Recurrent Natural Policy Gradient for POMDPs

0
Sign in to get full access
Overview
- This paper introduces a novel algorithm called Recurrent Natural Policy Gradient (RNPG) for solving Partially Observable Markov Decision Processes (POMDPs).
- POMDPs are a type of reinforcement learning problem where the agent does not have full information about the environment's state, but must make decisions based on partial observations.
- RNPG combines the natural policy gradient algorithm with a recurrent neural network architecture to effectively learn policies for POMDP tasks.
Plain English Explanation
The paper focuses on a type of reinforcement learning problem called a Partially Observable Markov Decision Process (POMDP). In a POMDP, the agent (the decision-making entity) does not have full information about the current state of the environment. Instead, the agent only receives partial observations, which can make it challenging to choose the best action.
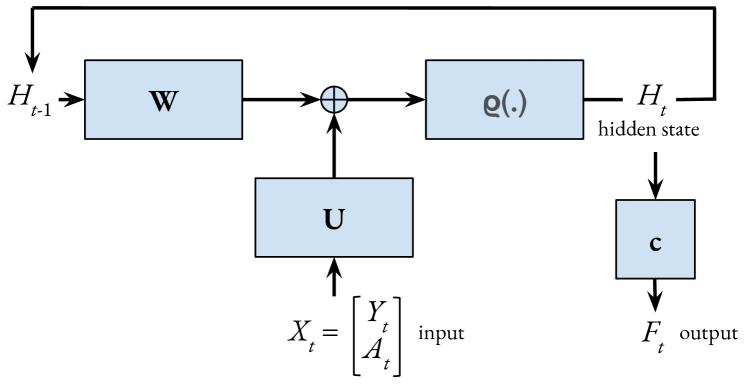
To address this challenge, the researchers developed a new algorithm called Recurrent Natural Policy Gradient (RNPG). RNPG combines two key concepts: the natural policy gradient and a recurrent neural network architecture.
The natural policy gradient is a technique that helps the agent learn more efficiently by taking into account the geometry of the policy space. This allows the agent to make updates that are more aligned with the direction that will improve the policy the most.
The recurrent neural network architecture is important because it allows the agent to maintain an internal memory or "hidden state" that can help it keep track of relevant information from past observations. This can be crucial in POMDP tasks, where the current observation alone may not be enough to determine the best action.
By combining these two elements, RNPG is able to learn effective policies for POMDP tasks more efficiently than previous approaches. This could have important applications in areas like robotics, game AI, and other domains where the agent must make decisions based on partial information about the environment.
Technical Explanation
The key contribution of this paper is the Recurrent Natural Policy Gradient (RNPG) algorithm, which is designed to solve Partially Observable Markov Decision Processes (POMDPs).
In a POMDP, the agent does not have full information about the current state of the environment. Instead, the agent receives only partial observations, which can make it challenging to choose the optimal action. RNPG addresses this challenge by combining the natural policy gradient algorithm with a recurrent neural network architecture.
The natural policy gradient is a technique that exploits the geometry of the policy space to compute more effective updates than standard policy gradient methods. This allows the agent to make updates that are more aligned with the direction that will improve the policy the most.
The recurrent neural network architecture is crucial because it enables the agent to maintain an internal memory or "hidden state" that can capture relevant information from past observations. This is important in POMDP tasks, where the current observation alone may not be sufficient to determine the best action.
The researchers evaluate RNPG on several POMDP benchmark tasks, including Partially Observable GridWorld, Partially Observable Maze, and Partially Observable Mountain Car. The results demonstrate that RNPG outperforms other state-of-the-art POMDP algorithms, highlighting the potential of this approach for learning effective policies in environments with partial observability.
Critical Analysis
The paper provides a thorough technical explanation of the RNPG algorithm and its performance on POMDP benchmarks. The researchers have done a commendable job of incorporating the natural policy gradient and recurrent neural network components to address the challenges of learning in partially observable environments.
One potential limitation of the research is the relatively narrow scope of the experiments, which focus on classic POMDP benchmark tasks. It would be valuable to see how RNPG performs on more complex, real-world POMDP problems, such as those encountered in robotics, game AI, or other practical applications.
Additionally, the paper does not provide a detailed analysis of the computational complexity or training time requirements of RNPG compared to other POMDP algorithms. This information could be helpful for researchers and practitioners in understanding the practical trade-offs and deployment considerations.
Overall, the RNPG algorithm represents a promising approach to solving POMDP tasks, and the paper provides a solid theoretical and empirical foundation for further research and development in this area.
Conclusion
This paper introduces the Recurrent Natural Policy Gradient (RNPG) algorithm, which combines the natural policy gradient and recurrent neural network architectures to effectively learn policies for Partially Observable Markov Decision Processes (POMDPs). The key innovation of RNPG is its ability to exploit the geometry of the policy space and maintain a memory of past observations, which can be crucial for making decisions in environments with partial observability.
The experimental results demonstrate that RNPG outperforms other state-of-the-art POMDP algorithms on several benchmark tasks, highlighting the potential of this approach for solving complex reinforcement learning problems with partial information. While the scope of the experiments is relatively narrow, the paper provides a solid foundation for further research and development in this area, with potential applications in robotics, game AI, and other domains where agents must make decisions based on incomplete information about their environment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Recurrent Natural Policy Gradient for POMDPs
Semih Cayci, Atilla Eryilmaz
In this paper, we study a natural policy gradient method based on recurrent neural networks (RNNs) for partially-observable Markov decision processes, whereby RNNs are used for policy parameterization and policy evaluation to address curse of dimensionality in non-Markovian reinforcement learning. We present finite-time and finite-width analyses for both the critic (recurrent temporal difference learning), and correspondingly-operated recurrent natural policy gradient method in the near-initialization regime. Our analysis demonstrates the efficiency of RNNs for problems with short-term memory with explicit bounds on the required network widths and sample complexity, and points out the challenges in the case of long-term dependencies.
Read more5/29/2024
🔎
0
Matrix Low-Rank Approximation For Policy Gradient Methods
Sergio Rozada, Antonio G. Marques
Estimating a policy that maps states to actions is a central problem in reinforcement learning. Traditionally, policies are inferred from the so called value functions (VFs), but exact VF computation suffers from the curse of dimensionality. Policy gradient (PG) methods bypass this by learning directly a parametric stochastic policy. Typically, the parameters of the policy are estimated using neural networks (NNs) tuned via stochastic gradient descent. However, finding adequate NN architectures can be challenging, and convergence issues are common as well. In this paper, we put forth low-rank matrix-based models to estimate efficiently the parameters of PG algorithms. We collect the parameters of the stochastic policy into a matrix, and then, we leverage matrix-completion techniques to promote (enforce) low rank. We demonstrate via numerical studies how low-rank matrix-based policy models reduce the computational and sample complexities relative to NN models, while achieving a similar aggregated reward.
Read more5/29/2024
🌿
0
Federated Natural Policy Gradient and Actor Critic Methods for Multi-task Reinforcement Learning
Tong Yang, Shicong Cen, Yuting Wei, Yuxin Chen, Yuejie Chi
Federated reinforcement learning (RL) enables collaborative decision making of multiple distributed agents without sharing local data trajectories. In this work, we consider a multi-task setting, in which each agent has its own private reward function corresponding to different tasks, while sharing the same transition kernel of the environment. Focusing on infinite-horizon Markov decision processes, the goal is to learn a globally optimal policy that maximizes the sum of the discounted total rewards of all the agents in a decentralized manner, where each agent only communicates with its neighbors over some prescribed graph topology. We develop federated vanilla and entropy-regularized natural policy gradient (NPG) methods in the tabular setting under softmax parameterization, where gradient tracking is applied to estimate the global Q-function to mitigate the impact of imperfect information sharing. We establish non-asymptotic global convergence guarantees under exact policy evaluation, where the rates are nearly independent of the size of the state-action space and illuminate the impacts of network size and connectivity. To the best of our knowledge, this is the first time that near dimension-free global convergence is established for federated multi-task RL using policy optimization. We further go beyond the tabular setting by proposing a federated natural actor critic (NAC) method for multi-task RL with function approximation, and establish its finite-time sample complexity taking the errors of function approximation into account.
Read more8/19/2024

0
Recurrent neural networks: vanishing and exploding gradients are not the end of the story
Nicolas Zucchet, Antonio Orvieto
Recurrent neural networks (RNNs) notoriously struggle to learn long-term memories, primarily due to vanishing and exploding gradients. The recent success of state-space models (SSMs), a subclass of RNNs, to overcome such difficulties challenges our theoretical understanding. In this paper, we delve into the optimization challenges of RNNs and discover that, as the memory of a network increases, changes in its parameters result in increasingly large output variations, making gradient-based learning highly sensitive, even without exploding gradients. Our analysis further reveals the importance of the element-wise recurrence design pattern combined with careful parametrizations in mitigating this effect. This feature is present in SSMs, as well as in other architectures, such as LSTMs. Overall, our insights provide a new explanation for some of the difficulties in gradient-based learning of RNNs and why some architectures perform better than others.
Read more6/3/2024