Reciprocal Attention Mixing Transformer for Lightweight Image Restoration

0
🖼️
Sign in to get full access
Overview
- Recent image restoration (IR) methods often have too many parameters
- Most Transformer-based IR methods focus on either local or global features, leading to limited receptive fields or parameter issues
- To address these problems, the authors propose a lightweight IR network called Reciprocal Attention Mixing Transformer (RAMiT)
Plain English Explanation
The paper discusses a new approach to image restoration called Reciprocal Attention Mixing Transformer (RAMiT). Image restoration is the process of improving the quality of an image, such as by reducing noise or enhancing details. Many recent image restoration methods use a lot of parameters, which can make them computationally expensive and difficult to deploy. Additionally, most Transformer-based image restoration methods [1] [2] focus on either local or global features, which can limit their effectiveness.
To address these issues, the authors of this paper developed RAMiT, a lightweight image restoration network. RAMiT uses a novel component called the Dimensional Reciprocal Attention Mixing Transformer (D-RAMiT) block, which computes spatial and channel-wise attention in parallel. This helps the network capture both local and global features more effectively. The authors also introduced a Hierarchical Reciprocal Attention Mixing (H-RAMi) layer, which compensates for pixel-level information losses and utilizes semantic information while maintaining an efficient hierarchical structure.
Furthermore, the authors modified the popular MobileNet V1 and V2 architectures to create a more efficient version of RAMiT. The results show that RAMiT achieves state-of-the-art performance on a variety of lightweight image restoration tasks, including super-resolution, denoising, low-light enhancement, and deraining.
Technical Explanation
The core of the RAMiT network is the Dimensional Reciprocal Attention Mixing Transformer (D-RAMiT) block, which computes spatial and channel-wise self-attention in parallel using different numbers of attention heads. This allows the network to capture both local and global features more effectively than methods that focus on only one type of attention.
The authors also introduce a Hierarchical Reciprocal Attention Mixing (H-RAMi) layer, which compensates for pixel-level information losses and utilizes semantic information while maintaining an efficient hierarchical structure. This helps the network retain important details while still being lightweight.
To further improve efficiency, the authors revisit and modify the MobileNet V1 and V2 architectures to create a more efficient version of RAMiT. They attach the efficient convolutions from MobileNet to the D-RAMiT and H-RAMi components.
The experimental results demonstrate that RAMiT achieves state-of-the-art performance on multiple lightweight image restoration tasks, including super-resolution, color denoising, grayscale denoising, low-light enhancement, and deraining. The authors also provide code for their work, which can be found at https://github.com/rami0205/RAMiT.
Critical Analysis
The authors have addressed an important issue in the field of image restoration by proposing a lightweight network that can effectively capture both local and global features. The use of the D-RAMiT and H-RAMi components is a novel approach that seems to offer performance benefits without significantly increasing the number of parameters.
However, the paper does not provide much discussion on the limitations or potential drawbacks of the RAMiT approach. For example, it would be useful to know how the network performs on more challenging or diverse datasets, or how it compares to other state-of-the-art lightweight IR methods in terms of factors like inference time and memory usage.
Additionally, the authors could have explored the possibility of further architectural optimizations or the incorporation of additional techniques, such as attention-based methods, to enhance the network's efficiency and performance even further.
Overall, the RAMiT approach appears to be a promising contribution to the field of image restoration, but more comprehensive evaluation and analysis could help strengthen the findings and provide a clearer picture of the method's strengths and weaknesses.
Conclusion
The Reciprocal Attention Mixing Transformer (RAMiT) proposed in this paper is a novel and lightweight image restoration network that addresses the limitations of existing methods. By using a Dimensional Reciprocal Attention Mixing Transformer (D-RAMiT) block and a Hierarchical Reciprocal Attention Mixing (H-RAMi) layer, RAMiT is able to effectively capture both local and global features while maintaining an efficient architectural design.
The experimental results demonstrate that RAMiT achieves state-of-the-art performance on a variety of lightweight image restoration tasks, including super-resolution, denoising, low-light enhancement, and deraining. This work represents an important step forward in developing efficient and effective image restoration solutions that can be deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Reciprocal Attention Mixing Transformer for Lightweight Image Restoration
Haram Choi, Cheolwoong Na, Jihyeon Oh, Seungjae Lee, Jinseop Kim, Subeen Choe, Jeongmin Lee, Taehoon Kim, Jihoon Yang
Although many recent works have made advancements in the image restoration (IR) field, they often suffer from an excessive number of parameters. Another issue is that most Transformer-based IR methods focus only on either local or global features, leading to limited receptive fields or deficient parameter issues. To address these problems, we propose a lightweight IR network, Reciprocal Attention Mixing Transformer (RAMiT). It employs our proposed dimensional reciprocal attention mixing Transformer (D-RAMiT) blocks, which compute bi-dimensional (spatial and channel) self-attentions in parallel with different numbers of multi-heads. The bi-dimensional attentions help each other to complement their counterpart's drawbacks and are then mixed. Additionally, we introduce a hierarchical reciprocal attention mixing (H-RAMi) layer that compensates for pixel-level information losses and utilizes semantic information while maintaining an efficient hierarchical structure. Furthermore, we revisit and modify MobileNet V1 and V2 to attach efficient convolutions to our proposed components. The experimental results demonstrate that RAMiT achieves state-of-the-art performance on multiple lightweight IR tasks, including super-resolution, color denoising, grayscale denoising, low-light enhancement, and deraining. Codes are available at https://github.com/rami0205/RAMiT.
Read more4/19/2024

0
LIR: A Lightweight Baseline for Image Restoration
Dongqi Fan, Ting Yue, Xin Zhao, Renjing Xu, Liang Chang
Recently, there have been significant advancements in Image Restoration based on CNN and transformer. However, the inherent characteristics of the Image Restoration task are often overlooked in many works. They, instead, tend to focus on the basic block design and stack numerous such blocks to the model, leading to parameters redundant and computations unnecessary. Thus, the efficiency of the image restoration is hindered. In this paper, we propose a Lightweight Baseline network for Image Restoration called LIR to efficiently restore the image and remove degradations. First of all, through an ingenious structural design, LIR removes the degradations existing in the local and global residual connections that are ignored by modern networks. Then, a Lightweight Adaptive Attention (LAA) Block is introduced which is mainly composed of proposed Adaptive Filters and Attention Blocks. The proposed Adaptive Filter is used to adaptively extract high-frequency information and enhance object contours in various IR tasks, and Attention Block involves a novel Patch Attention module to approximate the self-attention part of the transformer. On the deraining task, our LIR achieves the state-of-the-art Structure Similarity Index Measure (SSIM) and comparable performance to state-of-the-art models on Peak Signal-to-Noise Ratio (PSNR). For denoising, dehazing, and deblurring tasks, LIR also achieves a comparable performance to state-of-the-art models with a parameter size of about 30%. In addition, it is worth noting that our LIR produces better visual results that are more in line with the human aesthetic.
Read more6/26/2024
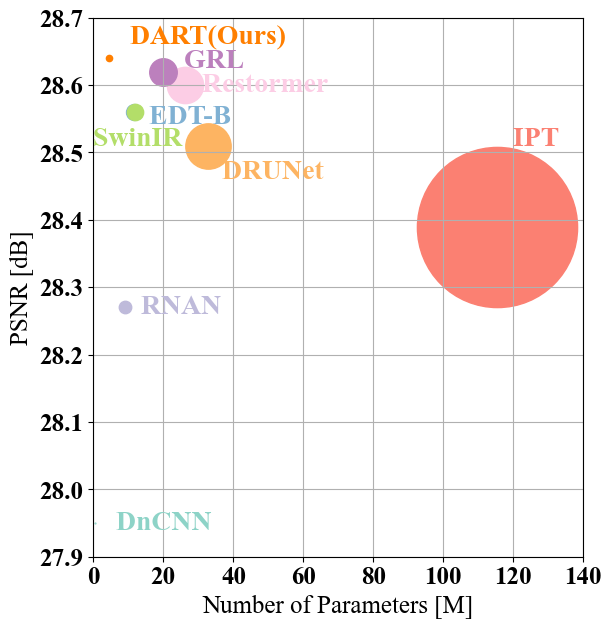
0
Empowering Image Recovery_ A Multi-Attention Approach
Juan Wen, Yawei Li, Chao Zhang, Weiyan Hou, Radu Timofte, Luc Van Gool
We propose Diverse Restormer (DART), a novel image restoration method that effectively integrates information from various sources (long sequences, local and global regions, feature dimensions, and positional dimensions) to address restoration challenges. While Transformer models have demonstrated excellent performance in image restoration due to their self-attention mechanism, they face limitations in complex scenarios. Leveraging recent advancements in Transformers and various attention mechanisms, our method utilizes customized attention mechanisms to enhance overall performance. DART, our novel network architecture, employs windowed attention to mimic the selective focusing mechanism of human eyes. By dynamically adjusting receptive fields, it optimally captures the fundamental features crucial for image resolution reconstruction. Efficiency and performance balance are achieved through the LongIR attention mechanism for long sequence image restoration. Integration of attention mechanisms across feature and positional dimensions further enhances the recovery of fine details. Evaluation across five restoration tasks consistently positions DART at the forefront. Upon acceptance, we commit to providing publicly accessible code and models to ensure reproducibility and facilitate further research.
Read more4/10/2024

0
Sharing Key Semantics in Transformer Makes Efficient Image Restoration
Bin Ren, Yawei Li, Jingyun Liang, Rakesh Ranjan, Mengyuan Liu, Rita Cucchiara, Luc Van Gool, Ming-Hsuan Yang, Nicu Sebe
Image Restoration (IR), a classic low-level vision task, has witnessed significant advancements through deep models that effectively model global information. Notably, the Vision Transformers (ViTs) emergence has further propelled these advancements. When computing, the self-attention mechanism, a cornerstone of ViTs, tends to encompass all global cues, even those from semantically unrelated objects or regions. This inclusivity introduces computational inefficiencies, particularly noticeable with high input resolution, as it requires processing irrelevant information, thereby impeding efficiency. Additionally, for IR, it is commonly noted that small segments of a degraded image, particularly those closely aligned semantically, provide particularly relevant information to aid in the restoration process, as they contribute essential contextual cues crucial for accurate reconstruction. To address these challenges, we propose boosting IR's performance by sharing the key semantics via Transformer for IR (i.e., SemanIR) in this paper. Specifically, SemanIR initially constructs a sparse yet comprehensive key-semantic dictionary within each transformer stage by establishing essential semantic connections for every degraded patch. Subsequently, this dictionary is shared across all subsequent transformer blocks within the same stage. This strategy optimizes attention calculation within each block by focusing exclusively on semantically related components stored in the key-semantic dictionary. As a result, attention calculation achieves linear computational complexity within each window. Extensive experiments across 6 IR tasks confirm the proposed SemanIR's state-of-the-art performance, quantitatively and qualitatively showcasing advancements.
Read more5/31/2024