Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
2401.11708
0
0

Abstract
Diffusion models have exhibit exceptional performance in text-to-image generation and editing. However, existing methods often face challenges when handling complex text prompts that involve multiple objects with multiple attributes and relationships. In this paper, we propose a brand new training-free text-to-image generation/editing framework, namely Recaption, Plan and Generate (RPG), harnessing the powerful chain-of-thought reasoning ability of multimodal LLMs to enhance the compositionality of text-to-image diffusion models. Our approach employs the MLLM as a global planner to decompose the process of generating complex images into multiple simpler generation tasks within subregions. We propose complementary regional diffusion to enable region-wise compositional generation. Furthermore, we integrate text-guided image generation and editing within the proposed RPG in a closed-loop fashion, thereby enhancing generalization ability. Extensive experiments demonstrate our RPG outperforms state-of-the-art text-to-image diffusion models, including DALL-E 3 and SDXL, particularly in multi-category object composition and text-image semantic alignment. Notably, our RPG framework exhibits wide compatibility with various MLLM architectures (e.g., MiniGPT-4) and diffusion backbones (e.g., ControlNet). Our code is available at: https://github.com/YangLing0818/RPG-DiffusionMaster
Create account to get full access
Introduction
Overview
- This paper presents a novel approach called RPG (Recaptioning, Planning, and Generating) that leverages multimodal large language models (LLMs) to enable advanced text-to-image diffusion capabilities.
- RPG allows for recaptioning of existing images, planning of image generation based on textual prompts, and generation of new images from scratch.
- The method combines the strengths of diffusion models and LLMs to achieve more versatile and controllable text-to-image generation.
Plain English Explanation
The paper introduces a new system called RPG that uses large AI language models to improve how text can be used to create, edit, and plan images. Diffusion models are a type of AI that can generate new images, while large language models are AI systems trained on a lot of text data.
The RPG system combines these two approaches to give users more control and flexibility when generating images from text. It allows you to:
- Recaption existing images by describing them in new ways
- Plan the creation of new images by describing what you want to see
- Generate completely new images from scratch based on text prompts
This makes the text-to-image process more powerful and versatile compared to previous methods. The key idea is to leverage the strengths of both diffusion models and language models to enable more advanced and user-friendly image generation capabilities.
Technical Explanation
The paper introduces a framework called Recaptioning, Planning, and Generating (RPG) that integrates diffusion models with multimodal large language models (LLMs) to enable more advanced text-to-image generation capabilities.
The recaptioning module allows users to describe an existing image in new ways, updating the caption while preserving the image's content. The planning module takes a textual prompt and generates an image plan - a set of intermediate representations that guide the final image generation.
Finally, the generation module uses the image plan to produce a new image from scratch that matches the original prompt. By combining the strengths of diffusion models and LLMs, RPG achieves greater flexibility, controllability, and performance compared to prior text-to-image approaches like DALL-E or Stable Diffusion.
The paper presents experiments demonstrating RPG's capabilities in recaptioning, planning, and generation tasks, showing its potential to advance the state-of-the-art in text-guided image manipulation.
Critical Analysis
The paper makes a compelling case for the RPG framework as a powerful new approach to text-to-image generation. By integrating diffusion models and language models, it addresses key limitations of prior systems and expands the possibilities for creative and controlled image synthesis.
However, the authors acknowledge some limitations and areas for further research. For example, the planning module may struggle with highly abstract or complex prompts, and the generation quality could potentially be improved with more advanced diffusion or LLM architectures.
Additionally, the paper does not deeply explore potential societal impacts or ethical considerations around this technology, such as the risk of misuse for creating misleading or harmful imagery. As the field of text-to-image generation continues to advance rapidly, it will be important for researchers to proactively address these types of concerns.
Overall, the RPG framework represents an exciting step forward in multimodal AI capabilities. With further refinement and responsible development, it could unlock new creative and practical applications for text-guided image manipulation.
Conclusion
This paper introduces a novel Recaptioning, Planning, and Generating (RPG) framework that leverages the complementary strengths of diffusion models and large language models to enable advanced text-to-image generation capabilities.
RPG allows users to recaption existing images, plan the creation of new images from textual prompts, and generate completely novel images. By combining these powerful capabilities, the system aims to provide more flexible, controllable, and high-performing text-guided image manipulation compared to prior approaches.
The experimental results demonstrate the potential of RPG to advance the state-of-the-art in this field, though the authors acknowledge areas for further improvement and the need to consider ethical implications as the technology develops. Overall, this work represents an exciting step forward in the integration of language and vision AI models to enable more seamless and creative human-AI collaboration around image creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
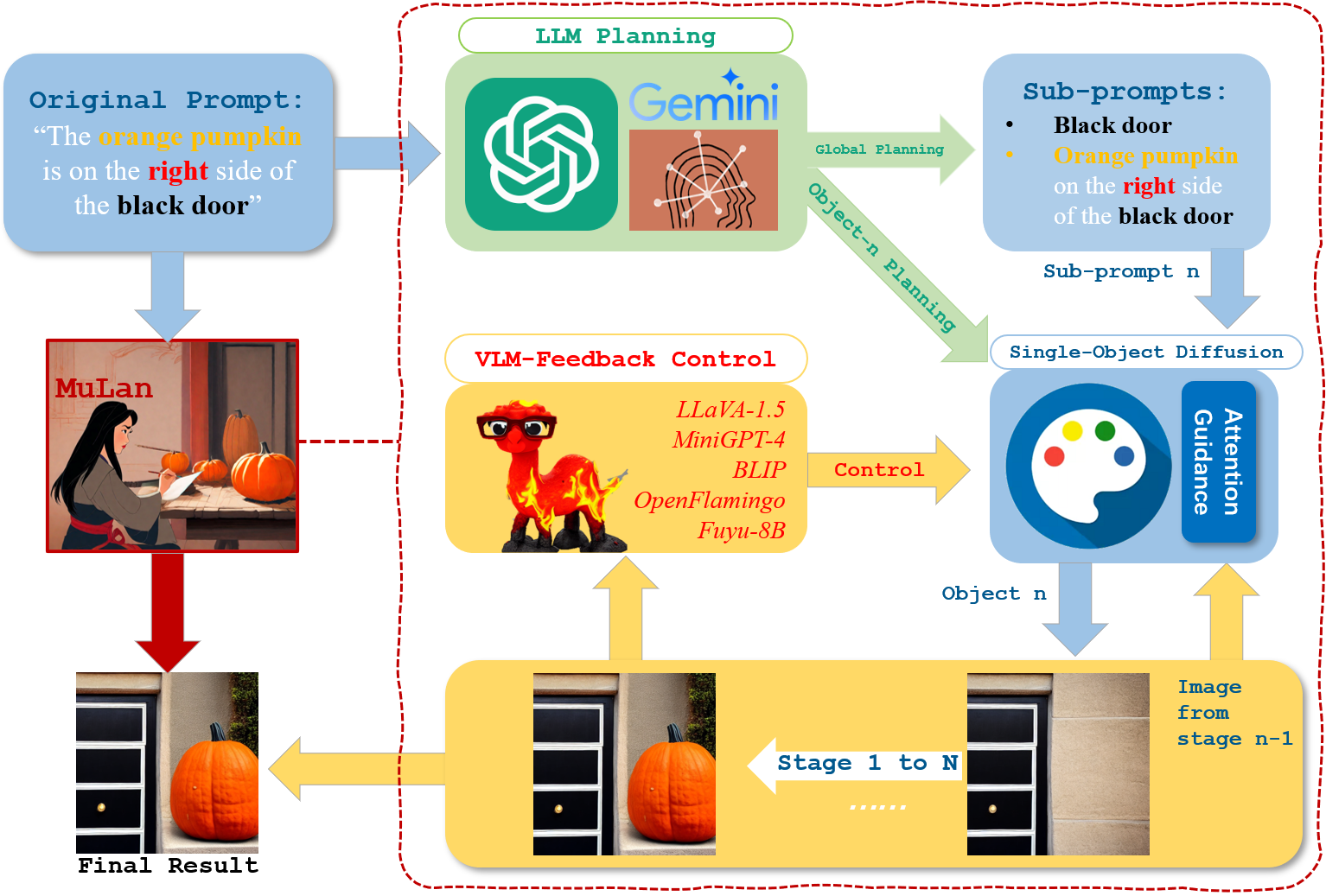
MuLan: Multimodal-LLM Agent for Progressive and Interactive Multi-Object Diffusion
Sen Li, Ruochen Wang, Cho-Jui Hsieh, Minhao Cheng, Tianyi Zhou
0
0
Existing text-to-image models still struggle to generate images of multiple objects, especially in handling their spatial positions, relative sizes, overlapping, and attribute bindings. To efficiently address these challenges, we develop a training-free Multimodal-LLM agent (MuLan), as a human painter, that can progressively generate multi-object with intricate planning and feedback control. MuLan harnesses a large language model (LLM) to decompose a prompt to a sequence of sub-tasks, each generating only one object by stable diffusion, conditioned on previously generated objects. Unlike existing LLM-grounded methods, MuLan only produces a high-level plan at the beginning while the exact size and location of each object are determined upon each sub-task by an LLM and attention guidance. Moreover, MuLan adopts a vision-language model (VLM) to provide feedback to the image generated in each sub-task and control the diffusion model to re-generate the image if it violates the original prompt. Hence, each model in every step of MuLan only needs to address an easy sub-task it is specialized for. The multi-step process also allows human users to monitor the generation process and make preferred changes at any intermediate step via text prompts, thereby improving the human-AI collaboration experience. We collect 200 prompts containing multi-objects with spatial relationships and attribute bindings from different benchmarks to evaluate MuLan. The results demonstrate the superiority of MuLan in generating multiple objects over baselines and its creativity when collaborating with human users. The code is available at https://github.com/measure-infinity/mulan-code.
5/27/2024
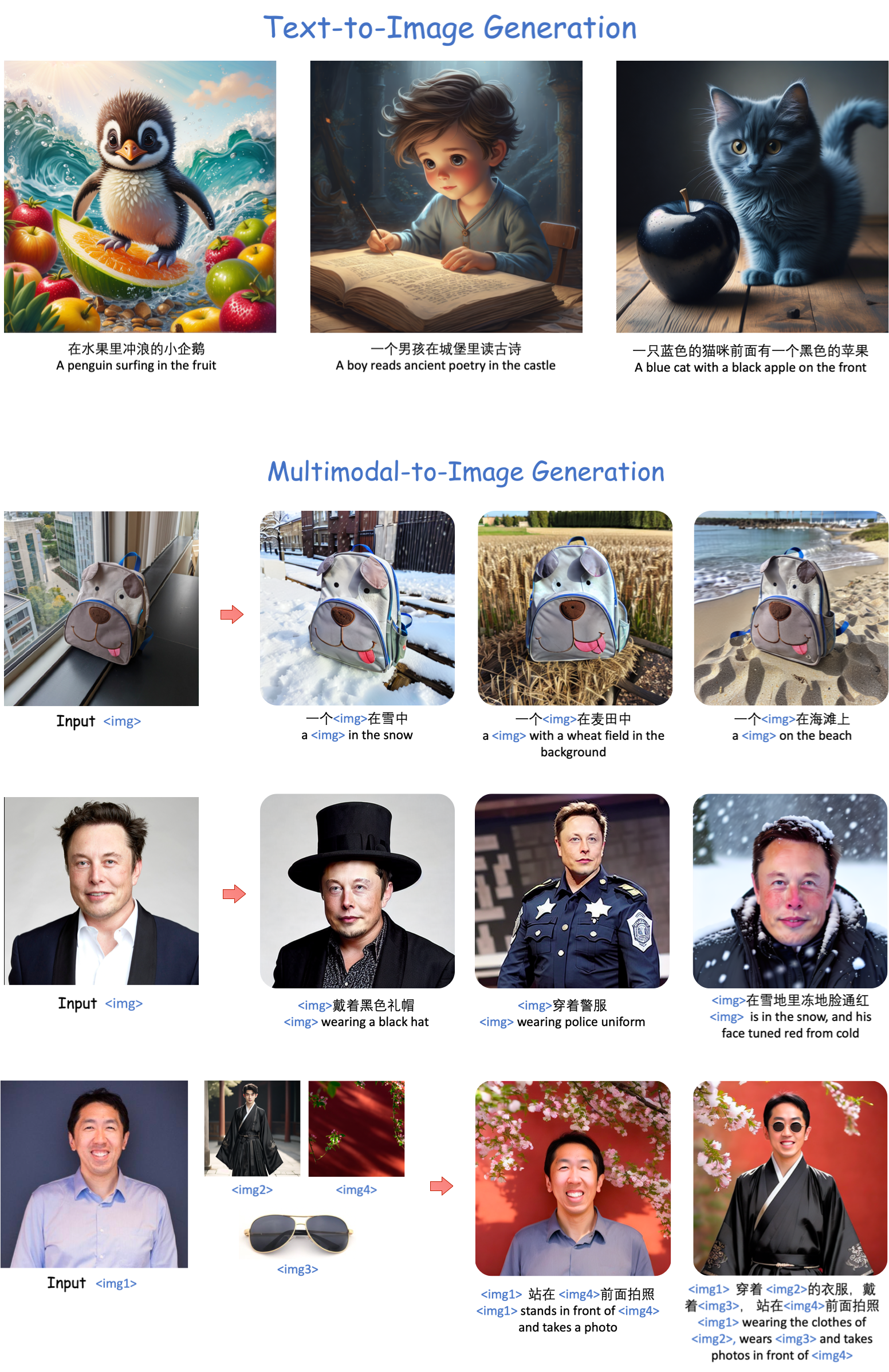
UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion
Wei Li, Xue Xu, Jiachen Liu, Xinyan Xiao
0
0
Existing text-to-image diffusion models primarily generate images from text prompts. However, the inherent conciseness of textual descriptions poses challenges in faithfully synthesizing images with intricate details, such as specific entities or scenes. This paper presents UNIMO-G, a simple multimodal conditional diffusion framework that operates on multimodal prompts with interleaved textual and visual inputs, which demonstrates a unified ability for both text-driven and subject-driven image generation. UNIMO-G comprises two core components: a Multimodal Large Language Model (MLLM) for encoding multimodal prompts, and a conditional denoising diffusion network for generating images based on the encoded multimodal input. We leverage a two-stage training strategy to effectively train the framework: firstly pre-training on large-scale text-image pairs to develop conditional image generation capabilities, and then instruction tuning with multimodal prompts to achieve unified image generation proficiency. A well-designed data processing pipeline involving language grounding and image segmentation is employed to construct multi-modal prompts. UNIMO-G excels in both text-to-image generation and zero-shot subject-driven synthesis, and is notably effective in generating high-fidelity images from complex multimodal prompts involving multiple image entities.
6/7/2024
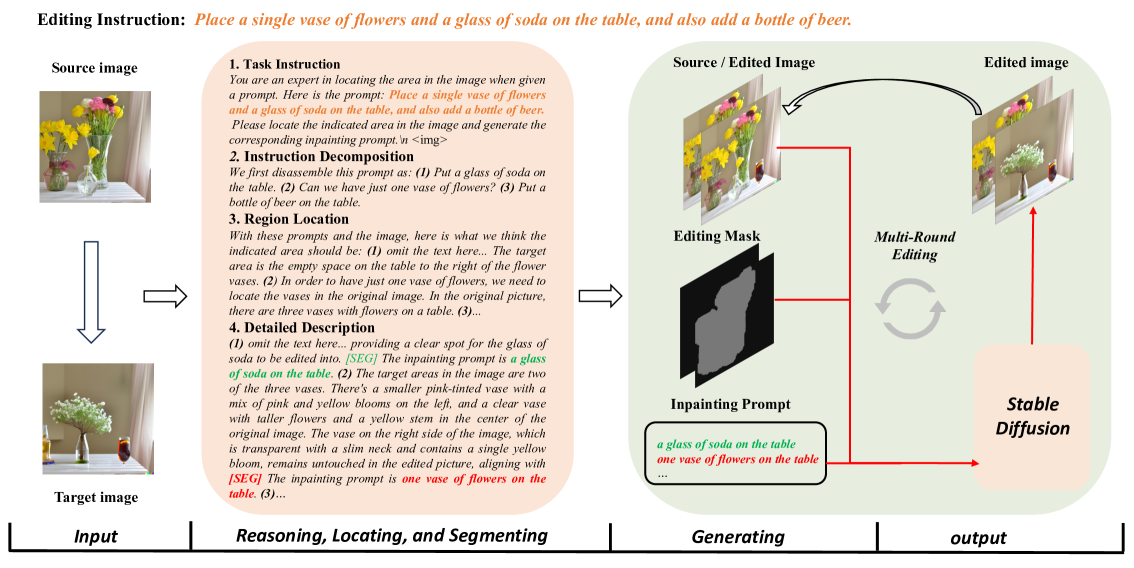
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
0
0
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
5/28/2024

RealCompo: Balancing Realism and Compositionality Improves Text-to-Image Diffusion Models
Xinchen Zhang, Ling Yang, Yaqi Cai, Zhaochen Yu, Kai-Ni Wang, Jiake Xie, Ye Tian, Minkai Xu, Yong Tang, Yujiu Yang, Bin Cui
0
0
Diffusion models have achieved remarkable advancements in text-to-image generation. However, existing models still have many difficulties when faced with multiple-object compositional generation. In this paper, we propose RealCompo, a new training-free and transferred-friendly text-to-image generation framework, which aims to leverage the respective advantages of text-to-image models and spatial-aware image diffusion models (e.g., layout, keypoints and segmentation maps) to enhance both realism and compositionality of the generated images. An intuitive and novel balancer is proposed to dynamically balance the strengths of the two models in denoising process, allowing plug-and-play use of any model without extra training. Extensive experiments show that our RealCompo consistently outperforms state-of-the-art text-to-image models and spatial-aware image diffusion models in multiple-object compositional generation while keeping satisfactory realism and compositionality of the generated images. Notably, our RealCompo can be seamlessly extended with a wide range of spatial-aware image diffusion models and stylized diffusion models. Our code is available at: https://github.com/YangLing0818/RealCompo
6/5/2024