ReCLIP++: Learn to Rectify the Bias of CLIP for Unsupervised Semantic Segmentation

0
Sign in to get full access
Overview
- This research paper presents ReCLIP++, a method for learning to rectify the bias of the CLIP model for unsupervised semantic segmentation.
- The key ideas are using a contrastive loss to learn a rectification of the CLIP representations and applying this to improve performance on unsupervised semantic segmentation.
- The proposed approach demonstrates strong results on several benchmarks, outperforming previous state-of-the-art methods for unsupervised semantic segmentation.
Plain English Explanation
ReCLIP++: Learn to Rectify the Bias of CLIP for Unsupervised Semantic Segmentation is a research paper that introduces a new method for improving the performance of CLIP, a popular vision-language model, on the task of unsupervised semantic segmentation.
Semantic segmentation is the process of dividing an image into meaningful regions or "segments," such as identifying the different objects, people, or structures present. Unsupervised semantic segmentation means doing this without any labeled training data, which can be challenging.
The key insight of this research is that the CLIP model, while powerful, has certain biases that can limit its effectiveness for segmentation. The researchers developed a technique called "ReCLIP++" that learns to "rectify" or correct these biases, leading to better segmentation results.
The core idea is to use a "contrastive loss" - a type of machine learning objective that encourages the model to distinguish between related and unrelated image-text pairs. By applying this loss to the CLIP representations, the researchers were able to learn a rectification that improved the model's ability to segment images into semantically meaningful regions.
Through experiments on several benchmark datasets, the authors show that ReCLIP++ outperforms previous state-of-the-art methods for unsupervised semantic segmentation. This suggests the approach is an effective way to leverage the power of CLIP while overcoming some of its inherent limitations.
Technical Explanation
ReCLIP++: Learn to Rectify the Bias of CLIP for Unsupervised Semantic Segmentation presents a new method for improving the performance of the CLIP model on the task of unsupervised semantic segmentation.
The key components of the ReCLIP++ approach are:
-
Contrastive Loss: The researchers use a contrastive loss to learn a rectification of the CLIP representations. This loss encourages the model to distinguish between related and unrelated image-text pairs, which helps correct biases in the original CLIP representations.
-
Rectification Module: ReCLIP++ includes a rectification module that takes the CLIP representations as input and outputs a rectified version that is better suited for segmentation tasks.
-
Unsupervised Segmentation: The rectified CLIP representations are then used as input to an unsupervised segmentation model, such as a clustering algorithm, to produce the final segmentation results.
The authors evaluate ReCLIP++ on several benchmark datasets for unsupervised semantic segmentation, including Pascal VOC, COCO, and ADE20K. They show that ReCLIP++ outperforms previous state-of-the-art methods, demonstrating the effectiveness of the proposed rectification approach.
Critical Analysis
The ReCLIP++ paper makes a valuable contribution to the field of unsupervised semantic segmentation by leveraging the power of CLIP while addressing some of its limitations.
One potential limitation of the approach is that it relies on the quality and biases of the pre-trained CLIP model. If CLIP has significant biases or shortcomings, the rectification module may not be able to fully correct for them. The authors acknowledge this and suggest that further research into improving the underlying CLIP model could be beneficial.
Additionally, the paper focuses on evaluating ReCLIP++ on standard benchmark datasets, which may not capture the full range of real-world challenges faced by unsupervised segmentation systems. Exploring the performance of ReCLIP++ on more diverse or challenging datasets could provide additional insights.
Overall, the ReCLIP++ paper presents a promising approach for leveraging large-scale vision-language models like CLIP for unsupervised semantic segmentation. The authors' careful evaluation and analysis of the method's strengths and limitations provide a solid foundation for future research in this area.
Conclusion
ReCLIP++: Learn to Rectify the Bias of CLIP for Unsupervised Semantic Segmentation introduces a novel method for improving the performance of the CLIP model on the task of unsupervised semantic segmentation. By leveraging a contrastive loss to learn a rectification of the CLIP representations, the researchers were able to significantly outperform previous state-of-the-art approaches on several benchmark datasets.
The key contribution of this work is demonstrating the effectiveness of using vision-language models like CLIP as a starting point for unsupervised segmentation tasks, while also addressing the inherent biases and limitations of these models. This approach has the potential to unlock new applications and capabilities for large-scale vision-language models, paving the way for further advancements in unsupervised perception and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ReCLIP++: Learn to Rectify the Bias of CLIP for Unsupervised Semantic Segmentation
Jingyun Wang, Guoliang Kang
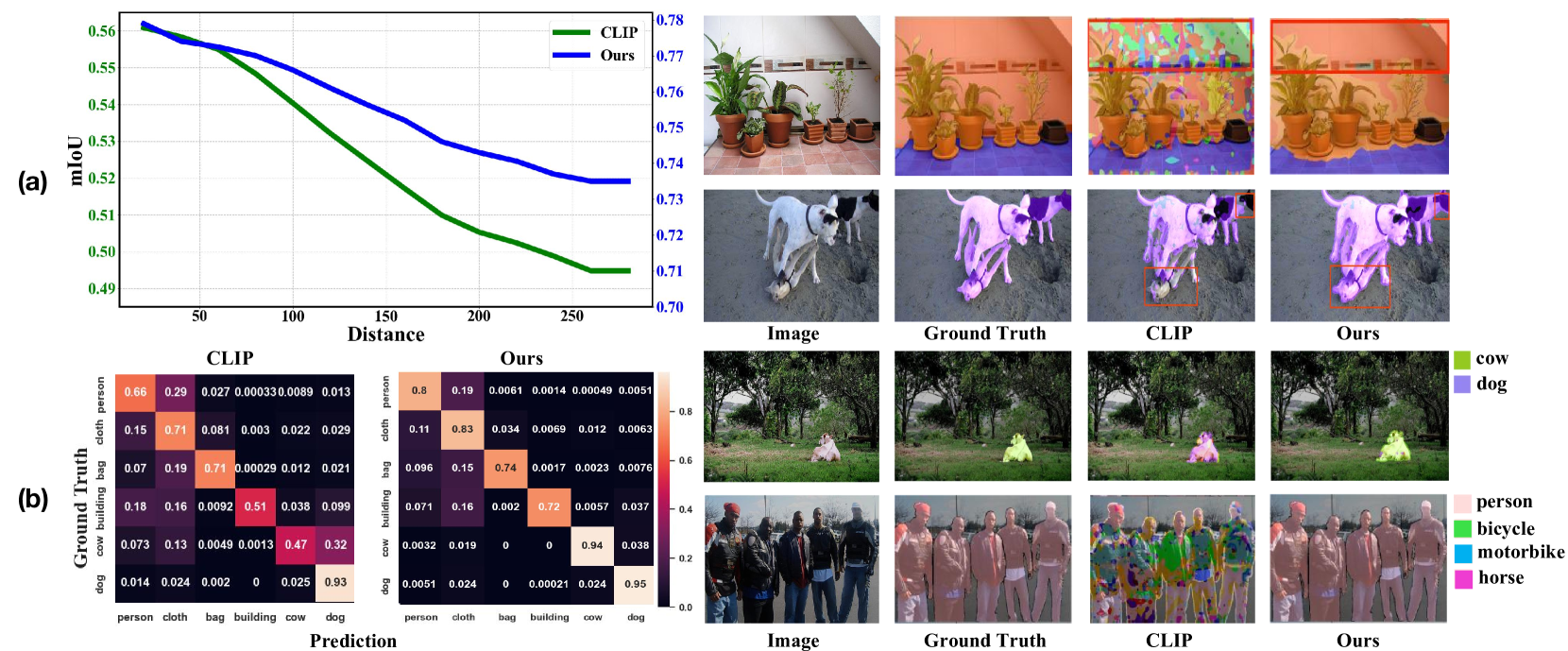
Recent works utilize CLIP to perform the challenging unsupervised semantic segmentation task where only images without annotations are available. However, we observe that when adopting CLIP to such a pixel-level understanding task, unexpected bias (including class-preference bias and space-preference bias) occurs. Previous works don't explicitly model the bias, which largely constrains the segmentation performance. In this paper, we propose to explicitly model and rectify the bias existing in CLIP to facilitate the unsupervised semantic segmentation task. Specifically, we design a learnable ''Reference'' prompt to encode class-preference bias and a projection of the positional embedding in vision transformer to encode space-preference bias respectively. To avoid interference, two kinds of biases are firstly independently encoded into the Reference feature and the positional feature. Via a matrix multiplication between two features, a bias logit map is generated to explicitly represent two kinds of biases. Then we rectify the logits of CLIP via a simple element-wise subtraction. To make the rectified results smoother and more contextual, we design a mask decoder which takes the feature of CLIP and rectified logits as input and outputs a rectified segmentation mask with the help of Gumbel-Softmax operation. To make the bias modeling and rectification process meaningful and effective, a contrastive loss based on masked visual features and the text features of different classes is imposed. To further improve the segmentation, we distill the knowledge from the rectified CLIP to the advanced segmentation architecture via minimizing our designed mask-guided, feature-guided and text-guided loss terms. Extensive experiments on various benchmarks demonstrate that ReCLIP++ performs favorably against previous SOTAs. The implementation is available at: https://github.com/dogehhh/ReCLIP.
Read more8/14/2024
🧪
0
TagCLIP: Improving Discrimination Ability of Open-Vocabulary Semantic Segmentation
Jingyao Li, Pengguang Chen, Shengju Qian, Shu Liu, Jiaya Jia
Contrastive Language-Image Pre-training (CLIP) has recently shown great promise in pixel-level zero-shot learning tasks. However, existing approaches utilizing CLIP's text and patch embeddings to generate semantic masks often misidentify input pixels from unseen classes, leading to confusion between novel classes and semantically similar ones. In this work, we propose a novel approach, TagCLIP (Trusty-aware guided CLIP), to address this issue. We disentangle the ill-posed optimization problem into two parallel processes: semantic matching performed individually and reliability judgment for improving discrimination ability. Building on the idea of special tokens in language modeling representing sentence-level embeddings, we introduce a trusty token that enables distinguishing novel classes from known ones in prediction. To evaluate our approach, we conduct experiments on two benchmark datasets, PASCAL VOC 2012, COCO-Stuff 164K and PASCAL Context. Our results show that TagCLIP improves the Intersection over Union (IoU) of unseen classes by 7.4%, 1.7% and 2.1%, respectively, with negligible overheads. The code is available at https://github.com/dvlab-research/TagCLIP.
Read more9/4/2024

0
ClearCLIP: Decomposing CLIP Representations for Dense Vision-Language Inference
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, Wayne Zhang
Despite the success of large-scale pretrained Vision-Language Models (VLMs) especially CLIP in various open-vocabulary tasks, their application to semantic segmentation remains challenging, producing noisy segmentation maps with mis-segmented regions. In this paper, we carefully re-investigate the architecture of CLIP, and identify residual connections as the primary source of noise that degrades segmentation quality. With a comparative analysis of statistical properties in the residual connection and the attention output across different pretrained models, we discover that CLIP's image-text contrastive training paradigm emphasizes global features at the expense of local discriminability, leading to noisy segmentation results. In response, we propose ClearCLIP, a novel approach that decomposes CLIP's representations to enhance open-vocabulary semantic segmentation. We introduce three simple modifications to the final layer: removing the residual connection, implementing the self-self attention, and discarding the feed-forward network. ClearCLIP consistently generates clearer and more accurate segmentation maps and outperforms existing approaches across multiple benchmarks, affirming the significance of our discoveries.
Read more7/18/2024
🛸
0
Rethinking Prior Information Generation with CLIP for Few-Shot Segmentation
Jin Wang, Bingfeng Zhang, Jian Pang, Honglong Chen, Weifeng Liu
Few-shot segmentation remains challenging due to the limitations of its labeling information for unseen classes. Most previous approaches rely on extracting high-level feature maps from the frozen visual encoder to compute the pixel-wise similarity as a key prior guidance for the decoder. However, such a prior representation suffers from coarse granularity and poor generalization to new classes since these high-level feature maps have obvious category bias. In this work, we propose to replace the visual prior representation with the visual-text alignment capacity to capture more reliable guidance and enhance the model generalization. Specifically, we design two kinds of training-free prior information generation strategy that attempts to utilize the semantic alignment capability of the Contrastive Language-Image Pre-training model (CLIP) to locate the target class. Besides, to acquire more accurate prior guidance, we build a high-order relationship of attention maps and utilize it to refine the initial prior information. Experiments on both the PASCAL-5{i} and COCO-20{i} datasets show that our method obtains a clearly substantial improvement and reaches the new state-of-the-art performance.
Read more5/15/2024