Make Graph-based Referring Expression Comprehension Great Again through Expression-guided Dynamic Gating and Regression

0
Sign in to get full access
Overview
- This paper introduces a novel approach to improve graph-based referring expression comprehension (REC) tasks.
- The proposed method combines Transformer-based methods and graph-based methods through dynamic gate constraint and expression-guided regression.
- The key innovations include a dynamic gating mechanism that adaptively integrates Transformer and graph features, and an expression-guided regression loss that helps the model better ground referring expressions in the visual scene.
Plain English Explanation
In visual tasks like image captioning or visual question answering, referring expression comprehension (REC) is an important sub-task. REC involves identifying the object in an image that a given text description (the "referring expression") is referring to.
Past approaches to REC have used either Transformer-based methods or graph-based methods. Transformer-based methods excel at modeling language, while graph-based methods are better at capturing the relationships between objects in the visual scene.
This paper proposes a new method that combines the strengths of both approaches. It uses a dynamic gating mechanism to adaptively integrate the Transformer and graph features, allowing the model to draw on the most relevant information for each referring expression.
Additionally, the model is trained using an expression-guided regression loss, which helps it better ground the referring expression in the visual scene. This ensures the model doesn't just match the language, but truly understands how the referring expression relates to the objects in the image.
Technical Explanation
The proposed model consists of two main components: a Transformer-based language encoder and a graph-based visual encoder. The language encoder takes the referring expression as input and produces a language representation. The visual encoder constructs a graph representation of the image, where nodes correspond to objects and edges capture the relationships between them.
A key innovation is the dynamic gating mechanism, which adaptively combines the language and visual representations. This allows the model to focus on the most relevant information for each referring expression, rather than using a fixed fusion strategy.
The model is trained using two losses: a standard object classification loss, and the expression-guided regression loss. The regression loss encourages the model to not only predict the correct object, but to do so in a way that aligns with the semantics of the referring expression.
Experiments on benchmark REC datasets show that the proposed method outperforms previous Transformer-based and graph-based approaches, demonstrating the benefits of the dynamic gating and expression-guided regression components.
Critical Analysis
The paper presents a well-designed and effective approach to improving graph-based REC. The dynamic gating mechanism and expression-guided regression loss are compelling innovations that address important limitations in prior work.
One potential concern is the computational overhead of the graph-based visual encoder, which could limit the scalability of the model. The authors do not provide detailed performance metrics or analysis of the model's inference time.
Additionally, the paper does not explore the model's ability to generalize to unseen or complex referring expressions. The experiments focus on standard benchmark datasets, but real-world REC tasks may involve more diverse and challenging language that the model would need to handle.
Further research could investigate ways to balance the Transformer and graph components to achieve a more efficient and robust REC system. Exploring transfer learning or few-shot learning approaches could also help the model better adapt to new domains and expressions.
Conclusion
This paper presents a novel approach to graph-based referring expression comprehension that combines the strengths of Transformer-based and graph-based methods. The dynamic gating mechanism and expression-guided regression loss help the model better integrate language and visual information, leading to state-of-the-art performance on benchmark datasets.
While there are some potential scalability and generalization concerns, the paper demonstrates the value of hybridizing different modeling techniques to tackle complex visual-linguistic tasks. The innovations introduced here could inspire further research into building more advanced and versatile REC systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Make Graph-based Referring Expression Comprehension Great Again through Expression-guided Dynamic Gating and Regression
Jingcheng Ke, Dele Wang, Jun-Cheng Chen, I-Hong Jhuo, Chia-Wen Lin, Yen-Yu Lin
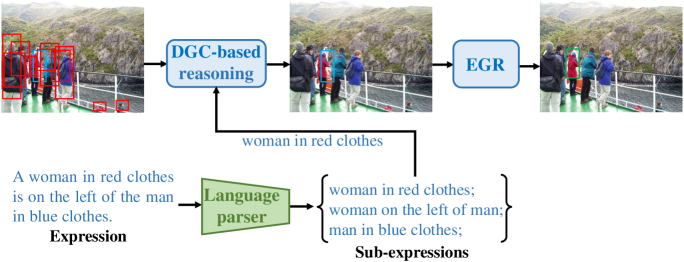
One common belief is that with complex models and pre-training on large-scale datasets, transformer-based methods for referring expression comprehension (REC) perform much better than existing graph-based methods. We observe that since most graph-based methods adopt an off-the-shelf detector to locate candidate objects (i.e., regions detected by the object detector), they face two challenges that result in subpar performance: (1) the presence of significant noise caused by numerous irrelevant objects during reasoning, and (2) inaccurate localization outcomes attributed to the provided detector. To address these issues, we introduce a plug-and-adapt module guided by sub-expressions, called dynamic gate constraint (DGC), which can adaptively disable irrelevant proposals and their connections in graphs during reasoning. We further introduce an expression-guided regression strategy (EGR) to refine location prediction. Extensive experimental results on the RefCOCO, RefCOCO+, RefCOCOg, Flickr30K, RefClef, and Ref-reasoning datasets demonstrate the effectiveness of the DGC module and the EGR strategy in consistently boosting the performances of various graph-based REC methods. Without any pretaining, the proposed graph-based method achieves better performance than the state-of-the-art (SOTA) transformer-based methods.
Read more9/6/2024

0
Referring Expression Generation in Visually Grounded Dialogue with Discourse-aware Comprehension Guiding
Bram Willemsen, Gabriel Skantze
We propose an approach to referring expression generation (REG) in visually grounded dialogue that is meant to produce referring expressions (REs) that are both discriminative and discourse-appropriate. Our method constitutes a two-stage process. First, we model REG as a text- and image-conditioned next-token prediction task. REs are autoregressively generated based on their preceding linguistic context and a visual representation of the referent. Second, we propose the use of discourse-aware comprehension guiding as part of a generate-and-rerank strategy through which candidate REs generated with our REG model are reranked based on their discourse-dependent discriminatory power. Results from our human evaluation indicate that our proposed two-stage approach is effective in producing discriminative REs, with higher performance in terms of text-image retrieval accuracy for reranked REs compared to those generated using greedy decoding.
Read more9/10/2024

0
Revisiting Referring Expression Comprehension Evaluation in the Era of Large Multimodal Models
Jierun Chen, Fangyun Wei, Jinjing Zhao, Sizhe Song, Bohuai Wu, Zhuoxuan Peng, S. -H. Gary Chan, Hongyang Zhang
Referring expression comprehension (REC) involves localizing a target instance based on a textual description. Recent advancements in REC have been driven by large multimodal models (LMMs) like CogVLM, which achieved 92.44% accuracy on RefCOCO. However, this study questions whether existing benchmarks such as RefCOCO, RefCOCO+, and RefCOCOg, capture LMMs' comprehensive capabilities. We begin with a manual examination of these benchmarks, revealing high labeling error rates: 14% in RefCOCO, 24% in RefCOCO+, and 5% in RefCOCOg, which undermines the authenticity of evaluations. We address this by excluding problematic instances and reevaluating several LMMs capable of handling the REC task, showing significant accuracy improvements, thus highlighting the impact of benchmark noise. In response, we introduce Ref-L4, a comprehensive REC benchmark, specifically designed to evaluate modern REC models. Ref-L4 is distinguished by four key features: 1) a substantial sample size with 45,341 annotations; 2) a diverse range of object categories with 365 distinct types and varying instance scales from 30 to 3,767; 3) lengthy referring expressions averaging 24.2 words; and 4) an extensive vocabulary comprising 22,813 unique words. We evaluate a total of 24 large models on Ref-L4 and provide valuable insights. The cleaned versions of RefCOCO, RefCOCO+, and RefCOCOg, as well as our Ref-L4 benchmark and evaluation code, are available at https://github.com/JierunChen/Ref-L4.
Read more6/26/2024

0
Bring Adaptive Binding Prototypes to Generalized Referring Expression Segmentation
Weize Li, Zhicheng Zhao, Haochen Bai, Fei Su
Referring Expression Segmentation (RES) has attracted rising attention, aiming to identify and segment objects based on natural language expressions. While substantial progress has been made in RES, the emergence of Generalized Referring Expression Segmentation (GRES) introduces new challenges by allowing expressions to describe multiple objects or lack specific object references. Existing RES methods, usually rely on sophisticated encoder-decoder and feature fusion modules, and are difficult to generate class prototypes that match each instance individually when confronted with the complex referent and binary labels of GRES. In this paper, reevaluating the differences between RES and GRES, we propose a novel Model with Adaptive Binding Prototypes (MABP) that adaptively binds queries to object features in the corresponding region. It enables different query vectors to match instances of different categories or different parts of the same instance, significantly expanding the decoder's flexibility, dispersing global pressure across all queries, and easing the demands on the encoder. Experimental results demonstrate that MABP significantly outperforms state-of-the-art methods in all three splits on gRefCOCO dataset. Meanwhile, MABP also surpasses state-of-the-art methods on RefCOCO+ and G-Ref datasets, and achieves very competitive results on RefCOCO. Code is available at https://github.com/buptLwz/MABP
Read more5/27/2024