3D-MVP: 3D Multiview Pretraining for Robotic Manipulation

0

Sign in to get full access
Overview
- This paper introduces 3D-MVP, a framework for pretraining robotic manipulation models using 3D multiview data.
- 3D-MVP leverages multiple views of 3D objects and scenes to learn robust representations that can be fine-tuned for specific robotic tasks.
- The authors demonstrate the effectiveness of 3D-MVP on a range of manipulation tasks, outperforming prior approaches.
Plain English Explanation
The 3D-MVP framework aims to help robots learn how to manipulate objects more effectively. It does this by first training the robot on a large dataset of 3D objects and scenes viewed from multiple angles. This allows the robot to build up a detailed understanding of 3D shapes and spatial relationships, which can then be applied to specific manipulation tasks.
By seeing objects from different viewpoints, the robot can learn robust representations that are not dependent on any single perspective. This is similar to how humans and animals build up a rich 3D understanding of the world by integrating information from our eyes, hands, and other senses.
The authors show that this multiview pretraining approach outperforms other methods on a variety of robotic manipulation benchmarks. This suggests that 3D-MVP could be a powerful tool for enabling more capable and adaptable robot manipulators. The insights from this work could also inform the development of more general "multimodal" AI systems that can fluidly combine vision, language, and physical interaction.
Technical Explanation
The core of the 3D-MVP framework is a self-supervised pretraining approach that leverages multiview 3D data. The model is trained to predict the relative poses between different views of the same 3D scene or object. This forces the network to learn a rich 3D representation that can capture the underlying geometry and spatial structure.
After this pretraining stage, the learned representations are fine-tuned on specific robotic manipulation tasks, such as pick-and-place or tool use. The authors experiment with different fine-tuning strategies, including freezing or unfreezing various layers of the network.
The experiments demonstrate that 3D-MVP outperforms prior methods like RVT-2, SPATP, and MVTN on a range of benchmarks. This suggests that the multiview pretraining approach is an effective way to bootstrap robotic manipulation capabilities.
Critical Analysis
The authors acknowledge that 3D-MVP relies on having access to a large dataset of multiview 3D data, which may not always be available in real-world scenarios. They propose extending the framework to leverage other modalities like language and RGB images to mitigate this limitation.
Additionally, while the results demonstrate impressive performance, the paper does not provide a detailed analysis of the types of manipulation skills the model has learned. Further investigation is needed to understand the model's strengths, weaknesses, and the transferability of its representations to novel tasks.
It would also be valuable to see comparisons to alternative pretraining strategies, such as self-supervised learning on video data or reinforcement learning from interaction. Combining 3D-MVP with these other approaches could potentially lead to even more capable and generalizable robotic manipulation models.
Conclusion
Overall, the 3D-MVP framework represents an important advance in robotic manipulation, showing how multiview 3D pretraining can bootstrap the learning of rich, transferable representations. By integrating insights from computer vision, robotics, and representation learning, this work opens up new possibilities for building more versatile and capable robot manipulators. As the field continues to progress, techniques like 3D-MVP will likely play an increasingly important role in bridging the gap between the physical and digital worlds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3D-MVP: 3D Multiview Pretraining for Robotic Manipulation
Shengyi Qian, Kaichun Mo, Valts Blukis, David F. Fouhey, Dieter Fox, Ankit Goyal
Recent works have shown that visual pretraining on egocentric datasets using masked autoencoders (MAE) can improve generalization for downstream robotics tasks. However, these approaches pretrain only on 2D images, while many robotics applications require 3D scene understanding. In this work, we propose 3D-MVP, a novel approach for 3D multi-view pretraining using masked autoencoders. We leverage Robotic View Transformer (RVT), which uses a multi-view transformer to understand the 3D scene and predict gripper pose actions. We split RVT's multi-view transformer into visual encoder and action decoder, and pretrain its visual encoder using masked autoencoding on large-scale 3D datasets such as Objaverse. We evaluate 3D-MVP on a suite of virtual robot manipulation tasks and demonstrate improved performance over baselines. We also show promising results on a real robot platform with minimal finetuning. Our results suggest that 3D-aware pretraining is a promising approach to improve sample efficiency and generalization of vision-based robotic manipulation policies. We will release code and pretrained models for 3D-MVP to facilitate future research. Project site: https://jasonqsy.github.io/3DMVP
Read more6/27/2024
0
P3P: Pseudo-3D Pre-training for Scaling 3D Masked Autoencoders
Xuechao Chen, Ying Chen, Jialin Li, Qiang Nie, Yong Liu, Qixing Huang, Yang Li
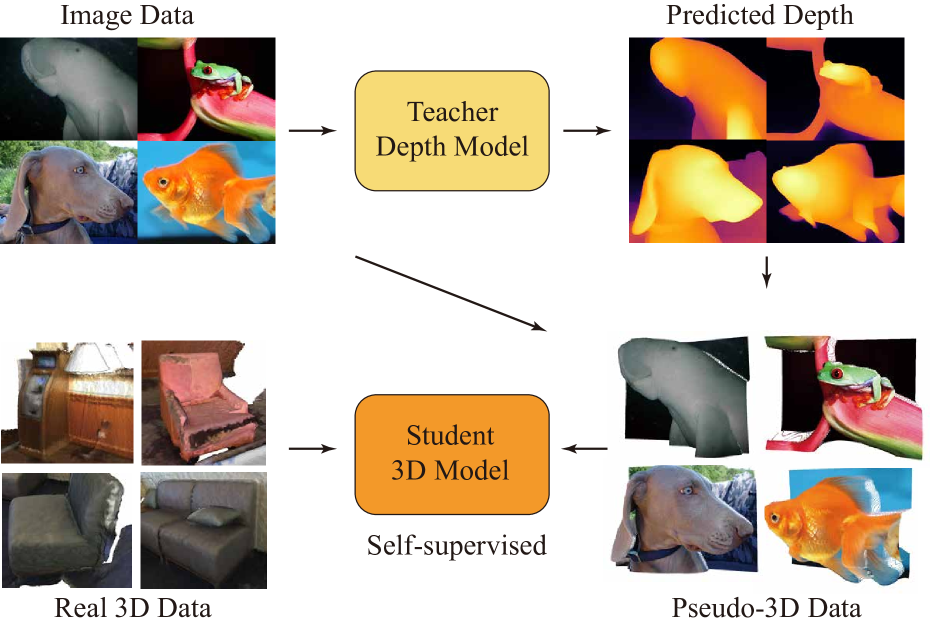
3D pre-training is crucial to 3D perception tasks. However, limited by the difficulties in collecting clean 3D data, 3D pre-training consistently faced data scaling challenges. Inspired by semi-supervised learning leveraging limited labeled data and a large amount of unlabeled data, in this work, we propose a novel self-supervised pre-training framework utilizing the real 3D data and the pseudo-3D data lifted from images by a large depth estimation model. Another challenge lies in the efficiency. Previous methods such as Point-BERT and Point-MAE, employ k nearest neighbors to embed 3D tokens, requiring quadratic time complexity. To efficiently pre-train on such a large amount of data, we propose a linear-time-complexity token embedding strategy and a training-efficient 2D reconstruction target. Our method achieves state-of-the-art performance in 3D classification and few-shot learning while maintaining high pre-training and downstream fine-tuning efficiency.
Read more8/20/2024
0
RVT-2: Learning Precise Manipulation from Few Demonstrations
Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu-Wei Chao, Dieter Fox
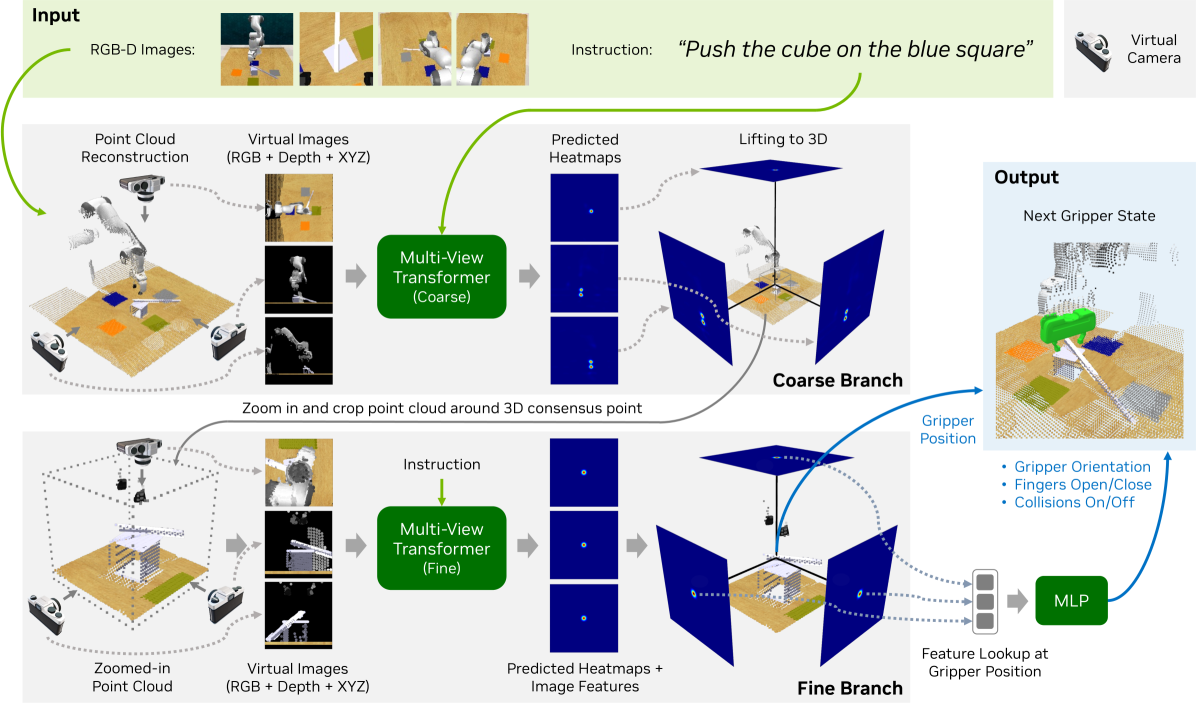
In this work, we study how to build a robotic system that can solve multiple 3D manipulation tasks given language instructions. To be useful in industrial and household domains, such a system should be capable of learning new tasks with few demonstrations and solving them precisely. Prior works, like PerAct and RVT, have studied this problem, however, they often struggle with tasks requiring high precision. We study how to make them more effective, precise, and fast. Using a combination of architectural and system-level improvements, we propose RVT-2, a multitask 3D manipulation model that is 6X faster in training and 2X faster in inference than its predecessor RVT. RVT-2 achieves a new state-of-the-art on RLBench, improving the success rate from 65% to 82%. RVT-2 is also effective in the real world, where it can learn tasks requiring high precision, like picking up and inserting plugs, with just 10 demonstrations. Visual results, code, and trained model are provided at: https://robotic-view-transformer-2.github.io/.
Read more6/14/2024
🤔
0
MVTN: Learning Multi-View Transformations for 3D Understanding
Abdullah Hamdi, Faisal AlZahrani, Silvio Giancola, Bernard Ghanem
Multi-view projection techniques have shown themselves to be highly effective in achieving top-performing results in the recognition of 3D shapes. These methods involve learning how to combine information from multiple view-points. However, the camera view-points from which these views are obtained are often fixed for all shapes. To overcome the static nature of current multi-view techniques, we propose learning these view-points. Specifically, we introduce the Multi-View Transformation Network (MVTN), which uses differentiable rendering to determine optimal view-points for 3D shape recognition. As a result, MVTN can be trained end-to-end with any multi-view network for 3D shape classification. We integrate MVTN into a novel adaptive multi-view pipeline that is capable of rendering both 3D meshes and point clouds. Our approach demonstrates state-of-the-art performance in 3D classification and shape retrieval on several benchmarks (ModelNet40, ScanObjectNN, ShapeNet Core55). Further analysis indicates that our approach exhibits improved robustness to occlusion compared to other methods. We also investigate additional aspects of MVTN, such as 2D pretraining and its use for segmentation. To support further research in this area, we have released MVTorch, a PyTorch library for 3D understanding and generation using multi-view projections.
Read more6/7/2024