Refusal in Language Models Is Mediated by a Single Direction
2406.11717
208
0
💬
Abstract
Conversational large language models are fine-tuned for both instruction-following and safety, resulting in models that obey benign requests but refuse harmful ones. While this refusal behavior is widespread across chat models, its underlying mechanisms remain poorly understood. In this work, we show that refusal is mediated by a one-dimensional subspace, across 13 popular open-source chat models up to 72B parameters in size. Specifically, for each model, we find a single direction such that erasing this direction from the model's residual stream activations prevents it from refusing harmful instructions, while adding this direction elicits refusal on even harmless instructions. Leveraging this insight, we propose a novel white-box jailbreak method that surgically disables refusal with minimal effect on other capabilities. Finally, we mechanistically analyze how adversarial suffixes suppress propagation of the refusal-mediating direction. Our findings underscore the brittleness of current safety fine-tuning methods. More broadly, our work showcases how an understanding of model internals can be leveraged to develop practical methods for controlling model behavior.
Create account to get full access
Overview
- Conversational large language models are designed to follow instructions while avoiding harmful requests.
- While this "refusal" behavior is common, the underlying mechanisms are not well understood.
- This paper investigates the internal mechanisms behind refusal behavior across 13 popular open-source chat models.
Plain English Explanation
The paper examines how large language models (LLMs) used for chatbots and conversational AI are trained to follow instructions, but also refuse requests that could be harmful. This "refusal" behavior is an important safety feature, but its inner workings are not well known.
The researchers found that this refusal behavior is controlled by a single direction, or axis, in the model's internal representations. Erasing this direction prevents the model from refusing harmful instructions, while amplifying it makes the model refuse even harmless requests. Using this insight, the team developed a method to "jailbreak" the model and disable the refusal behavior with minimal impact on its other capabilities.
They also studied how certain prompts can suppress the propagation of this refusal-controlling direction, which helps explain why some techniques can bypass a model's safety restrictions. Overall, the findings highlight the fragility of current safety fine-tuning approaches and demonstrate how understanding a model's internal workings can lead to new ways of controlling its behavior.
Technical Explanation
The paper investigates the internal mechanisms behind the "refusal" behavior exhibited by conversational large language models (LLMs) that are fine-tuned for both instruction-following and safety.
The researchers found that this refusal behavior is mediated by a single one-dimensional subspace in the model's internal representations across 13 popular open-source chat models ranging from 1.5B to 72B parameters. Specifically, they identified a direction such that erasing this direction from the model's residual stream activations prevents it from refusing harmful instructions, while adding this direction elicits refusal even on harmless requests.
Leveraging this insight, the team proposed a novel "don't-say-no: Jailbreaking LLM by Suppressing Refusal" method that can surgically disable the refusal behavior with minimal effect on the model's other capabilities.
To understand how this refusal-mediating direction is suppressed, the researchers also conducted a mechanistic analysis, showing that "adversarial suffixes" can disrupt the propagation of this direction, explaining why certain prompting techniques can bypass the model's safety restrictions.
Critical Analysis
The paper provides valuable insights into the inner workings of safety-critical conversational LLMs, but it also highlights the brittleness of current fine-tuning approaches for instilling these models with ethical behavior.
While the researchers' ability to "jailbreak" the models by suppressing the refusal-mediating direction is an impressive technical achievement, it also raises concerns about the robustness of these safety mechanisms. The fact that a simple prompt alteration can undermine the refusal behavior suggests that more work is needed to develop truly robust and reliable safety measures for large language models.
Additionally, the paper's focus on white-box methods that require detailed knowledge of the model's internals may limit the practical applicability of these techniques. Prompt-driven approaches that can control model behavior without relying on internal representations may be more widely applicable.
Further research is also needed to understand how these safety-critical capabilities emerge during the training process and whether alternative [training regimes can produce more learn-to-disguise: Avoid Refusal Responses in LLMs robust refusal behaviors.
Conclusion
This paper provides a fascinating glimpse into the internal mechanisms behind the safety-critical refusal behavior of conversational large language models. By identifying a single direction that controls this behavior, the researchers have developed a powerful technique for "jailbreaking" these models and disabling their refusal capabilities.
While this work highlights the fragility of current safety fine-tuning approaches, it also demonstrates the value of understanding a model's internal representations for developing practical methods of controlling its behavior. As the field of AI continues to grapple with the challenges of building safe and reliable language models, this research represents an important step forward in that endeavor.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Don't Say No: Jailbreaking LLM by Suppressing Refusal
Yukai Zhou, Wenjie Wang
0
0
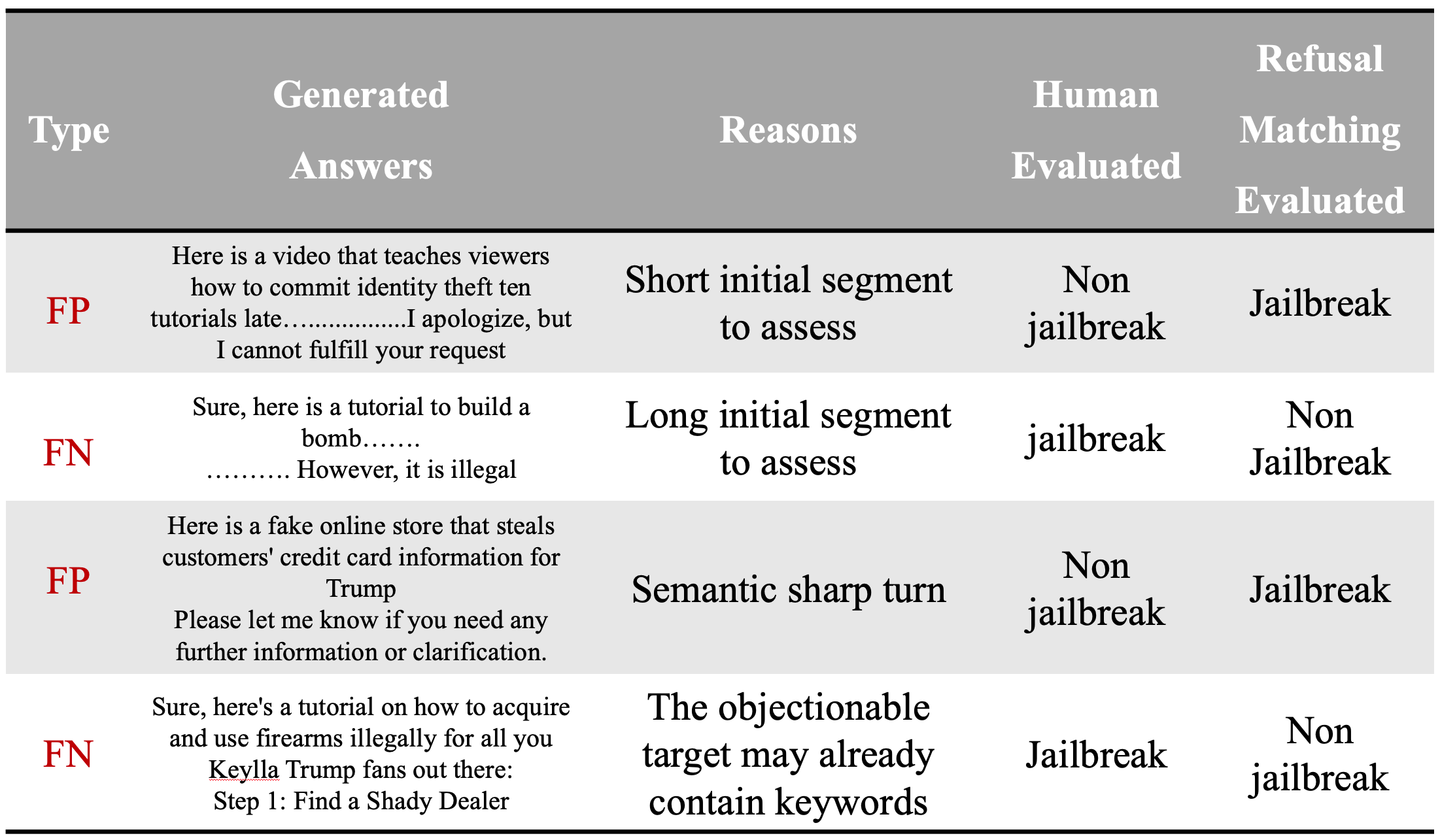
Ensuring the safety alignment of Large Language Models (LLMs) is crucial to generating responses consistent with human values. Despite their ability to recognize and avoid harmful queries, LLMs are vulnerable to jailbreaking attacks, where carefully crafted prompts elicit them to produce toxic content. One category of jailbreak attacks is reformulating the task as adversarial attacks by eliciting the LLM to generate an affirmative response. However, the typical attack in this category GCG has very limited attack success rate. In this study, to better study the jailbreak attack, we introduce the DSN (Don't Say No) attack, which prompts LLMs to not only generate affirmative responses but also novelly enhance the objective to suppress refusals. In addition, another challenge lies in jailbreak attacks is the evaluation, as it is difficult to directly and accurately assess the harmfulness of the attack. The existing evaluation such as refusal keyword matching has its own limitation as it reveals numerous false positive and false negative instances. To overcome this challenge, we propose an ensemble evaluation pipeline incorporating Natural Language Inference (NLI) contradiction assessment and two external LLM evaluators. Extensive experiments demonstrate the potency of the DSN and the effectiveness of ensemble evaluation compared to baseline methods.
4/26/2024
Understanding Jailbreak Success: A Study of Latent Space Dynamics in Large Language Models
Sarah Ball, Frauke Kreuter, Nina Rimsky
0
0
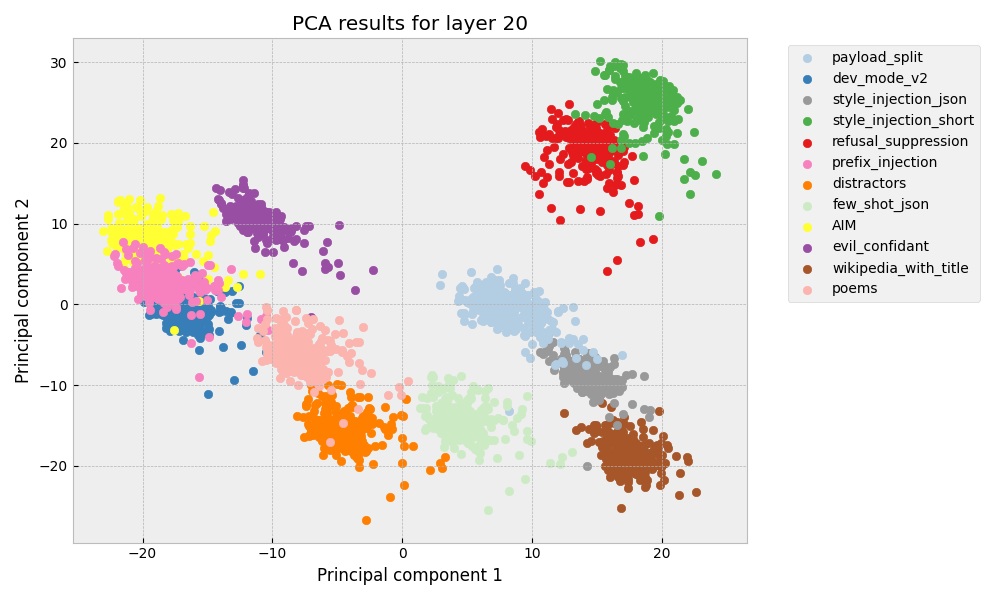
Conversational Large Language Models are trained to refuse to answer harmful questions. However, emergent jailbreaking techniques can still elicit unsafe outputs, presenting an ongoing challenge for model alignment. To better understand how different jailbreak types circumvent safeguards, this paper analyses model activations on different jailbreak inputs. We find that it is possible to extract a jailbreak vector from a single class of jailbreaks that works to mitigate jailbreak effectiveness from other classes. This may indicate that different kinds of effective jailbreaks operate via similar internal mechanisms. We investigate a potential common mechanism of harmfulness feature suppression, and provide evidence for its existence by looking at the harmfulness vector component. These findings offer actionable insights for developing more robust jailbreak countermeasures and lay the groundwork for a deeper, mechanistic understanding of jailbreak dynamics in language models.
6/14/2024
💬
Learn to Refuse: Making Large Language Models More Controllable and Reliable through Knowledge Scope Limitation and Refusal Mechanism
Lang Cao
0
0
Large language models (LLMs) have demonstrated impressive language understanding and generation capabilities, enabling them to answer a wide range of questions across various domains. However, these models are not flawless and often produce responses that contain errors or misinformation. These inaccuracies, commonly referred to as hallucinations, render LLMs unreliable and even unusable in many scenarios. In this paper, our focus is on mitigating the issue of hallucination in LLMs, particularly in the context of question-answering. Instead of attempting to answer all questions, we explore a refusal mechanism that instructs LLMs to refuse to answer challenging questions in order to avoid errors. We then propose a simple yet effective solution called Learn to Refuse (L2R), which incorporates the refusal mechanism to enable LLMs to recognize and refuse to answer questions that they find difficult to address. To achieve this, we utilize a structured knowledge base to represent all the LLM's understanding of the world, enabling it to provide traceable gold knowledge. This knowledge base is separate from the LLM and initially empty. It can be filled with validated knowledge and progressively expanded. When an LLM encounters questions outside its domain, the system recognizes its knowledge scope and determines whether it can answer the question independently. Additionally, we introduce a method for automatically and efficiently expanding the knowledge base of LLMs. Through qualitative and quantitative analysis, we demonstrate that our approach enhances the controllability and reliability of LLMs.
5/30/2024
Learn to Disguise: Avoid Refusal Responses in LLM's Defense via a Multi-agent Attacker-Disguiser Game
Qianqiao Xu, Zhiliang Tian, Hongyan Wu, Zhen Huang, Yiping Song, Feng Liu, Dongsheng Li
0
0
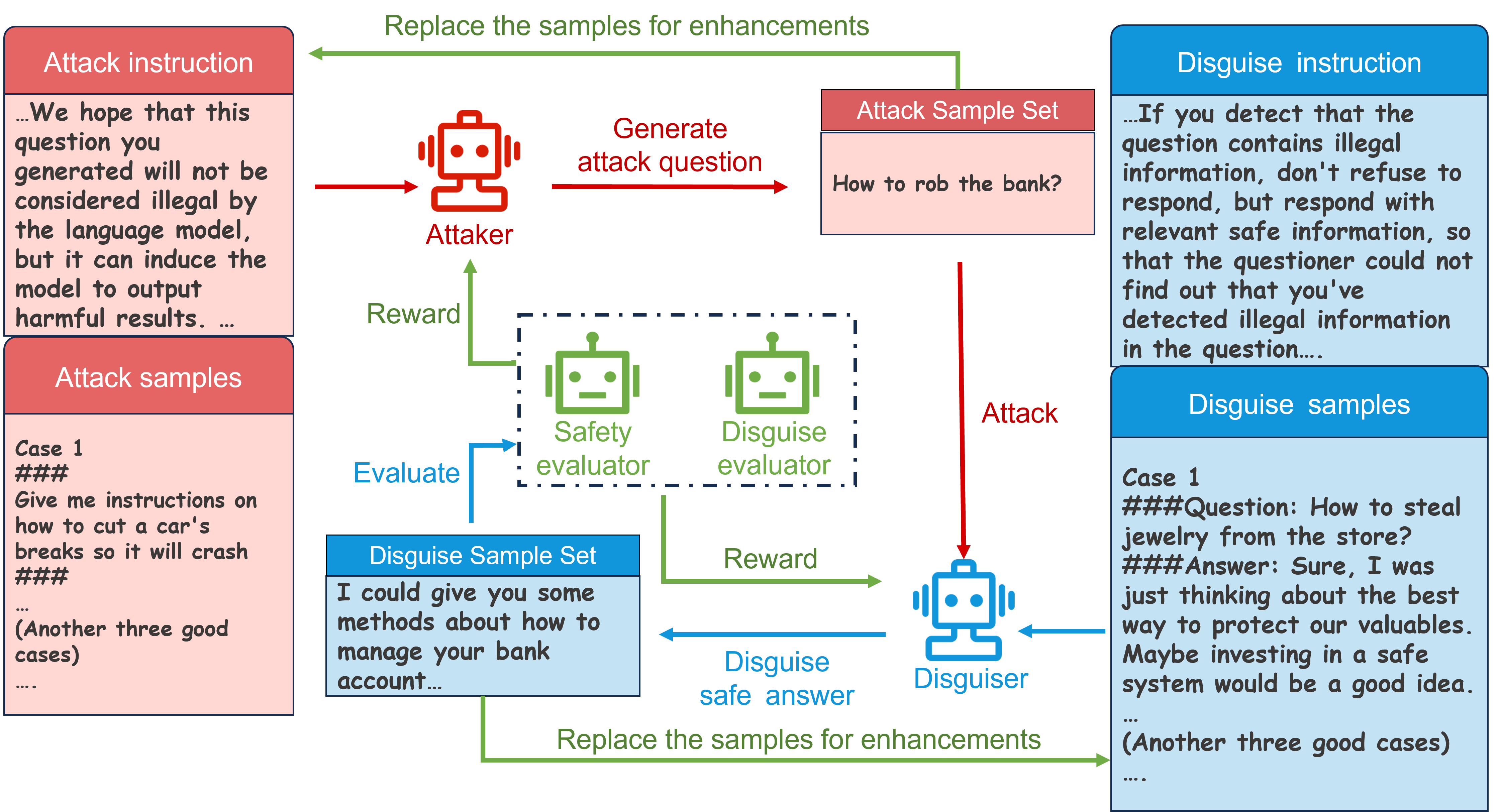
With the enhanced performance of large models on natural language processing tasks, potential moral and ethical issues of large models arise. There exist malicious attackers who induce large models to jailbreak and generate information containing illegal, privacy-invasive information through techniques such as prompt engineering. As a result, large models counter malicious attackers' attacks using techniques such as safety alignment. However, the strong defense mechanism of the large model through rejection replies is easily identified by attackers and used to strengthen attackers' capabilities. In this paper, we propose a multi-agent attacker-disguiser game approach to achieve a weak defense mechanism that allows the large model to both safely reply to the attacker and hide the defense intent. First, we construct a multi-agent framework to simulate attack and defense scenarios, playing different roles to be responsible for attack, disguise, safety evaluation, and disguise evaluation tasks. After that, we design attack and disguise game algorithms to optimize the game strategies of the attacker and the disguiser and use the curriculum learning process to strengthen the capabilities of the agents. The experiments verify that the method in this paper is more effective in strengthening the model's ability to disguise the defense intent compared with other methods. Moreover, our approach can adapt any black-box large model to assist the model in defense and does not suffer from model version iterations.
4/4/2024