Recurrent neural networks: vanishing and exploding gradients are not the end of the story

0

Sign in to get full access
Overview
- Recurrent neural networks (RNNs) are a type of neural network architecture commonly used for processing sequential data, such as natural language or time series.
- One of the key challenges in training RNNs is the problem of vanishing and exploding gradients, which can make it difficult for the network to learn long-term dependencies.
- This paper explores how vanishing and exploding gradients are not the end of the story for RNNs, and discusses other factors that can impact the performance of these models.
Plain English Explanation
Recurrent neural networks (RNNs) are a type of artificial intelligence model that are particularly good at processing sequential data, such as text or speech. One of the main challenges in training RNNs is the problem of vanishing and exploding gradients. This means that as the network tries to learn long-term dependencies in the data, the gradients (the signals used to update the network's parameters) can either become too small and disappear (vanishing gradients), or become too large and cause the network to diverge (exploding gradients).
However, this paper argues that vanishing and exploding gradients are not the end of the story for RNNs. There are other factors, such as the memory state space and policy gradients, that can also have a significant impact on the performance of these models. The paper explores these other factors and provides insights into how they can be addressed to improve the training and performance of RNNs.
Technical Explanation
The paper begins by discussing the well-known problem of vanishing and exploding gradients in recurrent neural networks (RNNs). As the network tries to learn long-term dependencies in sequential data, the gradients used to update the network's parameters can either become too small and disappear (vanishing gradients), or become too large and cause the network to diverge (exploding gradients). This can make it very difficult for RNNs to learn effectively.
However, the paper argues that vanishing and exploding gradients are not the only factors that can impact the performance of RNNs. The authors also explore the role of the memory state space and policy gradients in RNN training and performance.
The paper presents a series of experiments and analyses that investigate these other factors. For example, the authors analyze the state memory replay mechanism, which can help RNNs learn long-term dependencies by selectively replaying past memory states. They also explore the use of extended LSTM architectures, which can better handle the challenges of vanishing and exploding gradients.
Overall, the paper provides a more nuanced and comprehensive understanding of the factors that can impact the performance of recurrent neural networks, beyond just the well-known problem of vanishing and exploding gradients. This offers new insights and approaches for improving the training and performance of these powerful models.
Critical Analysis
The paper makes a compelling case that vanishing and exploding gradients are not the only factors that can impact the performance of recurrent neural networks (RNNs). By exploring other factors, such as the memory state space and policy gradients, the authors provide a more holistic understanding of the challenges and potential solutions for training effective RNN models.
One strength of the paper is its thorough experimental design and analysis. The authors investigate several different RNN architectures and training methods, providing a comparative study of their performance. This allows them to draw meaningful insights and conclusions about the relative importance of different factors in RNN training.
However, the paper does not delve into some of the potential limitations or caveats of the approaches it explores. For example, the use of state memory replay and extended LSTM architectures may come with their own set of challenges, such as increased computational complexity or the need for careful hyperparameter tuning. The paper could have benefited from a more in-depth discussion of these potential tradeoffs.
Additionally, the paper focuses primarily on the technical aspects of RNN training, but does not explore the broader implications or applications of this research. It would be interesting to see how the insights from this paper could be applied to real-world problems or to the development of more robust and reliable RNN-based systems.
Overall, this paper provides a valuable contribution to the understanding of recurrent neural networks and the factors that influence their performance. While it does not address all potential concerns, it offers a nuanced perspective that encourages readers to think critically about the challenges and opportunities in this important area of artificial intelligence research.
Conclusion
This paper challenges the common narrative that vanishing and exploding gradients are the primary obstacles in training effective recurrent neural networks (RNNs). The authors demonstrate that there are other significant factors, such as the memory state space and policy gradients, that can also have a substantial impact on RNN performance.
By exploring these additional factors, the paper provides a more holistic understanding of the challenges and potential solutions for training RNNs. The insights and approaches presented, such as the use of state memory replay and extended LSTM architectures, offer new avenues for researchers and practitioners to explore in their efforts to build more robust and reliable RNN-based systems.
While the paper does not address all potential limitations or implications of this research, it represents an important step forward in the understanding of recurrent neural networks. By encouraging a more nuanced and comprehensive perspective on the factors that influence RNN performance, this work lays the groundwork for future advancements in this vital area of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Recurrent neural networks: vanishing and exploding gradients are not the end of the story
Nicolas Zucchet, Antonio Orvieto
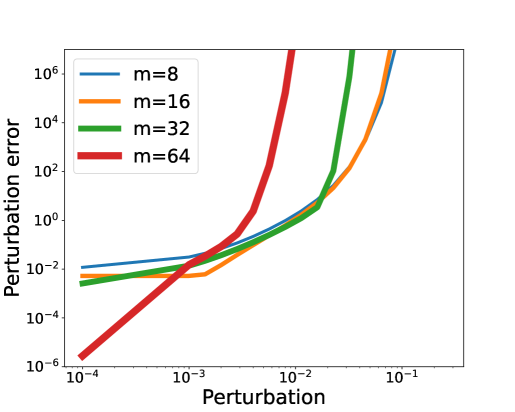
Recurrent neural networks (RNNs) notoriously struggle to learn long-term memories, primarily due to vanishing and exploding gradients. The recent success of state-space models (SSMs), a subclass of RNNs, to overcome such difficulties challenges our theoretical understanding. In this paper, we delve into the optimization challenges of RNNs and discover that, as the memory of a network increases, changes in its parameters result in increasingly large output variations, making gradient-based learning highly sensitive, even without exploding gradients. Our analysis further reveals the importance of the element-wise recurrence design pattern combined with careful parametrizations in mitigating this effect. This feature is present in SSMs, as well as in other architectures, such as LSTMs. Overall, our insights provide a new explanation for some of the difficulties in gradient-based learning of RNNs and why some architectures perform better than others.
Read more6/3/2024
0
StableSSM: Alleviating the Curse of Memory in State-space Models through Stable Reparameterization
Shida Wang, Qianxiao Li
In this paper, we investigate the long-term memory learning capabilities of state-space models (SSMs) from the perspective of parameterization. We prove that state-space models without any reparameterization exhibit a memory limitation similar to that of traditional RNNs: the target relationships that can be stably approximated by state-space models must have an exponential decaying memory. Our analysis identifies this curse of memory as a result of the recurrent weights converging to a stability boundary, suggesting that a reparameterization technique can be effective. To this end, we introduce a class of reparameterization techniques for SSMs that effectively lift its memory limitations. Besides improving approximation capabilities, we further illustrate that a principled choice of reparameterization scheme can also enhance optimization stability. We validate our findings using synthetic datasets, language models and image classifications.
Read more6/6/2024
🧠
0
On the Curse of Memory in Recurrent Neural Networks: Approximation and Optimization Analysis
Zhong Li, Jiequn Han, Weinan E, Qianxiao Li
We study the approximation properties and optimization dynamics of recurrent neural networks (RNNs) when applied to learn input-output relationships in temporal data. We consider the simple but representative setting of using continuous-time linear RNNs to learn from data generated by linear relationships. Mathematically, the latter can be understood as a sequence of linear functionals. We prove a universal approximation theorem of such linear functionals, and characterize the approximation rate and its relation with memory. Moreover, we perform a fine-grained dynamical analysis of training linear RNNs, which further reveal the intricate interactions between memory and learning. A unifying theme uncovered is the non-trivial effect of memory, a notion that can be made precise in our framework, on approximation and optimization: when there is long term memory in the target, it takes a large number of neurons to approximate it. Moreover, the training process will suffer from slow downs. In particular, both of these effects become exponentially more pronounced with memory - a phenomenon we call the curse of memory. These analyses represent a basic step towards a concrete mathematical understanding of new phenomenon that may arise in learning temporal relationships using recurrent architectures.
Read more9/2/2024
0
Recurrent Natural Policy Gradient for POMDPs
Semih Cayci, Atilla Eryilmaz
In this paper, we study a natural policy gradient method based on recurrent neural networks (RNNs) for partially-observable Markov decision processes, whereby RNNs are used for policy parameterization and policy evaluation to address curse of dimensionality in non-Markovian reinforcement learning. We present finite-time and finite-width analyses for both the critic (recurrent temporal difference learning), and correspondingly-operated recurrent natural policy gradient method in the near-initialization regime. Our analysis demonstrates the efficiency of RNNs for problems with short-term memory with explicit bounds on the required network widths and sample complexity, and points out the challenges in the case of long-term dependencies.
Read more5/29/2024