ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model

0

Sign in to get full access
Overview
- ReconX is a method for reconstructing 3D scenes from sparse camera views using a video diffusion model.
- The researchers propose a novel video diffusion model that can generate high-quality 3D reconstructions from just a few input images.
- The approach is flexible and can handle a variety of scene types and camera configurations, making it a powerful tool for 3D scene understanding.
Plain English Explanation
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model is a new technique that allows you to create detailed 3D models of real-world scenes using just a handful of photographs.
The key idea is to use a video diffusion model - a type of artificial intelligence that can generate realistic video footage from scratch. By training this model on lots of 3D scenes, the researchers found that it could then reconstruct 3D models from just a few input images.
This is a significant advance over traditional 3D reconstruction methods, which often require many more images to work well. The ReconX approach is also more flexible, able to handle a wide variety of scenes and camera setups.
Overall, this research opens up new possibilities for 3D scene understanding using just a handful of photos, with applications in areas like virtual reality, robotics, and digital content creation.
Technical Explanation
The core of the ReconX approach is a video diffusion model - a type of generative AI trained on video data. By learning the patterns and structures present in real-world 3D scenes, this model can then generate novel 3D reconstructions from just a few input images.
The researchers train the video diffusion model on a large dataset of 3D scenes captured from multiple viewpoints. During inference, the model takes in a sparse set of input images and iteratively refines a 3D reconstruction, leveraging its learned understanding of scene structure.
Key innovations in the ReconX architecture include:
- Multimodal fusion: The model seamlessly integrates visual and geometric cues from the input images to guide the 3D reconstruction.
- Temporal reasoning: By modeling the 3D scene as a video sequence, the model can leverage temporal coherence to produce more consistent and realistic results.
- Flexible conditioning: The model can handle a variety of camera configurations and scene types, making it a versatile tool for 3D reconstruction.
Through extensive experiments, the researchers demonstrate that ReconX outperforms previous state-of-the-art methods for 3D reconstruction from sparse views. The generated 3D models are of high visual quality and geometric accuracy, opening up new possibilities for applications like virtual reality, robotics, and digital content creation.
Critical Analysis
The ReconX paper presents an impressive advance in 3D scene reconstruction from sparse views, but it's important to consider some potential limitations and areas for further research.
One key concern is the computational complexity of the video diffusion model, which may limit its practical deployment in real-time applications. The researchers acknowledge this challenge and suggest that future work could explore more efficient model architectures or hardware acceleration to address it.
Additionally, the paper does not provide a comprehensive evaluation of the model's performance across a diverse range of scene types and lighting conditions. Further research could investigate the ReconX model's robustness and generalization capabilities in more varied and challenging scenarios.
Another potential area for improvement is the integration of semantic understanding. The current approach primarily focuses on geometric reconstruction, but incorporating higher-level scene semantics could lead to even more realistic and meaningful 3D models.
Overall, while the ReconX paper represents an exciting step forward in 3D scene understanding, continued research and development will be necessary to fully realize its potential in real-world applications.
Conclusion
The ReconX paper introduces a novel video diffusion model that can reconstruct detailed 3D scenes from just a few input images. This represents a significant advance over traditional 3D reconstruction methods, which often require many more views to work effectively.
By leveraging the learned understanding of scene structure in the video diffusion model, the ReconX approach can produce high-quality 3D models that are flexible and adaptable to a variety of scene types and camera configurations. This opens up new possibilities for applications in areas like virtual reality, robotics, and digital content creation.
While the ReconX paper represents an exciting advance, there are still opportunities for further research and development to address potential limitations, such as computational complexity and the integration of semantic understanding. Nonetheless, this work demonstrates the power of generative AI for 3D scene reconstruction and points the way towards more accessible and efficient 3D modeling in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model
Fangfu Liu, Wenqiang Sun, Hanyang Wang, Yikai Wang, Haowen Sun, Junliang Ye, Jun Zhang, Yueqi Duan
Advancements in 3D scene reconstruction have transformed 2D images from the real world into 3D models, producing realistic 3D results from hundreds of input photos. Despite great success in dense-view reconstruction scenarios, rendering a detailed scene from insufficient captured views is still an ill-posed optimization problem, often resulting in artifacts and distortions in unseen areas. In this paper, we propose ReconX, a novel 3D scene reconstruction paradigm that reframes the ambiguous reconstruction challenge as a temporal generation task. The key insight is to unleash the strong generative prior of large pre-trained video diffusion models for sparse-view reconstruction. However, 3D view consistency struggles to be accurately preserved in directly generated video frames from pre-trained models. To address this, given limited input views, the proposed ReconX first constructs a global point cloud and encodes it into a contextual space as the 3D structure condition. Guided by the condition, the video diffusion model then synthesizes video frames that are both detail-preserved and exhibit a high degree of 3D consistency, ensuring the coherence of the scene from various perspectives. Finally, we recover the 3D scene from the generated video through a confidence-aware 3D Gaussian Splatting optimization scheme. Extensive experiments on various real-world datasets show the superiority of our ReconX over state-of-the-art methods in terms of quality and generalizability.
Read more8/30/2024
0
Sp2360: Sparse-view 360 Scene Reconstruction using Cascaded 2D Diffusion Priors
Soumava Paul, Christopher Wewer, Bernt Schiele, Jan Eric Lenssen
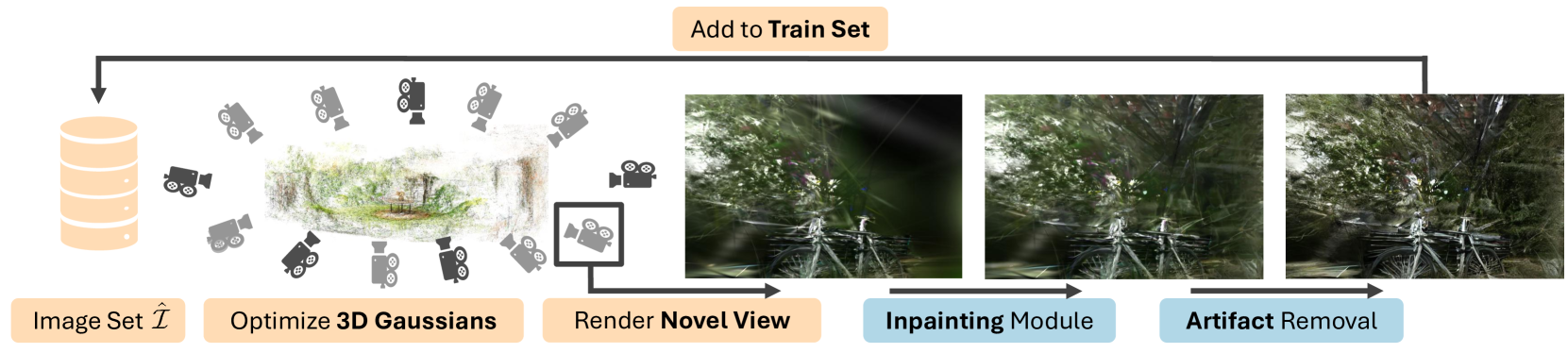
We aim to tackle sparse-view reconstruction of a 360 3D scene using priors from latent diffusion models (LDM). The sparse-view setting is ill-posed and underconstrained, especially for scenes where the camera rotates 360 degrees around a point, as no visual information is available beyond some frontal views focused on the central object(s) of interest. In this work, we show that pretrained 2D diffusion models can strongly improve the reconstruction of a scene with low-cost fine-tuning. Specifically, we present SparseSplat360 (Sp2360), a method that employs a cascade of in-painting and artifact removal models to fill in missing details and clean novel views. Due to superior training and rendering speeds, we use an explicit scene representation in the form of 3D Gaussians over NeRF-based implicit representations. We propose an iterative update strategy to fuse generated pseudo novel views with existing 3D Gaussians fitted to the initial sparse inputs. As a result, we obtain a multi-view consistent scene representation with details coherent with the observed inputs. Our evaluation on the challenging Mip-NeRF360 dataset shows that our proposed 2D to 3D distillation algorithm considerably improves the performance of a regularized version of 3DGS adapted to a sparse-view setting and outperforms existing sparse-view reconstruction methods in 360 scene reconstruction. Qualitatively, our method generates entire 360 scenes from as few as 9 input views, with a high degree of foreground and background detail.
Read more6/4/2024

0
MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
Read more6/14/2024

0
Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
Inhee Lee, Byungjun Kim, Hanbyul Joo
In this paper, we present a method to reconstruct the world and multiple dynamic humans in 3D from a monocular video input. As a key idea, we represent both the world and multiple humans via the recently emerging 3D Gaussian Splatting (3D-GS) representation, enabling to conveniently and efficiently compose and render them together. In particular, we address the scenarios with severely limited and sparse observations in 3D human reconstruction, a common challenge encountered in the real world. To tackle this challenge, we introduce a novel approach to optimize the 3D-GS representation in a canonical space by fusing the sparse cues in the common space, where we leverage a pre-trained 2D diffusion model to synthesize unseen views while keeping the consistency with the observed 2D appearances. We demonstrate our method can reconstruct high-quality animatable 3D humans in various challenging examples, in the presence of occlusion, image crops, few-shot, and extremely sparse observations. After reconstruction, our method is capable of not only rendering the scene in any novel views at arbitrary time instances, but also editing the 3D scene by removing individual humans or applying different motions for each human. Through various experiments, we demonstrate the quality and efficiency of our methods over alternative existing approaches.
Read more4/23/2024