ReGAL: Refactoring Programs to Discover Generalizable Abstractions

1

Sign in to get full access
Overview
• The paper presents a tool called ReGAL that aims to refactor existing programs to discover new, generalizable abstractions. • By analyzing the structure and patterns in code, ReGAL can automatically identify opportunities to extract reusable components, improving the modularity and maintainability of the codebase. • This approach can be particularly useful for large, complex programs where manual refactoring becomes challenging, as ReGAL can scale to handle real-world software systems.
Plain English Explanation
• ReGAL: Refactoring Programs to Discover Generalizable Abstractions is a tool that can automatically restructure computer programs to make them more modular and reusable. • Oftentimes, as software projects grow in size and complexity, the code can become difficult to maintain and understand. ReGAL aims to address this by analyzing the code and identifying common patterns or functionalities that could be extracted into separate, standalone components. • By refactoring the code in this way, ReGAL can help developers create more organized and flexible programs, where certain tasks or features can be easily reused across different parts of the application. This can save time and effort in the long run, as developers don't have to rewrite the same functionality from scratch. • The tool is designed to work on large, real-world software systems, where manual refactoring can be time-consuming and error-prone. ReGAL's automated approach can help streamline this process and improve the overall quality and maintainability of the codebase.
Technical Explanation
• The key idea behind ReGAL is to use a combination of program analysis techniques, such as abstract syntax tree (AST) manipulation and pattern matching, to identify opportunities for refactoring within existing code. • The tool first parses the input program into an AST, which represents the structure of the code in a hierarchical, tree-like format. ReGAL then applies a series of transformation rules to the AST, aiming to extract reusable components or "abstractions" that can be encapsulated and generalized. • These transformation rules are based on heuristics and domain-specific knowledge about common programming patterns and idioms. For example, ReGAL might recognize that certain code fragments are responsible for a specific task, such as input validation or data processing, and suggest extracting these into a separate, self-contained module. • Once the refactoring opportunities have been identified, ReGAL generates a modified version of the original program, where the new, generalized abstractions have been incorporated. This refactored code can then be evaluated and compared to the original to assess the improvements in modularity and code quality.
Critical Analysis
• While ReGAL demonstrates promising results in automatically refactoring programs to improve their structure and reusability, the paper acknowledges some limitations and areas for further research. • One potential concern is the reliance on heuristics and domain-specific rules, which may not generalize well to all types of programming languages and code structures. There could be value in exploring more data-driven or machine learning-based approaches to program refactoring, as seen in Learning to Reason via Program Generation & Emulation and Synthesizing Programmatic Reinforcement Learning Policies from Large Language Models. • Additionally, the paper does not address the potential impact of refactoring on the program's overall functionality and behavior. While the goal is to improve modularity and maintainability, it would be important to ensure that the refactored code still preserves the original program's semantics and correctness, as seen in RoboCoder: Robotic Learning from Basic Skills to Complex Behaviors. • Further research could explore ways to validate the correctness and safety of the refactored programs, perhaps by incorporating automated testing or formal verification techniques into the ReGAL framework.
Conclusion
• The ReGAL tool presented in this paper offers a promising approach to automatically refactoring existing programs to discover more generalized and reusable abstractions. • By analyzing the structure and patterns in code, ReGAL can identify opportunities to extract modular components, potentially improving the maintainability and flexibility of large, complex software systems. • While the tool shows promising results, there are still areas for further research, such as exploring more data-driven techniques and ensuring the refactored code preserves the original program's functionality and correctness. • Overall, the paper demonstrates the potential for automated program refactoring to enhance software engineering practices, and the continued need for advancements in this field to support the development of high-quality, scalable, and sustainable software.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
ReGAL: Refactoring Programs to Discover Generalizable Abstractions
Elias Stengel-Eskin, Archiki Prasad, Mohit Bansal
While large language models (LLMs) are increasingly being used for program synthesis, they lack the global view needed to develop useful abstractions; they generally predict programs one at a time, often repeating the same functionality. Generating redundant code from scratch is both inefficient and error-prone. To address this, we propose Refactoring for Generalizable Abstraction Learning (ReGAL), a gradient-free method for learning a library of reusable functions via code refactorization, i.e., restructuring code without changing its execution output. ReGAL learns from a small set of existing programs, iteratively verifying and refining its abstractions via execution. We find that the shared function libraries discovered by ReGAL make programs easier to predict across diverse domains. On five datasets -- LOGO graphics generation, Date reasoning, TextCraft (a Minecraft-based text-game) MATH, and TabMWP -- both open-source and proprietary LLMs improve in accuracy when predicting programs with ReGAL functions. For CodeLlama-13B, ReGAL results in absolute accuracy increases of 11.5% on LOGO, 26.1% on date understanding, and 8.1% on TextCraft, outperforming GPT-3.5 in two of three domains. Our analysis reveals ReGAL's abstractions encapsulate frequently-used subroutines as well as environment dynamics.
Read more6/7/2024

0
Towards Large Language Model Aided Program Refinement
Yufan Cai, Zhe Hou, Xiaokun Luan, David Miguel Sanan Baena, Yun Lin, Jun Sun, Jin Song Dong
Program refinement involves correctness-preserving transformations from formal high-level specification statements into executable programs. Traditional verification tool support for program refinement is highly interactive and lacks automation. On the other hand, the emergence of large language models (LLMs) enables automatic code generations from informal natural language specifications. However, code generated by LLMs is often unreliable. Moreover, the opaque procedure from specification to code provided by LLM is an uncontrolled black box. We propose LLM4PR, a tool that combines formal program refinement techniques with informal LLM-based methods to (1) transform the specification to preconditions and postconditions, (2) automatically build prompts based on refinement calculus, (3) interact with LLM to generate code, and finally, (4) verify that the generated code satisfies the conditions of refinement calculus, thus guaranteeing the correctness of the code. We have implemented our tool using GPT4, Coq, and Coqhammer, and evaluated it on the HumanEval and EvalPlus datasets.
Read more6/28/2024
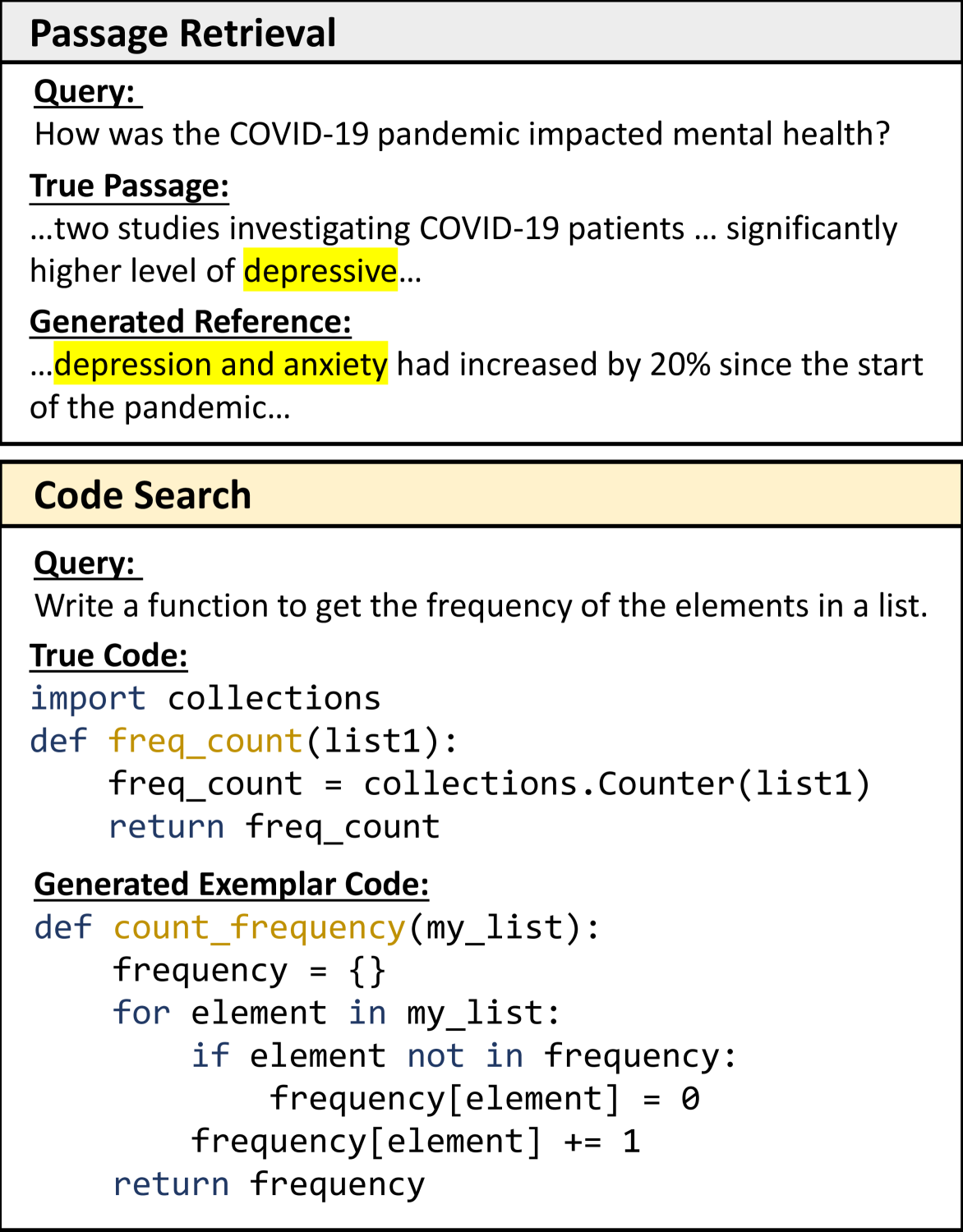
0
Rewriting the Code: A Simple Method for Large Language Model Augmented Code Search
Haochen Li, Xin Zhou, Zhiqi Shen
In code search, the Generation-Augmented Retrieval (GAR) framework, which generates exemplar code snippets to augment queries, has emerged as a promising strategy to address the principal challenge of modality misalignment between code snippets and natural language queries, particularly with the demonstrated code generation capabilities of Large Language Models (LLMs). Nevertheless, our preliminary investigations indicate that the improvements conferred by such an LLM-augmented framework are somewhat constrained. This limitation could potentially be ascribed to the fact that the generated codes, albeit functionally accurate, frequently display a pronounced stylistic deviation from the ground truth code in the codebase. In this paper, we extend the foundational GAR framework and propose a simple yet effective method that additionally Rewrites the Code (ReCo) within the codebase for style normalization. Experimental results demonstrate that ReCo significantly boosts retrieval accuracy across sparse (up to 35.7%), zero-shot dense (up to 27.6%), and fine-tuned dense (up to 23.6%) retrieval settings in diverse search scenarios. To further elucidate the advantages of ReCo and stimulate research in code style normalization, we introduce Code Style Similarity, the first metric tailored to quantify stylistic similarities in code. Notably, our empirical findings reveal the inadequacy of existing metrics in capturing stylistic nuances. The source code and data are available at url{https://github.com/Alex-HaochenLi/ReCo}.
Read more6/4/2024

0
Learning to Reason via Program Generation, Emulation, and Search
Nathaniel Weir, Muhammad Khalifa, Linlu Qiu, Orion Weller, Peter Clark
Program synthesis with language models (LMs) has unlocked a large set of reasoning abilities; code-tuned LMs have proven adept at generating programs that solve a wide variety of algorithmic symbolic manipulation tasks (e.g. word concatenation). However, not all reasoning tasks are easily expressible as code, e.g. tasks involving commonsense reasoning, moral decision-making, and sarcasm understanding. Our goal is to extend an LM's program synthesis skills to such tasks and evaluate the results via pseudo-programs, namely Python programs where some leaf function calls are left undefined. To that end, we propose, Code Generation and Emulated EXecution (CoGEX). CoGEX works by (1) training LMs to generate their own pseudo-programs, (2) teaching them to emulate their generated program's execution, including those leaf functions, allowing the LM's knowledge to fill in the execution gaps; and (3) using them to search over many programs to find an optimal one. To adapt the CoGEX model to a new task, we introduce a method for performing program search to find a single program whose pseudo-execution yields optimal performance when applied to all the instances of a given dataset. We show that our approach yields large improvements compared to standard in-context learning approaches on a battery of tasks, both algorithmic and soft reasoning. This result thus demonstrates that code synthesis can be applied to a much broader class of problems than previously considered. Our released dataset, fine-tuned models, and implementation can be found at url{https://github.com/nweir127/CoGEX}.
Read more5/30/2024