Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization

0
Sign in to get full access
Overview
- The paper examines the benefits and drawbacks of using reconstruction error minimization (REM) for pruning large language models (LLMs).
- REM aims to reduce the size of LLMs by removing or "pruning" parameters that have little impact on the model's performance.
- The paper suggests that while REM can lead to significant model compression, it may also result in unintended consequences, such as reduced performance on downstream tasks.
Plain English Explanation
The paper looks at a technique called reconstruction error minimization (REM) that is used to make large language models [object Object]. Large language models are powerful AI systems that can understand and generate human-like text. However, they can also be very large and resource-intensive to use.
REM tries to identify parts of the model that aren't contributing much to its overall performance and removes or "prunes" them. This can [object Object] and make it faster and cheaper to use. However, the paper suggests that this pruning process can also have some downsides. It may [object Object] on certain tasks, even if the overall accuracy is maintained.
The paper aims to provide a more nuanced understanding of the tradeoffs involved in using REM for pruning large language models. It highlights both the benefits and potential pitfalls, so that researchers and developers can make more informed decisions about how to optimize these powerful AI systems.
Technical Explanation
The paper evaluates the use of reconstruction error minimization (REM) as a technique for pruning large language models (LLMs). REM aims to identify and remove parameters in the model that have little impact on its overall performance, thereby reducing the model's size and complexity.
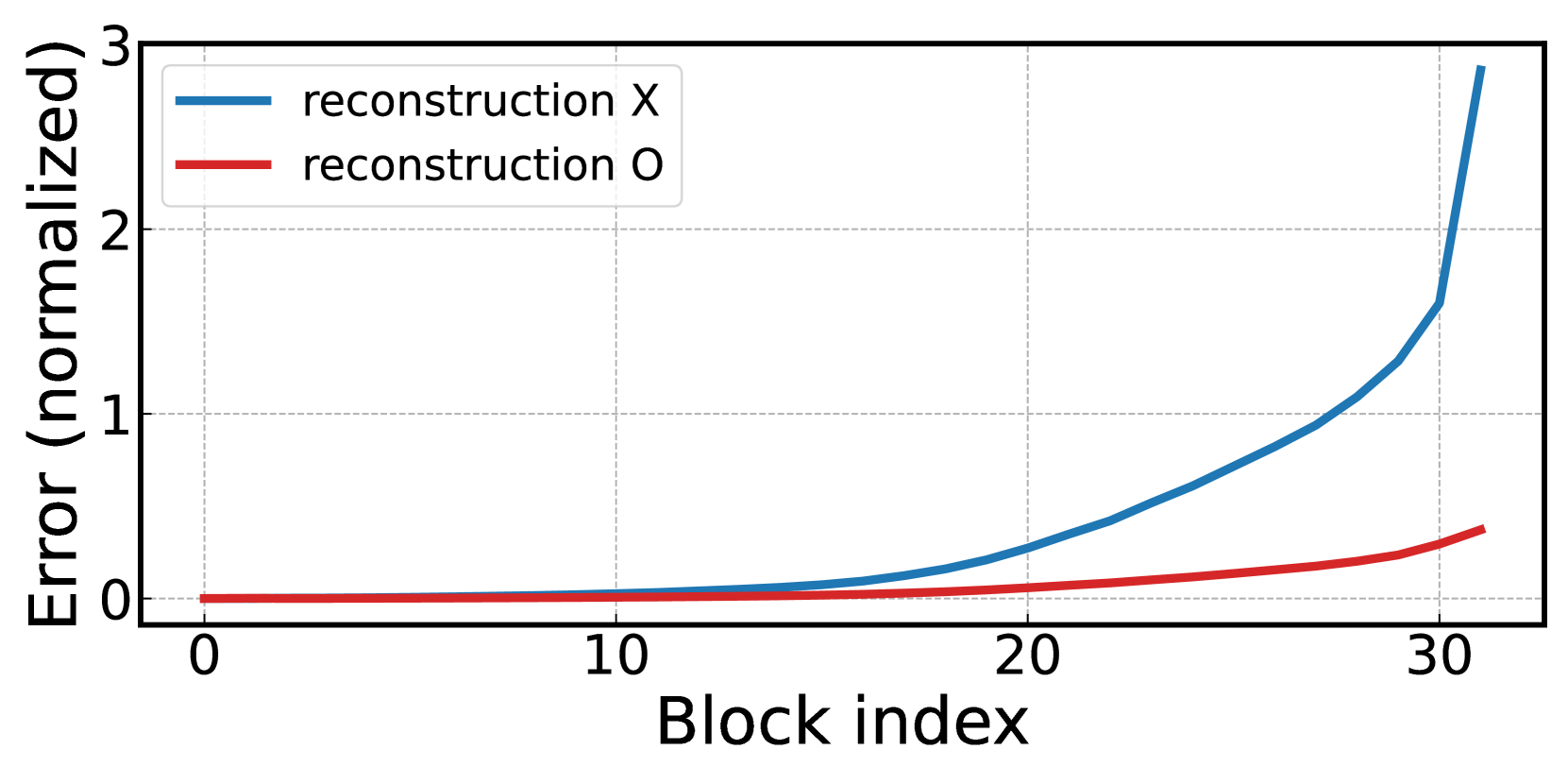
The key idea behind REM is to train a smaller "reconstruction" model that can accurately reproduce the original model's outputs, even with parameters removed. By minimizing the difference between the original model's outputs and the reconstruction model's outputs, REM can identify which parameters are the least important and can be safely pruned without significantly degrading the model's performance.
The paper presents a series of experiments that explore the benefits and drawbacks of this approach. The authors find that REM can indeed lead to substantial model compression, with [object Object] without significantly impacting the model's perplexity (a measure of its language modeling ability).
However, the paper also identifies several potential issues with REM-based pruning. For example, the authors observe that while REM may preserve the model's overall perplexity, it can [object Object], such as question answering or sentiment analysis. This suggests that the reconstruction error may not be a perfect proxy for the model's true utility.
The paper also highlights the importance of careful evaluation and selection of the reconstruction model architecture, as well as the potential need for additional fine-tuning or task-specific pruning to optimize the model's performance across a range of applications.
Critical Analysis
The paper provides a nuanced and valuable analysis of the potential benefits and pitfalls of using reconstruction error minimization (REM) for pruning large language models (LLMs). The authors' findings suggest that while REM can lead to significant model compression, it may not be a panacea for optimizing LLMs for real-world applications.
One of the key insights from the paper is that minimizing reconstruction error does not necessarily translate to preserving a model's performance on downstream tasks. This is an important caveat that developers and researchers should keep in mind when considering REM-based pruning approaches. The paper encourages a more holistic evaluation of pruning techniques, going beyond just measures of perplexity or reconstruction error.
The paper also highlights the need for further research to better understand the relationship between a model's internal representations and its performance on specific tasks. Developing more robust and task-relevant pruning techniques may require a deeper understanding of how LLMs encode and process information.
Additionally, the paper suggests that the choice of reconstruction model architecture can significantly impact the effectiveness of REM-based pruning. This underscores the importance of careful experimentation and model selection when applying these techniques.
Overall, the paper makes a valuable contribution to the ongoing discussion around [object Object]. By identifying both the benefits and potential pitfalls of REM, it encourages a more nuanced and thoughtful approach to model optimization, with a focus on preserving the model's real-world utility rather than just its raw performance metrics.
Conclusion
The paper provides a critical examination of using reconstruction error minimization (REM) for pruning large language models (LLMs). While REM can lead to significant model compression, the authors' findings suggest that it may not be a panacea for optimizing LLMs for real-world applications.
The key insights from the paper are:
- REM can reduce model size by up to 80% without significantly impacting perplexity, a measure of language modeling ability.
- However, REM-pruned models may exhibit reduced performance on downstream tasks, such as question answering or sentiment analysis.
- The choice of reconstruction model architecture is crucial and can significantly impact the effectiveness of REM-based pruning.
- A more holistic evaluation of pruning techniques, beyond just perplexity or reconstruction error, is needed to ensure the optimized models maintain their real-world utility.
These findings highlight the importance of carefully considering the tradeoffs and potential unintended consequences when applying pruning techniques to LLMs. By providing a nuanced perspective, the paper encourages researchers and developers to explore more robust and task-relevant optimization approaches for these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
Sungbin Shin, Wonpyo Park, Jaeho Lee, Namhoon Lee
This work suggests fundamentally rethinking the current practice of pruning large language models (LLMs). The way it is done is by divide and conquer: split the model into submodels, sequentially prune them, and reconstruct predictions of the dense counterparts on small calibration data one at a time; the final model is obtained simply by putting the resulting sparse submodels together. While this approach enables pruning under memory constraints, it generates high reconstruction errors. In this work, we first present an array of reconstruction techniques that can significantly reduce this error by more than $90%$. Unwittingly, however, we discover that minimizing reconstruction error is not always ideal and can overfit the given calibration data, resulting in rather increased language perplexity and poor performance at downstream tasks. We find out that a strategy of self-generating calibration data can mitigate this trade-off between reconstruction and generalization, suggesting new directions in the presence of both benefits and pitfalls of reconstruction for pruning LLMs.
Read more6/26/2024
0
Reconstruct the Pruned Model without Any Retraining
Pingjie Wang, Ziqing Fan, Shengchao Hu, Zhe Chen, Yanfeng Wang, Yu Wang
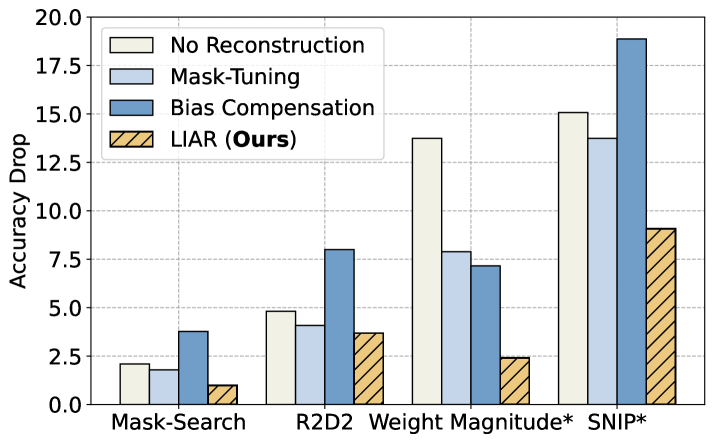
Structured pruning is a promising hardware-friendly compression technique for large language models (LLMs), which is expected to be retraining-free to avoid the enormous retraining cost. This retraining-free paradigm involves (1) pruning criteria to define the architecture and (2) distortion reconstruction to restore performance. However, existing methods often emphasize pruning criteria while using reconstruction techniques that are specific to certain modules or criteria, resulting in limited generalizability. To address this, we introduce the Linear Interpolation-based Adaptive Reconstruction (LIAR) framework, which is both efficient and effective. LIAR does not require back-propagation or retraining and is compatible with various pruning criteria and modules. By applying linear interpolation to the preserved weights, LIAR minimizes reconstruction error and effectively reconstructs the pruned output. Our evaluations on benchmarks such as GLUE, SQuAD, WikiText, and common sense reasoning show that LIAR enables a BERT model to maintain 98% accuracy even after removing 50% of its parameters and achieves top performance for LLaMA in just a few minutes.
Read more7/19/2024

0
Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
Read more5/16/2024

0
Compact Language Models via Pruning and Knowledge Distillation
Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov
Large language models (LLMs) targeting different deployment scales and sizes are currently produced by training each variant from scratch; this is extremely compute-intensive. In this paper, we investigate if pruning an existing LLM and then re-training it with a fraction (<3%) of the original training data can be a suitable alternative to repeated, full retraining. To this end, we develop a set of practical and effective compression best practices for LLMs that combine depth, width, attention and MLP pruning with knowledge distillation-based retraining; we arrive at these best practices through a detailed empirical exploration of pruning strategies for each axis, methods to combine axes, distillation strategies, and search techniques for arriving at optimal compressed architectures. We use this guide to compress the Nemotron-4 family of LLMs by a factor of 2-4x, and compare their performance to similarly-sized models on a variety of language modeling tasks. Deriving 8B and 4B models from an already pretrained 15B model using our approach requires up to 40x fewer training tokens per model compared to training from scratch; this results in compute cost savings of 1.8x for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. We have open-sourced Minitron model weights on Huggingface, with corresponding supplementary material including example code available on GitHub.
Read more7/23/2024