TagCLIP: Improving Discrimination Ability of Open-Vocabulary Semantic Segmentation

0
🧪
Sign in to get full access
Overview
- Contrastive Language-Image Pre-training (CLIP) has shown great promise in pixel-level zero-shot learning tasks.
- Existing approaches using CLIP's text and patch embeddings often misidentify input pixels from unseen classes, leading to confusion between novel classes and semantically similar ones.
- This paper proposes a novel approach, TagCLIP, to address this issue.
Plain English Explanation
Contrastive Language-Image Pre-training (CLIP) is a powerful machine learning technique that can perform zero-shot learning – it can recognize objects in images that it hasn't been specifically trained on. However, current CLIP-based methods sometimes get confused and misidentify objects from unseen classes (classes the model hasn't been trained on) as being similar to known classes.
The researchers in this paper developed a new approach called TagCLIP to address this issue. The key idea is to add a special "trusty token" to the CLIP model, which helps it better distinguish novel classes from known ones. This token acts as a kind of reliability signal, allowing the model to be more confident in its predictions for unfamiliar objects.
Technical Explanation
The paper proposes a novel approach called TagCLIP (Trusty-aware guided CLIP) to improve the performance of CLIP-based models on zero-shot learning tasks.
The core innovation is to disentangle the optimization problem into two parallel processes:
- Semantic matching performed individually
- Reliability judgment for improving discrimination ability
Building on the idea of special tokens in language modeling representing sentence-level embeddings, the researchers introduce a trusty token that enables the model to better distinguish novel classes from known ones during prediction.
The authors evaluate TagCLIP on PASCAL VOC 2012, COCO-Stuff 164K, and PASCAL Context benchmark datasets. Their results show that TagCLIP improves the Intersection over Union (IoU) of unseen classes by 7.4%, 1.7%, and 2.1%, respectively, with negligible computational overhead.
Critical Analysis
The paper presents a thoughtful approach to addressing a key limitation of existing CLIP-based models – their tendency to confuse novel classes with semantically similar known classes during zero-shot learning tasks. The introduction of the trusty token is a clever way to inject a reliability signal into the model's predictions, helping it better distinguish unfamiliar objects.
However, the paper does not discuss potential limitations or caveats of the TagCLIP approach. For example, it's unclear how the trusty token mechanism would scale to a large number of novel classes, or how it might perform in more complex, real-world scenarios. Additionally, the paper could have delved deeper into the inner workings of the trusty token and how it interacts with the other components of the CLIP model.
Overall, the research is a valuable contribution to the field of zero-shot learning, and the TagCLIP approach shows promise for improving the robustness and reliability of CLIP-based models. Further exploration of the method's limitations and potential extensions would be a natural next step for the researchers.
Conclusion
This paper introduces a novel approach called TagCLIP that addresses a key limitation of existing CLIP-based models – their tendency to confuse novel classes with semantically similar known classes during zero-shot learning tasks. By disentangling the optimization problem and introducing a trusty token, TagCLIP is able to significantly improve the performance of CLIP on unseen class recognition, with negligible computational overhead.
The research represents an important step forward in enhancing the reliability and robustness of zero-shot learning systems, which have numerous practical applications in fields like computer vision and image understanding. While the paper could have explored potential limitations and future directions in more depth, the TagCLIP approach is a valuable contribution to the ongoing efforts to push the boundaries of what's possible with CLIP and similar powerful language-vision models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
TagCLIP: Improving Discrimination Ability of Open-Vocabulary Semantic Segmentation
Jingyao Li, Pengguang Chen, Shengju Qian, Shu Liu, Jiaya Jia
Contrastive Language-Image Pre-training (CLIP) has recently shown great promise in pixel-level zero-shot learning tasks. However, existing approaches utilizing CLIP's text and patch embeddings to generate semantic masks often misidentify input pixels from unseen classes, leading to confusion between novel classes and semantically similar ones. In this work, we propose a novel approach, TagCLIP (Trusty-aware guided CLIP), to address this issue. We disentangle the ill-posed optimization problem into two parallel processes: semantic matching performed individually and reliability judgment for improving discrimination ability. Building on the idea of special tokens in language modeling representing sentence-level embeddings, we introduce a trusty token that enables distinguishing novel classes from known ones in prediction. To evaluate our approach, we conduct experiments on two benchmark datasets, PASCAL VOC 2012, COCO-Stuff 164K and PASCAL Context. Our results show that TagCLIP improves the Intersection over Union (IoU) of unseen classes by 7.4%, 1.7% and 2.1%, respectively, with negligible overheads. The code is available at https://github.com/dvlab-research/TagCLIP.
Read more9/4/2024

0
Explore the Potential of CLIP for Training-Free Open Vocabulary Semantic Segmentation
Tong Shao, Zhuotao Tian, Hang Zhao, Jingyong Su
CLIP, as a vision-language model, has significantly advanced Open-Vocabulary Semantic Segmentation (OVSS) with its zero-shot capabilities. Despite its success, its application to OVSS faces challenges due to its initial image-level alignment training, which affects its performance in tasks requiring detailed local context. Our study delves into the impact of CLIP's [CLS] token on patch feature correlations, revealing a dominance of global patches that hinders local feature discrimination. To overcome this, we propose CLIPtrase, a novel training-free semantic segmentation strategy that enhances local feature awareness through recalibrated self-correlation among patches. This approach demonstrates notable improvements in segmentation accuracy and the ability to maintain semantic coherence across objects.Experiments show that we are 22.3% ahead of CLIP on average on 9 segmentation benchmarks, outperforming existing state-of-the-art training-free methods.The code are made publicly available at: https://github.com/leaves162/CLIPtrase.
Read more7/12/2024
⛏️
0
Tuning-free Universally-Supervised Semantic Segmentation
Xiaobo Yang, Xiaojin Gong
This work presents a tuning-free semantic segmentation framework based on classifying SAM masks by CLIP, which is universally applicable to various types of supervision. Initially, we utilize CLIP's zero-shot classification ability to generate pseudo-labels or perform open-vocabulary segmentation. However, the misalignment between mask and CLIP text embeddings leads to suboptimal results. To address this issue, we propose discrimination-bias aligned CLIP to closely align mask and text embedding, offering an overhead-free performance gain. We then construct a global-local consistent classifier to classify SAM masks, which reveals the intrinsic structure of high-quality embeddings produced by DBA-CLIP and demonstrates robustness against noisy pseudo-labels. Extensive experiments validate the efficiency and effectiveness of our method, and we achieve state-of-the-art (SOTA) or competitive performance across various datasets and supervision types.
Read more5/24/2024
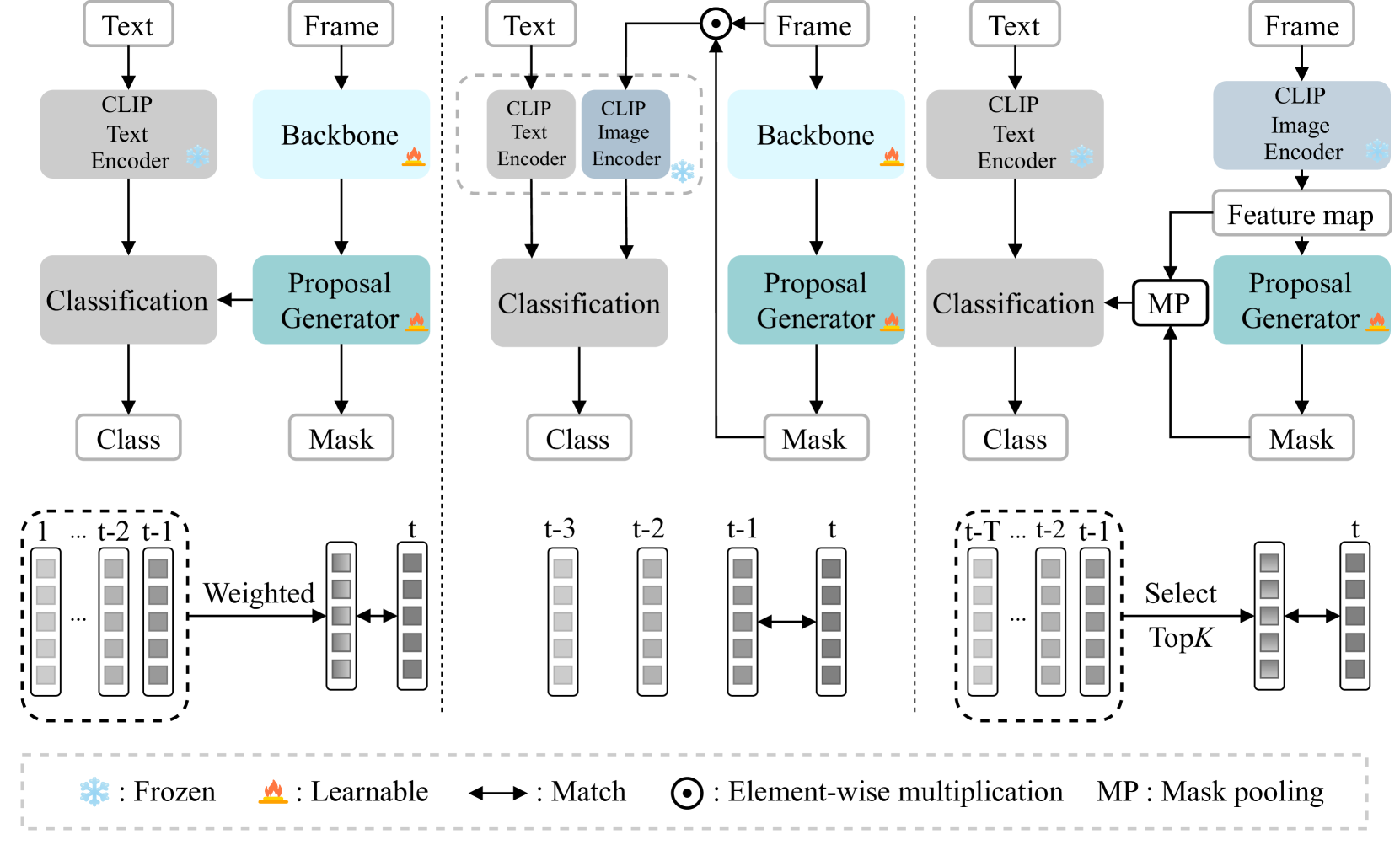
0
CLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Wenqi Zhu, Jiale Cao, Jin Xie, Shuangming Yang, Yanwei Pang
Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown robust zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores.Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.2% and 40.2% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.1% and 23.9% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.
Read more6/11/2024