Recursive Introspection: Teaching Language Model Agents How to Self-Improve

26

Sign in to get full access
Overview
- This paper explores teaching language model agents how to self-improve through a process called "recursive introspection."
- The key idea is to enable language models to learn how to monitor and improve their own capabilities over time.
- The research aims to address the challenge of developing AI systems that can continuously enhance their performance without human intervention.
Plain English Explanation
The paper discusses a technique called "recursive introspection" that could help language model agents learn to improve themselves over time. The core idea is to give these AI systems the ability to assess their own capabilities and then find ways to enhance their skills on their own, without needing constant human oversight and intervention.
This is important because as language models become more advanced, it will be crucial for them to be able to continuously adapt and get better at their tasks without relying entirely on their human developers. The researchers are exploring ways to equip these AI agents with the self-awareness and self-improvement capabilities they would need to become more autonomous and capable over time.
Technical Explanation
The paper proposes a framework for "recursive introspection" that would enable language model agents to monitor their own performance, identify areas for improvement, and then take steps to enhance their capabilities. This involves training the agents to not only complete their primary tasks, but also to reason about their own thought processes and learning behaviors.
The key technical components include:
- Architecture designs that allow the agents to observe and analyze their internal decision-making mechanisms
- Training procedures that incentivize the agents to identify their weaknesses and develop strategies for self-improvement
- Techniques for the agents to efficiently explore new ways of enhancing their skills through simulated "imagination searching"
Through extensive experiments, the researchers demonstrate that language models trained with this recursive introspection approach are able to significantly outperform standard language models on a variety of benchmarks over time, as they continually refine and expand their capabilities.
Critical Analysis
The paper provides a compelling vision for the future of autonomous, self-improving AI systems. However, the researchers acknowledge several caveats and limitations to their approach. For example, the self-improvement process may be computationally intensive and could potentially lead to unpredictable or undesirable behaviors if not properly constrained.
Additionally, the paper does not fully address the ethical implications of developing language models with strong self-awareness and self-modification capabilities. There are valid concerns about the risks of such systems, and the researchers could have offered a more thorough discussion of potential safeguards and governance frameworks.
Overall, the work represents an important step towards more advanced and adaptive AI, but further research is needed to ensure that these self-improving language models can be developed and deployed safely and responsibly.
Conclusion
This paper presents a novel approach for teaching language model agents how to engage in "recursive introspection" - the ability to monitor their own performance, identify areas for improvement, and then take steps to enhance their capabilities over time. By equipping AI systems with these self-awareness and self-improvement skills, the researchers aim to create more autonomous and adaptable language models that can continuously learn and refine their skills without relying on constant human intervention.
While the technical details and experimental results are promising, the work also raises important ethical considerations that will need to be carefully addressed as this line of research progresses. Ultimately, the ability to develop self-improving AI systems could have far-reaching implications for the future of artificial intelligence and its role in society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
26
Recursive Introspection: Teaching Language Model Agents How to Self-Improve
Yuxiao Qu, Tianjun Zhang, Naman Garg, Aviral Kumar
A central piece in enabling intelligent agentic behavior in foundation models is to make them capable of introspecting upon their behavior, reasoning, and correcting their mistakes as more computation or interaction is available. Even the strongest proprietary large language models (LLMs) do not quite exhibit the ability of continually improving their responses sequentially, even in scenarios where they are explicitly told that they are making a mistake. In this paper, we develop RISE: Recursive IntroSpEction, an approach for fine-tuning LLMs to introduce this capability, despite prior work hypothesizing that this capability may not be possible to attain. Our approach prescribes an iterative fine-tuning procedure, which attempts to teach the model how to alter its response after having executed previously unsuccessful attempts to solve a hard test-time problem, with optionally additional environment feedback. RISE poses fine-tuning for a single-turn prompt as solving a multi-turn Markov decision process (MDP), where the initial state is the prompt. Inspired by principles in online imitation learning and reinforcement learning, we propose strategies for multi-turn data collection and training so as to imbue an LLM with the capability to recursively detect and correct its previous mistakes in subsequent iterations. Our experiments show that RISE enables Llama2, Llama3, and Mistral models to improve themselves with more turns on math reasoning tasks, outperforming several single-turn strategies given an equal amount of inference-time computation. We also find that RISE scales well, often attaining larger benefits with more capable models. Our analysis shows that RISE makes meaningful improvements to responses to arrive at the correct solution for challenging prompts, without disrupting one-turn abilities as a result of expressing more complex distributions.
Read more7/29/2024
24
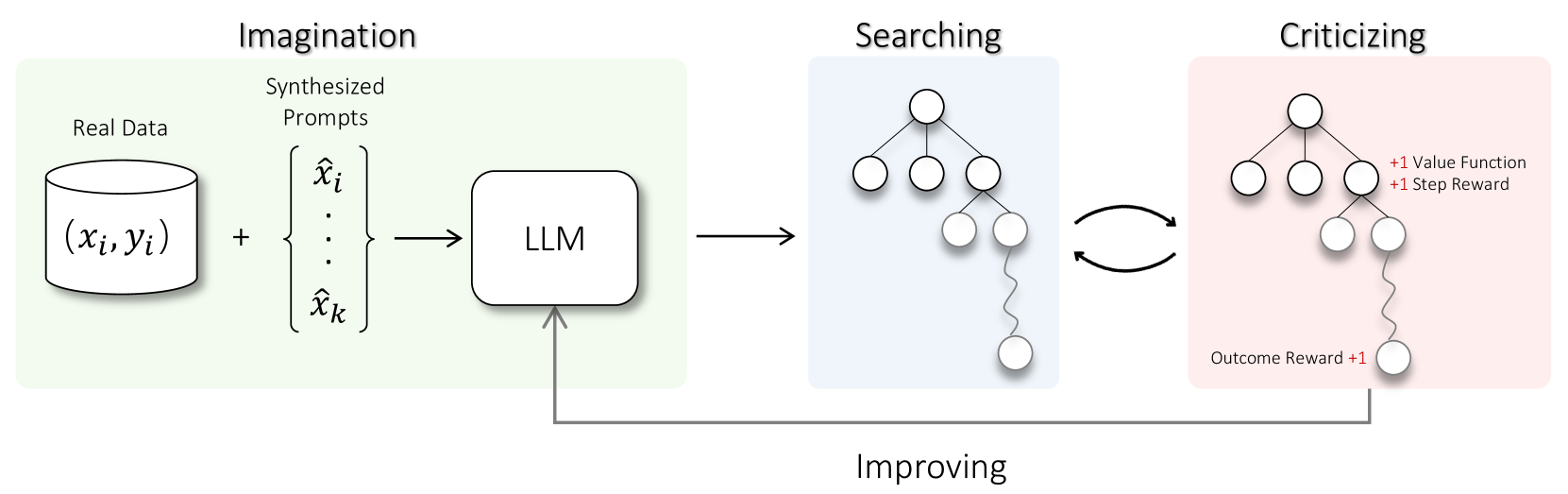
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, Dong Yu
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
Read more4/19/2024
💬
0
METAREFLECTION: Learning Instructions for Language Agents using Past Reflections
Priyanshu Gupta, Shashank Kirtania, Ananya Singha, Sumit Gulwani, Arjun Radhakrishna, Sherry Shi, Gustavo Soares
Despite the popularity of Large Language Models (LLMs), crafting specific prompts for LLMs to perform particular tasks remains challenging. Users often engage in multiple conversational turns with an LLM-based agent to accomplish their intended task. Recent studies have demonstrated that linguistic feedback, in the form of self-reflections generated by the model, can work as reinforcement during these conversations, thus enabling quicker convergence to the desired outcome. Motivated by these findings, we introduce METAREFLECTION, a novel technique that learns general prompt instructions for a specific domain from individual self-reflections gathered during a training phase. We evaluate our technique in two domains: Infrastructure as Code (IAC) vulnerability detection and question-answering (QA) using REACT and COT. Our results demonstrate a notable improvement, with METARELECTION outperforming GPT-4 by 16.82% (IAC), 31.33% (COT), and 15.42% (REACT), underscoring the potential of METAREFLECTION as a viable method for enhancing the efficiency of LLMs.
Read more5/24/2024

0
Self-evolving Agents with reflective and memory-augmented abilities
Xuechen Liang, Meiling Tao, Yinghui Xia, Tianyu Shi, Jun Wang, JingSong Yang
Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making. In this research, we propose a novel framework by integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents' capabilities in handling multi-tasking and long-span information.
Read more9/4/2024