TokenCompose: Text-to-Image Diffusion with Token-level Supervision
2312.03626
0
0
Abstract
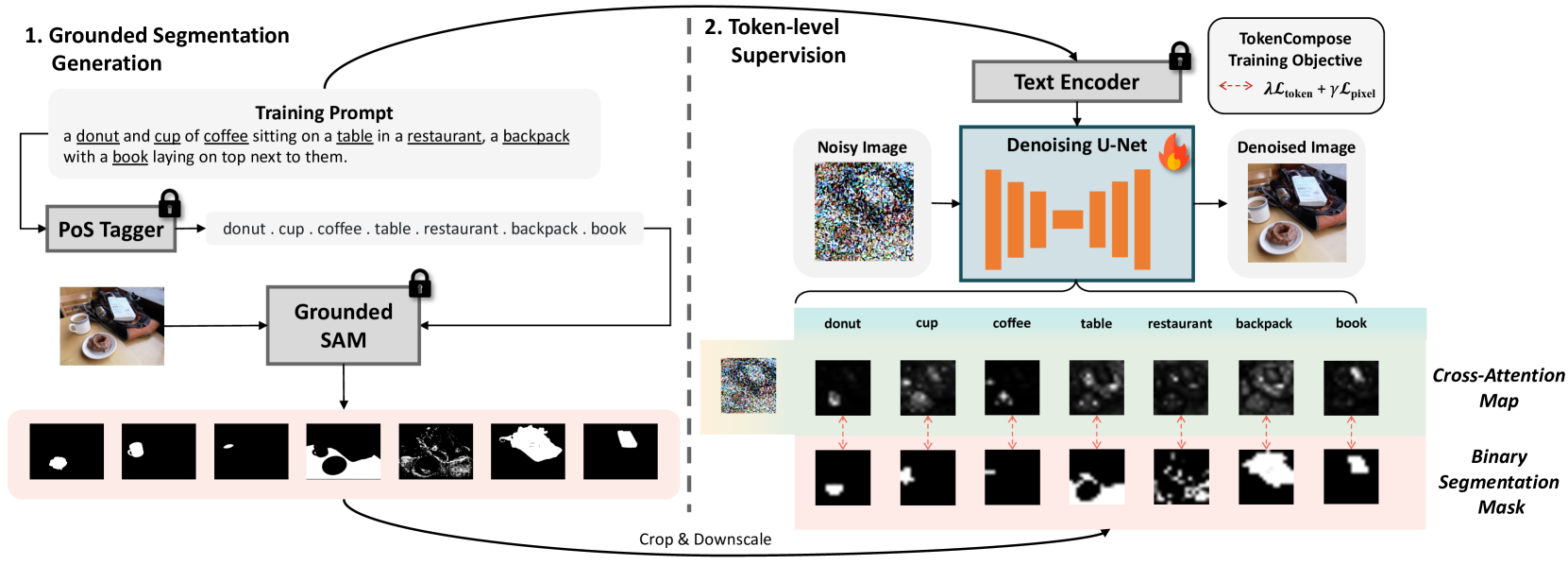
We present TokenCompose, a Latent Diffusion Model for text-to-image generation that achieves enhanced consistency between user-specified text prompts and model-generated images. Despite its tremendous success, the standard denoising process in the Latent Diffusion Model takes text prompts as conditions only, absent explicit constraint for the consistency between the text prompts and the image contents, leading to unsatisfactory results for composing multiple object categories. TokenCompose aims to improve multi-category instance composition by introducing the token-wise consistency terms between the image content and object segmentation maps in the finetuning stage. TokenCompose can be applied directly to the existing training pipeline of text-conditioned diffusion models without extra human labeling information. By finetuning Stable Diffusion, the model exhibits significant improvements in multi-category instance composition and enhanced photorealism for its generated images. Project link: https://mlpc-ucsd.github.io/TokenCompose
Create account to get full access
Overview
- The paper introduces a new diffusion-based model called TokenCompose that grounds the generation process with token-level supervision.
- TokenCompose aims to improve the compositionality and realism of text-to-image generation by leveraging fine-grained token-level guidance.
- The model uses a two-stage training process, first pre-training on a large corpus of image-text pairs and then fine-tuning with token-level annotations.
Plain English Explanation
The TokenCompose model is a new approach to generating images from text that tries to improve on the realism and coherence of the generated images.
Traditional text-to-image models often struggle to produce images that accurately reflect the full meaning and composition of the text prompt. TokenCompose aims to address this by providing the model with more detailed, token-level guidance during the image generation process.
The key idea is to first train the model on a large dataset of image-text pairs, allowing it to learn the general correspondence between visual elements and textual concepts. Then, in a second stage, the model is fine-tuned using additional data that includes annotations linking specific words or phrases in the text to corresponding regions in the images.
This token-level supervision helps the model better understand how the different parts of the text prompt should be visually expressed, leading to more compositionally accurate and realistic generated images. The approach draws inspiration from related work in controllable image generation and text-to-image understanding.
Technical Explanation
The TokenCompose model is built on top of a diffusion-based architecture, where the generation process involves gradually denoising a random noise image towards the desired output.
The key innovation is the introduction of a token-level conditioning mechanism, where the model learns to associate specific tokens in the text prompt with corresponding visual regions in the image. This is achieved through a two-stage training process:
- Pre-training: The model is first trained on a large dataset of image-text pairs, learning to generate images that align with the overall text prompt.
- Fine-tuning: In the second stage, the model is further trained using data that includes token-level alignments between text and image regions. This allows the model to learn more fine-grained correspondences between textual concepts and visual elements.
The token-level conditioning is implemented by having the model predict a set of token-specific image representations in parallel, which are then combined to produce the final image. This architecture allows the model to explicitly reason about how different parts of the text should be reflected in the generated output.
Experiments on benchmark text-to-image datasets show that TokenCompose outperforms previous state-of-the-art models in terms of both compositional accuracy and overall image quality.
Critical Analysis
The TokenCompose approach represents an interesting step forward in text-to-image generation, but it also has some potential limitations and areas for further research:
- The requirement for token-level annotations during the fine-tuning stage may limit the scalability of the approach, as such detailed annotations can be expensive to obtain.
- The model's performance is still not perfect, and there may be ways to further improve the compositionality and realism of the generated images.
- The paper does not explore the model's robustness to more diverse or complex text prompts, which could be an important area for future work.
Additionally, while the TokenCompose approach is a step in the right direction, there are other related techniques, such as RealCompo and TIE, that also aim to address the compositionality and realism challenges in text-to-image generation. A comparative analysis of these different approaches could provide valuable insights.
Conclusion
The TokenCompose model represents an important advancement in text-to-image generation by incorporating token-level supervision to improve the compositionality and realism of the generated images.
This approach demonstrates the potential benefits of providing models with more fine-grained guidance during the generation process, and it opens up new avenues for research in areas such as compositional understanding, grounded language modeling, and multi-modal generation. As the field of text-to-image continues to evolve, techniques like TokenCompose may play a key role in pushing the boundaries of what is possible in terms of creating visually coherent and semantically accurate images from textual descriptions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RealCompo: Balancing Realism and Compositionality Improves Text-to-Image Diffusion Models
Xinchen Zhang, Ling Yang, Yaqi Cai, Zhaochen Yu, Kai-Ni Wang, Jiake Xie, Ye Tian, Minkai Xu, Yong Tang, Yujiu Yang, Bin Cui
0
0
Diffusion models have achieved remarkable advancements in text-to-image generation. However, existing models still have many difficulties when faced with multiple-object compositional generation. In this paper, we propose RealCompo, a new training-free and transferred-friendly text-to-image generation framework, which aims to leverage the respective advantages of text-to-image models and spatial-aware image diffusion models (e.g., layout, keypoints and segmentation maps) to enhance both realism and compositionality of the generated images. An intuitive and novel balancer is proposed to dynamically balance the strengths of the two models in denoising process, allowing plug-and-play use of any model without extra training. Extensive experiments show that our RealCompo consistently outperforms state-of-the-art text-to-image models and spatial-aware image diffusion models in multiple-object compositional generation while keeping satisfactory realism and compositionality of the generated images. Notably, our RealCompo can be seamlessly extended with a wide range of spatial-aware image diffusion models and stylized diffusion models. Our code is available at: https://github.com/YangLing0818/RealCompo
6/5/2024

Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Arman Zarei, Keivan Rezaei, Samyadeep Basu, Mehrdad Saberi, Mazda Moayeri, Priyatham Kattakinda, Soheil Feizi
0
0
Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
6/13/2024

Towards Understanding the Working Mechanism of Text-to-Image Diffusion Model
Mingyang Yi, Aoxue Li, Yi Xin, Zhenguo Li
0
0
Recently, the strong latent Diffusion Probabilistic Model (DPM) has been applied to high-quality Text-to-Image (T2I) generation (e.g., Stable Diffusion), by injecting the encoded target text prompt into the gradually denoised diffusion image generator. Despite the success of DPM in practice, the mechanism behind it remains to be explored. To fill this blank, we begin by examining the intermediate statuses during the gradual denoising generation process in DPM. The empirical observations indicate, the shape of image is reconstructed after the first few denoising steps, and then the image is filled with details (e.g., texture). The phenomenon is because the low-frequency signal (shape relevant) of the noisy image is not corrupted until the final stage in the forward process (initial stage of generation) of adding noise in DPM. Inspired by the observations, we proceed to explore the influence of each token in the text prompt during the two stages. After a series of experiments of T2I generations conditioned on a set of text prompts. We conclude that in the earlier generation stage, the image is mostly decided by the special token [texttt{EOS}] in the text prompt, and the information in the text prompt is already conveyed in this stage. After that, the diffusion model completes the details of generated images by information from themselves. Finally, we propose to apply this observation to accelerate the process of T2I generation by properly removing text guidance, which finally accelerates the sampling up to 25%+.
5/27/2024
🖼️
Controllable Image Generation With Composed Parallel Token Prediction
Jamie Stirling, Noura Al-Moubayed
0
0
Compositional image generation requires models to generalise well in situations where two or more input concepts do not necessarily appear together in training (compositional generalisation). Despite recent progress in compositional image generation via composing continuous sampling processes such as diffusion and energy-based models, composing discrete generative processes has remained an open challenge, with the promise of providing improvements in efficiency, interpretability and simplicity. To this end, we propose a formulation for controllable conditional generation of images via composing the log-probability outputs of discrete generative models of the latent space. Our approach, when applied alongside VQ-VAE and VQ-GAN, achieves state-of-the-art generation accuracy in three distinct settings (FFHQ, Positional CLEVR and Relational CLEVR) while attaining competitive Fr'echet Inception Distance (FID) scores. Our method attains an average generation accuracy of $80.71%$ across the studied settings. Our method also outperforms the next-best approach (ranked by accuracy) in terms of FID in seven out of nine experiments, with an average FID of $24.23$ (an average improvement of $-9.58$). Furthermore, our method offers a $2.3times$ to $12times$ speedup over comparable continuous compositional methods on our hardware. We find that our method can generalise to combinations of input conditions that lie outside the training data (e.g. more objects per image) in addition to offering an interpretable dimension of controllability via concept weighting. We further demonstrate that our approach can be readily applied to an open pre-trained discrete text-to-image model without any fine-tuning, allowing for fine-grained control of text-to-image generation.
5/13/2024