Recasting Generic Pretrained Vision Transformers As Object-Centric Scene Encoders For Manipulation Policies

0

Sign in to get full access
Overview
- This paper explores the use of generic pre-trained Vision Transformers (ViTs) as object-centric scene encoders for manipulation policies in robotics.
- The authors propose a method to recasts pre-trained ViTs to extract object-level representations from visual inputs, which can then be used to train manipulation policies.
- The approach aims to leverage the rich visual understanding capabilities of ViTs without the need for task-specific fine-tuning, enabling more efficient and effective robotic manipulation.
Plain English Explanation
Vision Transformers (ViTs) are a type of artificial intelligence model that have shown impressive performance in understanding and processing visual information. The authors of this paper had an interesting idea - what if we could use these pre-trained ViTs, without having to retrain them, to help robots understand and interact with the objects in their environment?
Typically, when you want to use an AI model for a specific task like robot control, you need to "fine-tune" the model on a lot of task-specific data. This can be time-consuming and resource-intensive. The researchers figured that if they could reconfigure the ViT model to focus on extracting information about individual objects in a scene, they could bypass the need for extensive fine-tuning and more directly apply the ViT's visual understanding capabilities to robotic manipulation tasks.
The key insight is that ViTs, even when pre-trained on generic image datasets, seem to develop an understanding of individual objects in images. By modifying the ViT architecture to emphasize this object-centric representation, the authors were able to use the pre-trained ViTs as efficient "scene encoders" to help robots learn manipulation policies - that is, how to best interact with and manipulate the objects in their environment.
This approach has the potential to make robotic manipulation more effective and easier to train, by leveraging the powerful visual understanding capabilities of ViTs without the need for extensive fine-tuning. It's an innovative way to connect the latest advances in computer vision AI with the practical needs of robotics.
Technical Explanation
The authors propose a method to recast generic pre-trained Vision Transformers (ViTs) as object-centric scene encoders for robotic manipulation tasks. ViTs are a type of deep learning model that has achieved state-of-the-art performance on various computer vision benchmarks by leveraging the Transformer architecture, which excels at capturing long-range dependencies in visual data.
The key insight is that even pre-trained ViTs seem to develop an understanding of individual objects in images, as evidenced by the strong performance of ViTs on object detection and segmentation tasks. The authors hypothesize that this object-centric visual understanding can be leveraged to train more effective robotic manipulation policies, without the need for extensive task-specific fine-tuning of the ViT model.
To this end, the authors propose a "recasting" approach that modifies the ViT architecture to emphasize the extraction of object-level representations from visual inputs. This involves introducing object-specific query tokens that are trained to attend to individual objects in the scene, as well as object-specific value heads that learn to output object-centric representations.
The authors evaluate their approach on several robotic manipulation tasks, including block stacking and tool use. They find that the recasted ViT-based scene encoders outperform traditional CNN-based encoders, as well as ViTs fine-tuned on the manipulation tasks. This suggests that the object-centric representations learned by the recasted ViTs are more effective for training manipulation policies compared to generic ViT or CNN features.
The authors also analyze the learned object representations and find that they capture relevant object properties, such as size, shape, and spatial relationships, which are important for successful manipulation. Overall, this work demonstrates the potential of leveraging generic pre-trained ViTs as efficient and effective scene encoders for robotic manipulation, without the need for extensive task-specific fine-tuning.
Critical Analysis
The authors present a compelling approach to leveraging the capabilities of pre-trained Vision Transformers for robotic manipulation tasks. By recasting the ViT architecture to focus on extracting object-centric representations, they are able to bypass the need for extensive fine-tuning, which can be a significant bottleneck in applying advanced computer vision models to robotic applications.
One potential limitation of the approach is that it relies on the pre-trained ViT model having developed a sufficiently rich understanding of objects and their properties. While the authors' findings suggest that this is the case, it's possible that the object-centric representations may not be fully optimal for certain manipulation tasks, particularly those that require more specialized object knowledge or reasoning.
Additionally, the authors' evaluation is focused on relatively simple manipulation tasks, such as block stacking and tool use. It would be interesting to see how the recasted ViT-based scene encoders perform on more complex manipulation tasks, where the ability to reason about object relationships and dynamics may become more crucial.
Further research could also explore ways to further fine-tune or adapt the recasted ViT models to specific robotic platforms or manipulation domains, potentially unlocking even greater performance gains. Investigating the generalization of this approach to other types of robotic tasks, such as navigation or interaction with deformable objects, could also be a fruitful avenue for future work.
Overall, this paper presents a promising and innovative approach to bridging the gap between the capabilities of advanced computer vision models and the practical requirements of robotic manipulation. By recasting generic ViTs as efficient and effective scene encoders, the authors have demonstrated a path towards more efficient and effective robotic control systems.
Conclusion
This paper proposes a novel method to recast generic pre-trained Vision Transformers (ViTs) as object-centric scene encoders for robotic manipulation tasks. By modifying the ViT architecture to focus on extracting representations of individual objects in a scene, the authors are able to leverage the powerful visual understanding capabilities of ViTs without the need for extensive task-specific fine-tuning.
The authors' results show that the recasted ViT-based scene encoders outperform traditional CNN-based encoders, as well as ViTs fine-tuned on the manipulation tasks, suggesting that the object-centric representations learned by the recasted ViTs are more effective for training manipulation policies.
This work demonstrates the potential of using pre-trained computer vision models, like ViTs, as efficient and effective scene encoders for robotic applications, opening up new avenues for bridging the gap between the latest advancements in AI and the practical needs of robotics. Further research exploring the generalization of this approach to more complex manipulation tasks and other robotic domains could yield additional insights and opportunities for impactful real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Recasting Generic Pretrained Vision Transformers As Object-Centric Scene Encoders For Manipulation Policies
Jianing Qian, Anastasios Panagopoulos, Dinesh Jayaraman
Generic re-usable pre-trained image representation encoders have become a standard component of methods for many computer vision tasks. As visual representations for robots however, their utility has been limited, leading to a recent wave of efforts to pre-train robotics-specific image encoders that are better suited to robotic tasks than their generic counterparts. We propose Scene Objects From Transformers, abbreviated as SOFT, a wrapper around pre-trained vision transformer (PVT) models that bridges this gap without any further training. Rather than construct representations out of only the final layer activations, SOFT individuates and locates object-like entities from PVT attentions, and describes them with PVT activations, producing an object-centric embedding. Across standard choices of generic pre-trained vision transformers PVT, we demonstrate in each case that policies trained on SOFT(PVT) far outstrip standard PVT representations for manipulation tasks in simulated and real settings, approaching the state-of-the-art robotics-aware representations. Code, appendix and videos: https://sites.google.com/view/robot-soft/
Read more5/28/2024

0
Composing Pre-Trained Object-Centric Representations for Robotics From What and Where Foundation Models
Junyao Shi, Jianing Qian, Yecheng Jason Ma, Dinesh Jayaraman
There have recently been large advances both in pre-training visual representations for robotic control and segmenting unknown category objects in general images. To leverage these for improved robot learning, we propose $textbf{POCR}$, a new framework for building pre-trained object-centric representations for robotic control. Building on theories of what-where representations in psychology and computer vision, we use segmentations from a pre-trained model to stably locate across timesteps, various entities in the scene, capturing where information. To each such segmented entity, we apply other pre-trained models that build vector descriptions suitable for robotic control tasks, thus capturing what the entity is. Thus, our pre-trained object-centric representations for control are constructed by appropriately combining the outputs of off-the-shelf pre-trained models, with no new training. On various simulated and real robotic tasks, we show that imitation policies for robotic manipulators trained on POCR achieve better performance and systematic generalization than state of the art pre-trained representations for robotics, as well as prior object-centric representations that are typically trained from scratch.
Read more4/23/2024
0
How structured are the representations in transformer-based vision encoders? An analysis of multi-object representations in vision-language models
Tarun Khajuria, Braian Olmiro Dias, Jaan Aru
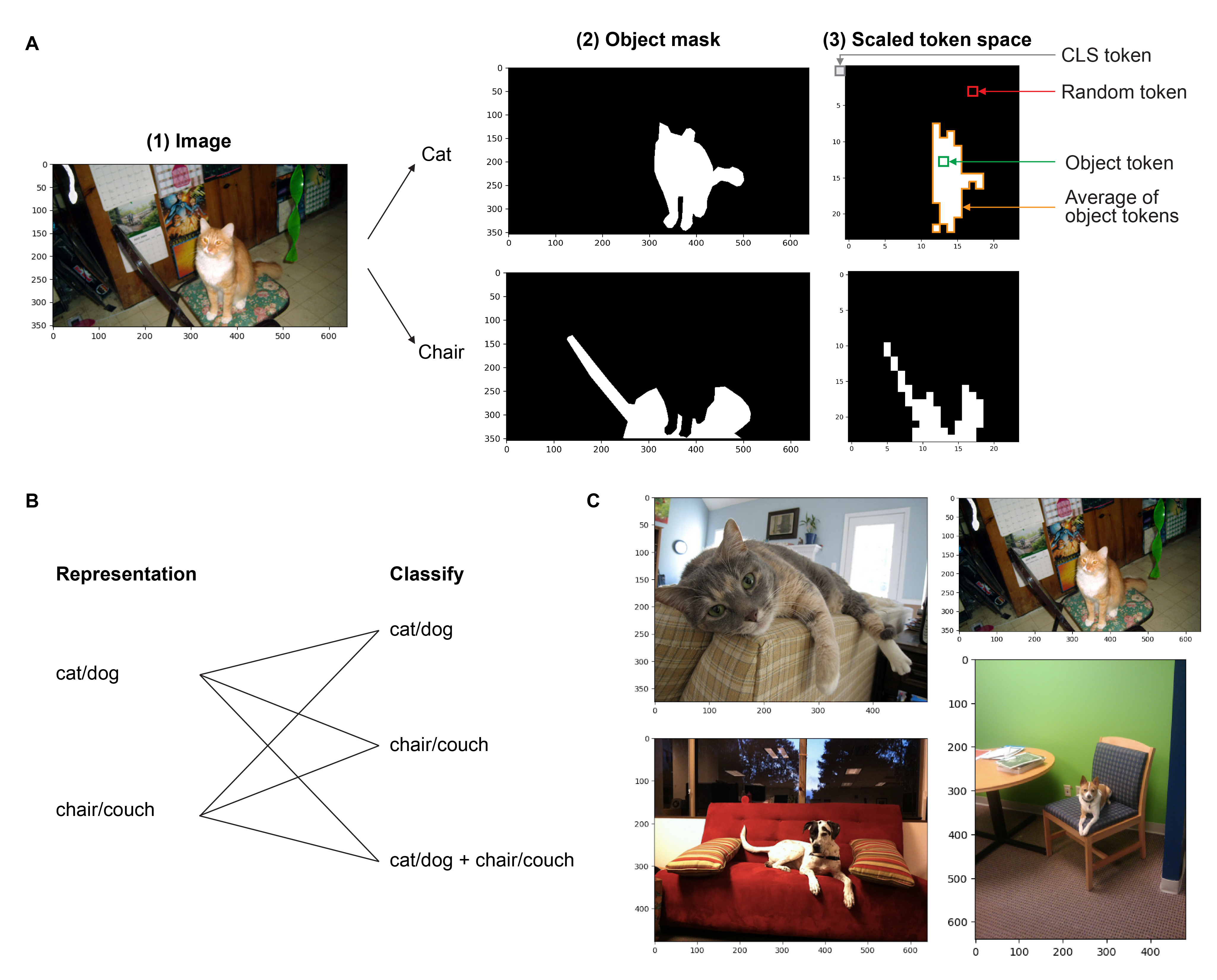
Forming and using symbol-like structured representations for reasoning has been considered essential for generalising over novel inputs. The primary tool that allows generalisation outside training data distribution is the ability to abstract away irrelevant information into a compact form relevant to the task. An extreme form of such abstract representations is symbols. Humans make use of symbols to bind information while abstracting away irrelevant parts to utilise the information consistently and meaningfully. This work estimates the state of such structured representations in vision encoders. Specifically, we evaluate image encoders in large vision-language pre-trained models to address the question of which desirable properties their representations lack by applying the criteria of symbolic structured reasoning described for LLMs to the image models. We test the representation space of image encoders like VIT, BLIP, CLIP, and FLAVA to characterise the distribution of the object representations in these models. In particular, we create decoding tasks using multi-object scenes from the COCO dataset, relating the token space to its input content for various objects in the scene. We use these tasks to characterise the network's token and layer-wise information modelling. Our analysis highlights that the CLS token, used for the downstream task, only focuses on a few objects necessary for the trained downstream task. Still, other individual objects are well-modelled separately by the tokens in the network originating from those objects. We further observed a widespread distribution of scene information. This demonstrates that information is far more entangled in tokens than optimal for representing objects similar to symbols. Given these symbolic properties, we show the network dynamics that cause failure modes of these models on basic downstream tasks in a multi-object scene.
Read more6/19/2024

0
3D-MVP: 3D Multiview Pretraining for Robotic Manipulation
Shengyi Qian, Kaichun Mo, Valts Blukis, David F. Fouhey, Dieter Fox, Ankit Goyal
Recent works have shown that visual pretraining on egocentric datasets using masked autoencoders (MAE) can improve generalization for downstream robotics tasks. However, these approaches pretrain only on 2D images, while many robotics applications require 3D scene understanding. In this work, we propose 3D-MVP, a novel approach for 3D multi-view pretraining using masked autoencoders. We leverage Robotic View Transformer (RVT), which uses a multi-view transformer to understand the 3D scene and predict gripper pose actions. We split RVT's multi-view transformer into visual encoder and action decoder, and pretrain its visual encoder using masked autoencoding on large-scale 3D datasets such as Objaverse. We evaluate 3D-MVP on a suite of virtual robot manipulation tasks and demonstrate improved performance over baselines. We also show promising results on a real robot platform with minimal finetuning. Our results suggest that 3D-aware pretraining is a promising approach to improve sample efficiency and generalization of vision-based robotic manipulation policies. We will release code and pretrained models for 3D-MVP to facilitate future research. Project site: https://jasonqsy.github.io/3DMVP
Read more6/27/2024