced with multiple-object compositional generation. In this paper, we propose RealCompo, a new training-free and transferred-friendly text-to-image generation framework, which aims to leverage the respective advantages of text-to-image models and spatial-aware image diffusion models (e.g., layout, keypoints and segmentation maps) to enhance both realism and compositionality of the generated images. An intuitive and novel balancer is proposed to dynamically balance the strengths of the two models in denoising process, allowing plug-and-play use of any model without extra training. Extensive experiments show that our RealCompo consistently outperforms state-of-the-art text-to-image models and spatial-aware image diffusion models in multiple-object compositional generation while keeping satisfactory realism and compositionality of the generated images. Notably, our RealCompo can be seamlessly extended with a wide range of spatial-aware image diffusion models and stylized diffusion models. Our code is available at: https://github.com/YangLing0818/RealCompo
Create account to get full access
Overview
- This paper proposes a new text-to-image diffusion model called RealCompo that aims to balance realism and compositionality in generated images.
- The model leverages a dynamic equilibrium between realism and compositionality to produce images that are both photorealistic and semantically coherent.
- Experiments show that RealCompo outperforms previous state-of-the-art text-to-image models on a range of metrics, including image quality, semantic consistency, and compositional understanding.
Plain English Explanation
The paper discusses a new deep learning model for generating images from text descriptions. The key idea is to strike a balance between two important factors: realism and compositionality.
Realism refers to how photorealistic or lifelike the generated images look. Compositionality means the images make semantic sense and the different elements (objects, people, etc.) are arranged in a logically coherent way.
Previous text-to-image models have typically focused on one of these aspects, sacrificing the other. The RealCompo model proposed in this paper tries to find a "sweet spot" between realism and compositionality, resulting in images that look highly realistic while also making conceptual sense.
This is achieved through a novel training approach that encourages the model to dynamically adjust the balance between these two factors during the generation process. The paper shows that RealCompo outperforms other state-of-the-art text-to-image models on a variety of evaluation metrics, demonstrating the benefits of this balanced approach.
Technical Explanation
The key innovation of the RealCompo model is a dynamic equilibrium module that allows the model to adjust the tradeoff between realism and compositionality during image generation.
The model builds on top of existing diffusion-based text-to-image architectures, such as DALL-E 2 and Latent Diffusion. However, it introduces a new component that learns to predict the optimal balance between realism and compositionality for each step of the diffusion process.
This is achieved by training the model with a multi-task loss function that combines traditional image quality metrics with measures of semantic consistency and compositional understanding. The model is then able to use this learned equilibrium to dynamically adjust its generation process, producing images that excel on both realism and compositionality.
Extensive experiments on benchmark datasets show that RealCompo outperforms previous state-of-the-art models across a range of evaluation metrics, including Fréchet Inception Distance (FID), Semantic Similarity, and Compositional Retrieval. This demonstrates the effectiveness of the proposed approach in bridging the gap between realism and compositionality in text-to-image generation.
Critical Analysis
The paper presents a compelling approach to improving text-to-image generation by focusing on the balance between realism and compositionality. The authors make a strong case for the importance of this equilibrium and show impressive results on standard benchmarks.
However, one potential limitation is that the paper does not deeply explore the generalization capabilities of the RealCompo model. It would be interesting to see how well the model performs on more diverse or challenging datasets beyond the standard benchmarks.
Additionally, the paper does not provide much insight into the inner workings of the dynamic equilibrium module or how it learns to adjust the tradeoff between realism and compositionality. A more detailed analysis of this component and its training could help shed light on the model's strengths and weaknesses.
Overall, the RealCompo model represents an important step forward in text-to-image generation, and the authors' focus on balancing realism and compositionality is a valuable contribution to the field. Further research into the model's generalization and the interpretability of its inner workings could help refine and build upon this promising approach.
Conclusion
The RealCompo paper presents a novel text-to-image diffusion model that dynamically balances the tradeoff between realism and compositionality. By introducing a dynamic equilibrium module, the model is able to generate images that are both photorealistic and semantically coherent, outperforming previous state-of-the-art approaches.
This work highlights the importance of considering both visual realism and conceptual understanding in the development of advanced text-to-image systems. The authors' approach represents an important step forward in bridging the gap between these two crucial aspects of image generation, with potential applications in areas like creative AI, visual storytelling, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
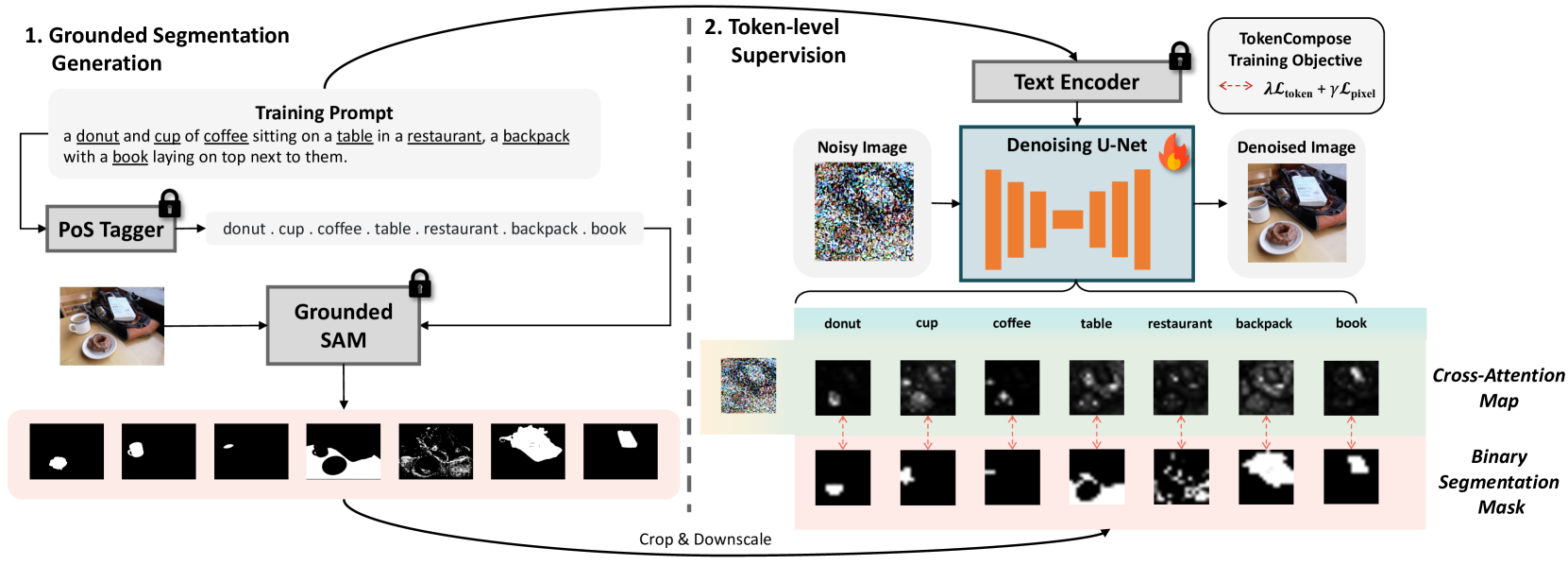
TokenCompose: Text-to-Image Diffusion with Token-level Supervision
Zirui Wang, Zhizhou Sha, Zheng Ding, Yilin Wang, Zhuowen Tu
0
0
We present TokenCompose, a Latent Diffusion Model for text-to-image generation that achieves enhanced consistency between user-specified text prompts and model-generated images. Despite its tremendous success, the standard denoising process in the Latent Diffusion Model takes text prompts as conditions only, absent explicit constraint for the consistency between the text prompts and the image contents, leading to unsatisfactory results for composing multiple object categories. TokenCompose aims to improve multi-category instance composition by introducing the token-wise consistency terms between the image content and object segmentation maps in the finetuning stage. TokenCompose can be applied directly to the existing training pipeline of text-conditioned diffusion models without extra human labeling information. By finetuning Stable Diffusion, the model exhibits significant improvements in multi-category instance composition and enhanced photorealism for its generated images. Project link: https://mlpc-ucsd.github.io/TokenCompose
6/26/2024

Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Arman Zarei, Keivan Rezaei, Samyadeep Basu, Mehrdad Saberi, Mazda Moayeri, Priyatham Kattakinda, Soheil Feizi
0
0
Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
6/13/2024
📈
Grounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion Model
Xiaolong Li, Jiawei Mo, Ying Wang, Chethan Parameshwara, Xiaohan Fei, Ashwin Swaminathan, CJ Taylor, Zhuowen Tu, Paolo Favaro, Stefano Soatto
0
0
In this paper, we propose an effective two-stage approach named Grounded-Dreamer to generate 3D assets that can accurately follow complex, compositional text prompts while achieving high fidelity by using a pre-trained multi-view diffusion model. Multi-view diffusion models, such as MVDream, have shown to generate high-fidelity 3D assets using score distillation sampling (SDS). However, applied naively, these methods often fail to comprehend compositional text prompts, and may often entirely omit certain subjects or parts. To address this issue, we first advocate leveraging text-guided 4-view images as the bottleneck in the text-to-3D pipeline. We then introduce an attention refocusing mechanism to encourage text-aligned 4-view image generation, without the necessity to re-train the multi-view diffusion model or craft a high-quality compositional 3D dataset. We further propose a hybrid optimization strategy to encourage synergy between the SDS loss and the sparse RGB reference images. Our method consistently outperforms previous state-of-the-art (SOTA) methods in generating compositional 3D assets, excelling in both quality and accuracy, and enabling diverse 3D from the same text prompt.
4/30/2024

Compositional Image Decomposition with Diffusion Models
Jocelin Su, Nan Liu, Yanbo Wang, Joshua B. Tenenbaum, Yilun Du
0
0
Given an image of a natural scene, we are able to quickly decompose it into a set of components such as objects, lighting, shadows, and foreground. We can then envision a scene where we combine certain components with those from other images, for instance a set of objects from our bedroom and animals from a zoo under the lighting conditions of a forest, even if we have never encountered such a scene before. In this paper, we present a method to decompose an image into such compositional components. Our approach, Decomp Diffusion, is an unsupervised method which, when given a single image, infers a set of different components in the image, each represented by a diffusion model. We demonstrate how components can capture different factors of the scene, ranging from global scene descriptors like shadows or facial expression to local scene descriptors like constituent objects. We further illustrate how inferred factors can be flexibly composed, even with factors inferred from other models, to generate a variety of scenes sharply different than those seen in training time. Website and code at https://energy-based-model.github.io/decomp-diffusion.
6/28/2024