Referring Expression Generation in Visually Grounded Dialogue with Discourse-aware Comprehension Guiding

0

Sign in to get full access
Overview
- Focuses on the challenge of generating referring expressions in visually-grounded dialogue
- Proposes a discourse-aware comprehension guiding approach to improve referring expression generation
- Evaluates the model on real-world datasets and demonstrates improved performance over baseline approaches
Plain English Explanation
The paper addresses the challenge of generating referring expressions in visually-grounded dialogues. In these dialogues, participants need to refer to specific objects or elements in an image in order to communicate effectively.
The key idea is to use discourse-aware comprehension guiding to improve the model's ability to generate appropriate referring expressions. This means that the model takes into account the broader context of the conversation, not just the current image, when deciding how to refer to an object.
For example, if the dialogue has already established that the participants are discussing a particular chair, the model can use a simpler referring expression like "the chair" rather than describing its full visual details. This makes the dialogue more natural and efficient.
The paper evaluates this approach on real-world datasets and shows that it outperforms baseline models that don't incorporate discourse-level understanding.
Technical Explanation
The paper proposes a novel discourse-aware comprehension guiding approach for generating referring expressions in visually-grounded dialogues.
The key components of the model are:
- Visual Encoder: Encodes the input image into a visual representation.
- Text Encoder: Encodes the dialogue history and the current query into a textual representation.
- Comprehension Guiding Module: Integrates the visual and textual representations to guide the generation of the referring expression, taking into account the broader discourse context.
- Referring Expression Generator: Generates the final referring expression based on the guided representations.
The authors evaluate their approach on two benchmark datasets for referring expression generation and visual grounding. They show that their discourse-aware model outperforms baseline models that do not explicitly consider the dialogue context.
Critical Analysis
The paper presents a well-designed approach to incorporate discourse-level understanding into the task of referring expression generation. The authors acknowledge some limitations, such as the need for further investigation of the model's interpretability and the potential impact of dialogue length on performance.
Additionally, while the proposed model demonstrates improved performance, there may be opportunities to further enhance its robustness and generalization to a wider range of dialogue scenarios and visual contexts. Exploring the use of more advanced language models or incorporating additional context could be fruitful directions for future research.
Conclusion
This paper presents a novel approach to referring expression generation in visually-grounded dialogues that leverages discourse-aware comprehension guiding. The demonstrated improvements over baseline models highlight the importance of considering the broader context of a conversation when generating referring expressions. This work contributes to the ongoing efforts to develop more natural and efficient dialogue systems, with potential applications in areas such as human-robot interaction and assistive technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Referring Expression Generation in Visually Grounded Dialogue with Discourse-aware Comprehension Guiding
Bram Willemsen, Gabriel Skantze
We propose an approach to referring expression generation (REG) in visually grounded dialogue that is meant to produce referring expressions (REs) that are both discriminative and discourse-appropriate. Our method constitutes a two-stage process. First, we model REG as a text- and image-conditioned next-token prediction task. REs are autoregressively generated based on their preceding linguistic context and a visual representation of the referent. Second, we propose the use of discourse-aware comprehension guiding as part of a generate-and-rerank strategy through which candidate REs generated with our REG model are reranked based on their discourse-dependent discriminatory power. Results from our human evaluation indicate that our proposed two-stage approach is effective in producing discriminative REs, with higher performance in terms of text-image retrieval accuracy for reranked REs compared to those generated using greedy decoding.
Read more9/10/2024
0
Make Graph-based Referring Expression Comprehension Great Again through Expression-guided Dynamic Gating and Regression
Jingcheng Ke, Dele Wang, Jun-Cheng Chen, I-Hong Jhuo, Chia-Wen Lin, Yen-Yu Lin
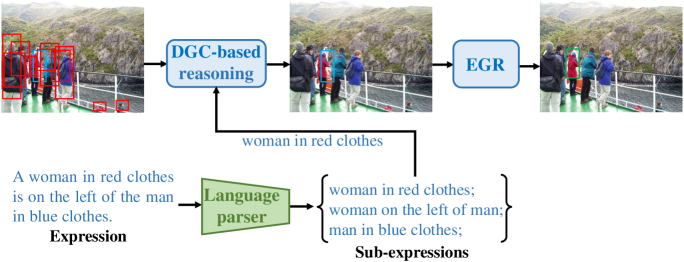
One common belief is that with complex models and pre-training on large-scale datasets, transformer-based methods for referring expression comprehension (REC) perform much better than existing graph-based methods. We observe that since most graph-based methods adopt an off-the-shelf detector to locate candidate objects (i.e., regions detected by the object detector), they face two challenges that result in subpar performance: (1) the presence of significant noise caused by numerous irrelevant objects during reasoning, and (2) inaccurate localization outcomes attributed to the provided detector. To address these issues, we introduce a plug-and-adapt module guided by sub-expressions, called dynamic gate constraint (DGC), which can adaptively disable irrelevant proposals and their connections in graphs during reasoning. We further introduce an expression-guided regression strategy (EGR) to refine location prediction. Extensive experimental results on the RefCOCO, RefCOCO+, RefCOCOg, Flickr30K, RefClef, and Ref-reasoning datasets demonstrate the effectiveness of the DGC module and the EGR strategy in consistently boosting the performances of various graph-based REC methods. Without any pretaining, the proposed graph-based method achieves better performance than the state-of-the-art (SOTA) transformer-based methods.
Read more9/6/2024

0
Resilience through Scene Context in Visual Referring Expression Generation
Simeon Junker, Sina Zarrie{ss}
Scene context is well known to facilitate humans' perception of visible objects. In this paper, we investigate the role of context in Referring Expression Generation (REG) for objects in images, where existing research has often focused on distractor contexts that exert pressure on the generator. We take a new perspective on scene context in REG and hypothesize that contextual information can be conceived of as a resource that makes REG models more resilient and facilitates the generation of object descriptions, and object types in particular. We train and test Transformer-based REG models with target representations that have been artificially obscured with noise to varying degrees. We evaluate how properties of the models' visual context affect their processing and performance. Our results show that even simple scene contexts make models surprisingly resilient to perturbations, to the extent that they can identify referent types even when visual information about the target is completely missing.
Read more8/26/2024

0
Learning Visual Grounding from Generative Vision and Language Model
Shijie Wang, Dahun Kim, Ali Taalimi, Chen Sun, Weicheng Kuo
Visual grounding tasks aim to localize image regions based on natural language references. In this work, we explore whether generative VLMs predominantly trained on image-text data could be leveraged to scale up the text annotation of visual grounding data. We find that grounding knowledge already exists in generative VLM and can be elicited by proper prompting. We thus prompt a VLM to generate object-level descriptions by feeding it object regions from existing object detection datasets. We further propose attribute modeling to explicitly capture the important object attributes, and spatial relation modeling to capture inter-object relationship, both of which are common linguistic pattern in referring expression. Our constructed dataset (500K images, 1M objects, 16M referring expressions) is one of the largest grounding datasets to date, and the first grounding dataset with purely model-generated queries and human-annotated objects. To verify the quality of this data, we conduct zero-shot transfer experiments to the popular RefCOCO benchmarks for both referring expression comprehension (REC) and segmentation (RES) tasks. On both tasks, our model significantly outperform the state-of-the-art approaches without using human annotated visual grounding data. Our results demonstrate the promise of generative VLM to scale up visual grounding in the real world. Code and models will be released.
Read more7/23/2024