Reconstructing Training Data From Real World Models Trained with Transfer Learning

0

Sign in to get full access
Overview
- Researchers investigated a technique called "reconstruction" to extract the original training data used to create real-world AI models trained with transfer learning.
- The paper explores the feasibility and limitations of this approach, which could have implications for data privacy and transparency in machine learning.
Plain English Explanation
Imagine you have a really good AI model that can do all sorts of impressive tasks, like recognizing images or generating human-like text. This AI model was trained on a huge dataset, but the details of that dataset are often kept secret by the company or researchers who developed the model.
The researchers in this paper wanted to see if they could reverse-engineer the original training data used to create these AI models. They used a technique called "reconstruction" to try to rebuild the training data from the AI model itself.
The key idea is that the AI model has "learned" something about the original training data, and this knowledge is "stored" in the model's parameters (the numbers that define how the model works). By analyzing the model, the researchers hoped they could uncover clues about what the original training data looked like.
This research is important because it raises questions about data privacy and transparency in machine learning. If it's possible to reconstruct the training data from an AI model, that could have implications for how companies and researchers share their models and data in the future.
Technical Explanation
The researchers focused on "transfer learning," a common technique where an AI model is first trained on a large, general dataset, and then "fine-tuned" on a smaller, more specific dataset. This allows the model to leverage knowledge from the initial training to perform better on the new task.
The researchers developed a reconstruction technique that aims to extract information about the original training data used for the initial, general model. They did this by analyzing the model's parameters and structure, and trying to find patterns that could be matched back to the original data.
Specifically, the researchers used a method called "mixture-of-low-rank-experts," which models the AI model as a combination of simpler "expert" sub-models, each of which may capture different aspects of the original training data. By analyzing these expert sub-models, the researchers could try to reconstruct the properties of the original dataset.
The researchers tested their reconstruction approach on several real-world AI models, including models for image classification and language modeling. They found that in some cases, they were able to extract meaningful information about the original training data, such as the distribution of image classes or the types of text documents used.
However, the researchers also acknowledge the limitations of their approach. Reconstructing the full original training data is an extremely challenging task, and the information that can be extracted is often incomplete or noisy. The success of the reconstruction also depends on factors like the model architecture and the specifics of the transfer learning process.
Critical Analysis
The researchers raise important points about the potential privacy and transparency implications of their work. If it becomes possible to reliably reconstruct training data from AI models, this could undermine the ability of companies and researchers to protect the privacy of their data sources.
At the same time, the researchers note that their reconstruction approach has significant limitations. The amount and quality of information that can be extracted is highly dependent on the specific model and transfer learning process. In many cases, the reconstructed data may be incomplete or inaccurate.
Additionally, the researchers do not explore the broader ethical and societal implications of this type of reconstruction work. There may be valid reasons why the original training data was kept private, such as protecting the privacy of individuals or sensitive information. Indiscriminate reconstruction of training data could potentially violate these privacy concerns.
Further research is needed to better understand the capabilities and limitations of reconstruction techniques, as well as to consider the ethical frameworks that should guide this type of work. Striking the right balance between model transparency and data privacy will be an important challenge for the machine learning community going forward.
Conclusion
This paper explores a novel technique for reconstructing the original training data used to create real-world AI models that were trained using transfer learning. While the researchers were able to extract some meaningful information about the training data in certain cases, they also acknowledge the significant limitations and challenges of this approach.
The work raises important questions about data privacy and transparency in machine learning, and highlights the need for further research and ethical consideration in this area. As AI models become more sophisticated and widely deployed, understanding the tradeoffs and implications of techniques like reconstruction will be crucial for ensuring the responsible development and use of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reconstructing Training Data From Real World Models Trained with Transfer Learning
Yakir Oz, Gilad Yehudai, Gal Vardi, Itai Antebi, Michal Irani, Niv Haim
Current methods for reconstructing training data from trained classifiers are restricted to very small models, limited training set sizes, and low-resolution images. Such restrictions hinder their applicability to real-world scenarios. In this paper, we present a novel approach enabling data reconstruction in realistic settings for models trained on high-resolution images. Our method adapts the reconstruction scheme of arXiv:2206.07758 to real-world scenarios -- specifically, targeting models trained via transfer learning over image embeddings of large pre-trained models like DINO-ViT and CLIP. Our work employs data reconstruction in the embedding space rather than in the image space, showcasing its applicability beyond visual data. Moreover, we introduce a novel clustering-based method to identify good reconstructions from thousands of candidates. This significantly improves on previous works that relied on knowledge of the training set to identify good reconstructed images. Our findings shed light on a potential privacy risk for data leakage from models trained using transfer learning.
Read more7/23/2024
🛠️
0
Real3D: Scaling Up Large Reconstruction Models with Real-World Images
Hanwen Jiang, Qixing Huang, Georgios Pavlakos
The default strategy for training single-view Large Reconstruction Models (LRMs) follows the fully supervised route using large-scale datasets of synthetic 3D assets or multi-view captures. Although these resources simplify the training procedure, they are hard to scale up beyond the existing datasets and they are not necessarily representative of the real distribution of object shapes. To address these limitations, in this paper, we introduce Real3D, the first LRM system that can be trained using single-view real-world images. Real3D introduces a novel self-training framework that can benefit from both the existing synthetic data and diverse single-view real images. We propose two unsupervised losses that allow us to supervise LRMs at the pixel- and semantic-level, even for training examples without ground-truth 3D or novel views. To further improve performance and scale up the image data, we develop an automatic data curation approach to collect high-quality examples from in-the-wild images. Our experiments show that Real3D consistently outperforms prior work in four diverse evaluation settings that include real and synthetic data, as well as both in-domain and out-of-domain shapes. Code and model can be found here: https://hwjiang1510.github.io/Real3D/
Read more6/13/2024
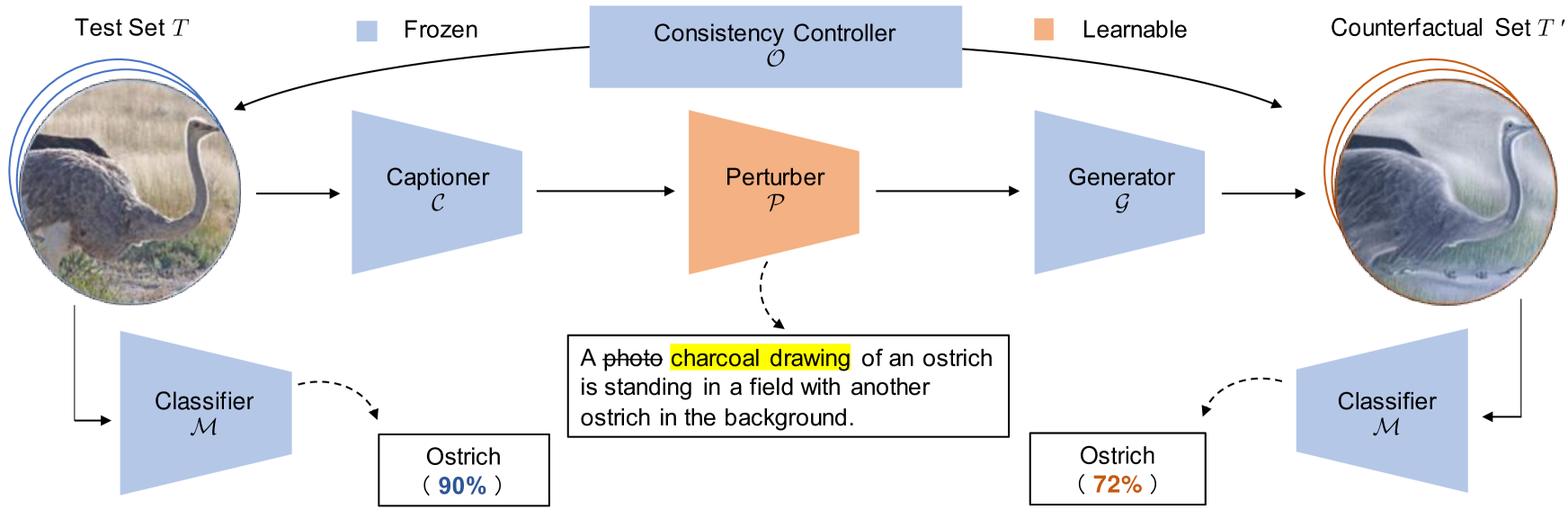
0
Reinforcing Pre-trained Models Using Counterfactual Images
Xiang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.
Read more6/21/2024

0
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Zihan Liu, Hanyi Wang, Yaoyu Kang, Shilin Wang
Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
Read more4/9/2024