How structured are the representations in transformer-based vision encoders? An analysis of multi-object representations in vision-language models

0
Sign in to get full access
Overview
- This paper investigates the structured representations in transformer-based vision encoders, with a focus on analyzing multi-object representations in vision-language models.
- The researchers aim to understand how well these models capture the relationships between multiple objects in an image.
- The findings shed light on the level of abstraction and structure in the internal representations of vision-language models.
Plain English Explanation
Transformer-based vision encoders are a type of artificial intelligence (AI) model that can analyze and understand images. These models are often used in vision-language tasks, where the AI needs to interpret both visual and textual information.
In this research, the authors wanted to see how well these vision encoders can capture the relationships between different objects in an image. Do they represent each object separately, or do they also understand how the objects are connected and interact with each other?
To do this, the researchers designed experiments to probe the internal workings of these models. They found that the models do have some structured representations of multiple objects, but there is still room for improvement in terms of fully understanding the complex relationships between elements in an image.
This work provides valuable insights into the strengths and limitations of current vision-language models. By understanding how these models represent and process visual information, researchers can work to refine skewed perceptions in vision-language models and broaden their visual encoding capabilities.
Technical Explanation
The paper examines the internal representations of transformer-based vision encoders, specifically focusing on how they capture multi-object relationships in images. The researchers use a combination of visualization techniques and probing experiments to analyze the structured representations within these models.
They find that while the vision encoders do exhibit some level of structured representations, there are still limitations in how well they can model the complex relationships between multiple objects in an image. The models tend to represent objects more as independent entities rather than fully capturing the context and interactions between them.
The researchers draw insights from this analysis, suggesting that further work is needed to develop more interpretable representations and better object-level context in vision-language models. This could involve recasting generic pretrained vision transformers to better handle multi-object scenes.
Critical Analysis
The paper provides a valuable contribution to understanding the internal workings of transformer-based vision encoders. However, it acknowledges some limitations in its approach, such as the use of a relatively small dataset and the focus on a limited set of model architectures.
Additionally, the experiments are primarily designed to test the models' ability to represent multi-object relationships, but there may be other aspects of structured representation that are not fully explored. The paper could have delved deeper into the implications of its findings for real-world applications of vision-language models.
Overall, the research raises important questions about the level of abstraction and structure in the representations learned by these models. Further work is needed to develop more comprehensive and robust methods for understanding and improving the representations in transformer-based vision encoders.
Conclusion
This study sheds light on the structured representations in transformer-based vision encoders, particularly in the context of multi-object relationships. The findings suggest that while these models exhibit some level of structured representations, there is still room for improvement in terms of fully capturing the complex interactions between objects in an image.
The insights from this research can inform future efforts to refine the perceptions and broaden the visual encoding capabilities of vision-language models. By better understanding the internal representations of these models, researchers can work towards developing more robust and interpretable AI systems that can more effectively process and understand visual information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How structured are the representations in transformer-based vision encoders? An analysis of multi-object representations in vision-language models
Tarun Khajuria, Braian Olmiro Dias, Jaan Aru
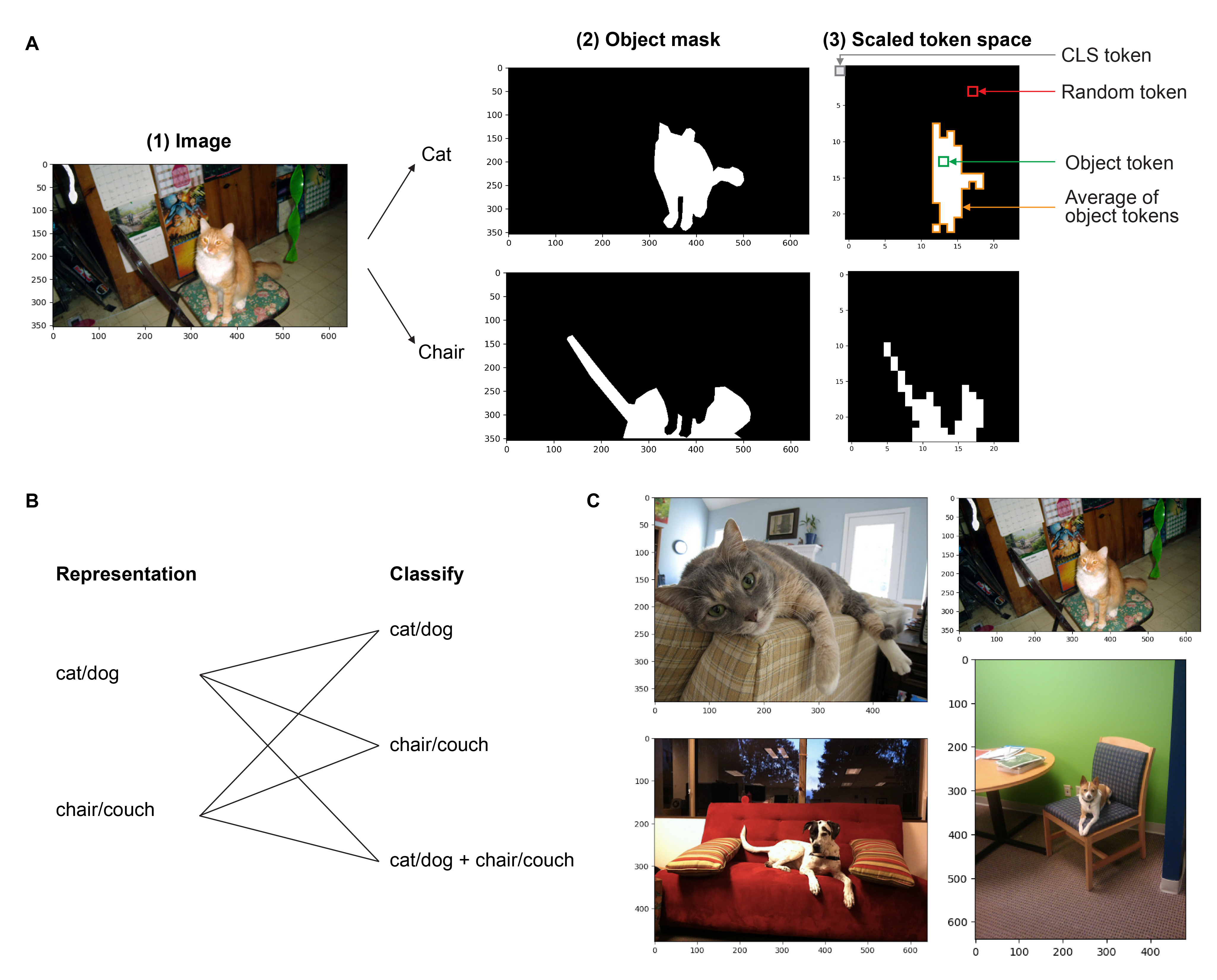
Forming and using symbol-like structured representations for reasoning has been considered essential for generalising over novel inputs. The primary tool that allows generalisation outside training data distribution is the ability to abstract away irrelevant information into a compact form relevant to the task. An extreme form of such abstract representations is symbols. Humans make use of symbols to bind information while abstracting away irrelevant parts to utilise the information consistently and meaningfully. This work estimates the state of such structured representations in vision encoders. Specifically, we evaluate image encoders in large vision-language pre-trained models to address the question of which desirable properties their representations lack by applying the criteria of symbolic structured reasoning described for LLMs to the image models. We test the representation space of image encoders like VIT, BLIP, CLIP, and FLAVA to characterise the distribution of the object representations in these models. In particular, we create decoding tasks using multi-object scenes from the COCO dataset, relating the token space to its input content for various objects in the scene. We use these tasks to characterise the network's token and layer-wise information modelling. Our analysis highlights that the CLS token, used for the downstream task, only focuses on a few objects necessary for the trained downstream task. Still, other individual objects are well-modelled separately by the tokens in the network originating from those objects. We further observed a widespread distribution of scene information. This demonstrates that information is far more entangled in tokens than optimal for representing objects similar to symbols. Given these symbolic properties, we show the network dynamics that cause failure modes of these models on basic downstream tasks in a multi-object scene.
Read more6/19/2024
🔍
0
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
Read more5/24/2024

0
Explaining Vision-Language Similarities in Dual Encoders with Feature-Pair Attributions
Lucas Moller, Pascal Tilli, Ngoc Thang Vu, Sebastian Pad'o
Dual encoder architectures like CLIP models map two types of inputs into a shared embedding space and learn similarities between them. However, it is not understood how such models compare two inputs. Here, we address this research gap with two contributions. First, we derive a method to attribute predictions of any differentiable dual encoder onto feature-pair interactions between its inputs. Second, we apply our method to CLIP-type models and show that they learn fine-grained correspondences between parts of captions and regions in images. They match objects across input modes and also account for mismatches. However, this visual-linguistic grounding ability heavily varies between object classes, depends on the training data distribution, and largely improves after in-domain training. Using our method we can identify knowledge gaps about specific object classes in individual models and can monitor their improvement upon fine-tuning.
Read more8/27/2024

0
BRAVE: Broadening the visual encoding of vision-language models
Ou{g}uzhan Fatih Kar, Alessio Tonioni, Petra Poklukar, Achin Kulshrestha, Amir Zamir, Federico Tombari
Vision-language models (VLMs) are typically composed of a vision encoder, e.g. CLIP, and a language model (LM) that interprets the encoded features to solve downstream tasks. Despite remarkable progress, VLMs are subject to several shortcomings due to the limited capabilities of vision encoders, e.g. blindness to certain image features, visual hallucination, etc. To address these issues, we study broadening the visual encoding capabilities of VLMs. We first comprehensively benchmark several vision encoders with different inductive biases for solving VLM tasks. We observe that there is no single encoding configuration that consistently achieves top performance across different tasks, and encoders with different biases can perform surprisingly similarly. Motivated by this, we introduce a method, named BRAVE, that consolidates features from multiple frozen encoders into a more versatile representation that can be directly fed as the input to a frozen LM. BRAVE achieves state-of-the-art performance on a broad range of captioning and VQA benchmarks and significantly reduces the aforementioned issues of VLMs, while requiring a smaller number of trainable parameters than existing methods and having a more compressed representation. Our results highlight the potential of incorporating different visual biases for a more broad and contextualized visual understanding of VLMs.
Read more4/11/2024