Rewriting the Code: A Simple Method for Large Language Model Augmented Code Search
2401.04514
0
0
Abstract
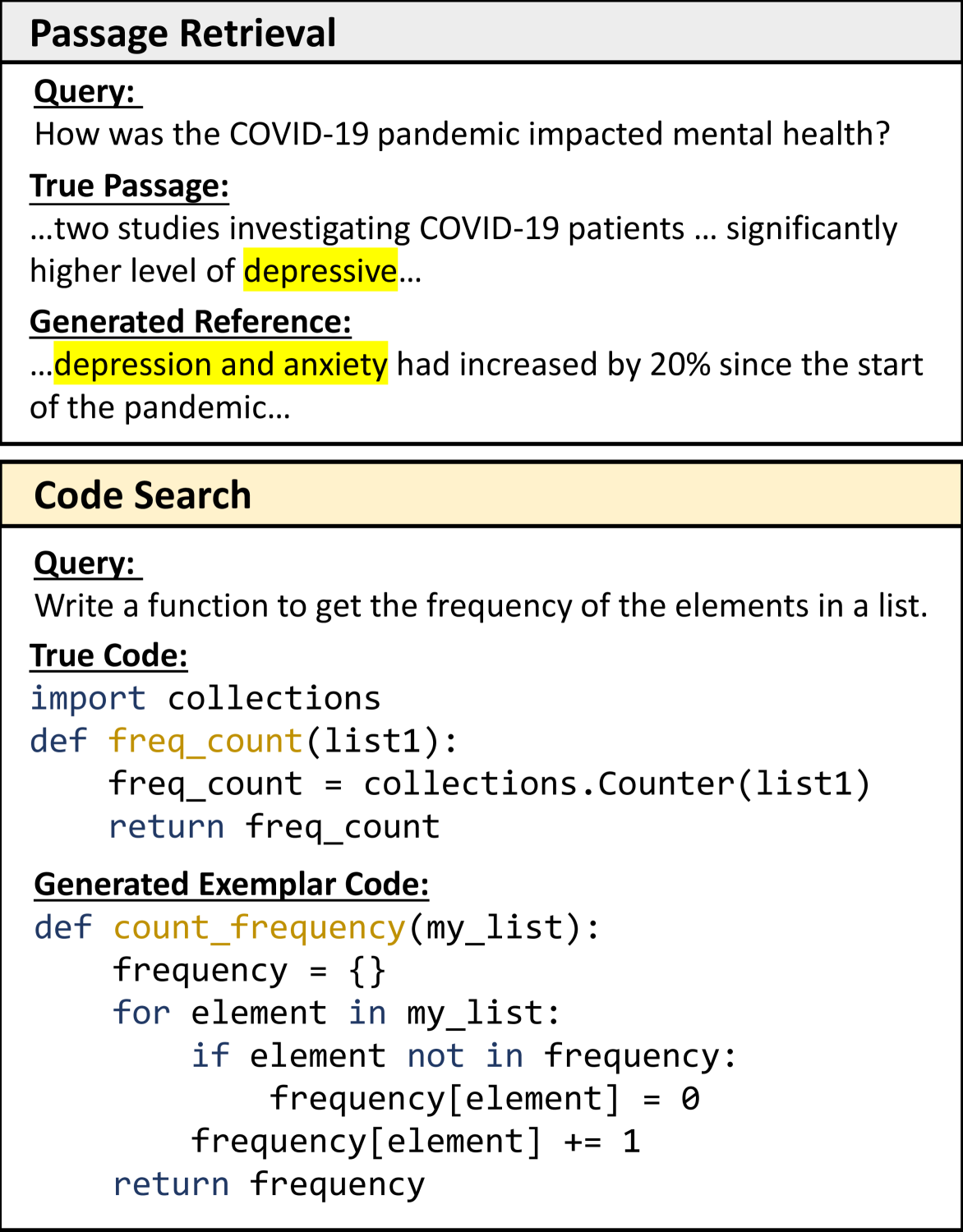
In code search, the Generation-Augmented Retrieval (GAR) framework, which generates exemplar code snippets to augment queries, has emerged as a promising strategy to address the principal challenge of modality misalignment between code snippets and natural language queries, particularly with the demonstrated code generation capabilities of Large Language Models (LLMs). Nevertheless, our preliminary investigations indicate that the improvements conferred by such an LLM-augmented framework are somewhat constrained. This limitation could potentially be ascribed to the fact that the generated codes, albeit functionally accurate, frequently display a pronounced stylistic deviation from the ground truth code in the codebase. In this paper, we extend the foundational GAR framework and propose a simple yet effective method that additionally Rewrites the Code (ReCo) within the codebase for style normalization. Experimental results demonstrate that ReCo significantly boosts retrieval accuracy across sparse (up to 35.7%), zero-shot dense (up to 27.6%), and fine-tuned dense (up to 23.6%) retrieval settings in diverse search scenarios. To further elucidate the advantages of ReCo and stimulate research in code style normalization, we introduce Code Style Similarity, the first metric tailored to quantify stylistic similarities in code. Notably, our empirical findings reveal the inadequacy of existing metrics in capturing stylistic nuances. The source code and data are available at url{https://github.com/Alex-HaochenLi/ReCo}.
Create account to get full access
Overview
- This paper presents a simple method for large language model (LLM) augmented code search, which aims to improve the accuracy and efficiency of code search tasks.
- The method involves rewriting the input query using an LLM to generate a more informative and relevant query, which is then used to search a code repository.
- The authors demonstrate the effectiveness of their approach through experiments on various code search datasets, showing improvements in search performance compared to traditional methods.
Plain English Explanation
The paper discusses a new way to make it easier to find code snippets that match what you're looking for. The key idea is to use a powerful language model, which is a type of AI that can understand and generate human-like text, to rewrite your original search query into a more informative and relevant version.
Imagine you're trying to find some code that solves a specific programming problem. You might start by searching for something like "how to sort a list in Python." But that query might be a bit vague, and the search results might not be very helpful.
Instead, the method proposed in this paper would take your original query and use a large language model to rephrase it into something more specific and useful, like "Python code to sort a list of integers in ascending order." This rewritten query is then used to search a database of code snippets, potentially leading to better and more relevant results.
The authors show that this approach can significantly improve the accuracy and efficiency of code search tasks, helping developers find the code they need more easily. By leveraging the power of large language models, this method can overcome some of the limitations of traditional keyword-based search and provide a more intelligent and effective way to navigate code repositories.
Technical Explanation
The paper introduces a simple method for [object Object] using a large language model (LLM) to [object Object] for code search tasks.
The key steps of the method are:
- Query Rewriting: The input query is passed through an LLM, which generates a rewritten version of the query that is more informative and relevant to the desired code search task.
- Code Search: The rewritten query is used to search a code repository, leveraging techniques like [object Object] and [object Object] to improve the search results.
The authors evaluate their method on several code search datasets and show that it outperforms traditional code search approaches, particularly in terms of [object Object] accuracy and efficiency.
Critical Analysis
The paper presents a relatively simple but effective approach to improving code search using LLMs. One potential limitation is that the quality of the rewritten query is heavily dependent on the capabilities of the LLM used, and the authors do not provide a thorough analysis of how different LLMs might affect the performance of their method.
Additionally, the paper does not address potential [object Object] of LLMs that could be introduced into the code search process, such as the tendency of LLMs to generate code that may not be robust or secure.
Further research could explore ways to mitigate these issues, such as by incorporating additional quality checks or by combining the LLM-based query rewriting with other techniques like [object Object].
Conclusion
This paper presents a simple yet effective method for improving code search by leveraging the power of large language models to rewrite the input query. The authors demonstrate the effectiveness of their approach through experiments on various code search datasets, showing significant improvements in search performance compared to traditional methods.
While the paper does not address all potential issues and limitations of LLM-based code search, it represents an important step forward in [object Object] for developers. As LLMs continue to advance, this type of query rewriting approach could become an increasingly valuable tool in the software development workflow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
REINFOREST: Reinforcing Semantic Code Similarity for Cross-Lingual Code Search Models
Anthony Saieva, Saikat Chakraborty, Gail Kaiser
0
0
This paper introduces a novel code-to-code search technique that enhances the performance of Large Language Models (LLMs) by including both static and dynamic features as well as utilizing both similar and dissimilar examples during training. We present the first-ever code search method that encodes dynamic runtime information during training without the need to execute either the corpus under search or the search query at inference time and the first code search technique that trains on both positive and negative reference samples. To validate the efficacy of our approach, we perform a set of studies demonstrating the capability of enhanced LLMs to perform cross-language code-to-code search. Our evaluation demonstrates that the effectiveness of our approach is consistent across various model architectures and programming languages. We outperform the state-of-the-art cross-language search tool by up to 44.7%. Moreover, our ablation studies reveal that even a single positive and negative reference sample in the training process results in substantial performance improvements demonstrating both similar and dissimilar references are important parts of code search. Importantly, we show that enhanced well-crafted, fine-tuned models consistently outperform enhanced larger modern LLMs without fine tuning, even when enhancing the largest available LLMs highlighting the importance for open-sourced models. To ensure the reproducibility and extensibility of our research, we present an open-sourced implementation of our tool and training procedures called REINFOREST.
4/17/2024
Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting
Tong Ye, Yangkai Du, Tengfei Ma, Lingfei Wu, Xuhong Zhang, Shouling Ji, Wenhai Wang
0
0
Large Language Models (LLMs) have exhibited remarkable proficiency in generating code. However, the misuse of LLM-generated (Synthetic) code has prompted concerns within both educational and industrial domains, highlighting the imperative need for the development of synthetic code detectors. Existing methods for detecting LLM-generated content are primarily tailored for general text and often struggle with code content due to the distinct grammatical structure of programming languages and massive low-entropy tokens. Building upon this, our work proposes a novel zero-shot synthetic code detector based on the similarity between the code and its rewritten variants. Our method relies on the intuition that the differences between the LLM-rewritten and original codes tend to be smaller when the original code is synthetic. We utilize self-supervised contrastive learning to train a code similarity model and assess our approach on two synthetic code detection benchmarks. Our results demonstrate a notable enhancement over existing synthetic content detectors designed for general texts, with an improvement of 20.5% in the APPS benchmark and 29.1% in the MBPP benchmark.
5/31/2024
CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation
Kounianhua Du, Renting Rui, Huacan Chai, Lingyue Fu, Wei Xia, Yasheng Wang, Ruiming Tang, Yong Yu, Weinan Zhang
0
0
Utilizing large language models to generate codes has shown promising meaning in software development revolution. Despite the intelligence shown by the general large language models, their specificity in code generation can still be improved due to the syntactic gap and mismatched vocabulary existing among natural language and different programming languages. In addition, programming languages are inherently logical and complex, making them hard to be correctly generated. Existing methods rely on multiple prompts to the large language model to explore better solutions, which is expensive. In this paper, we propose Syntax Graph Retrieval Augmented Code Generation (CodeGRAG) to enhance the performance of LLMs in single-round code generation tasks. CodeGRAG extracts and summarizes the control flow and data flow of code blocks to fill the gap between programming languages and natural language. The extracted external structural knowledge models the inherent flows of code blocks, which can facilitate LLMs for better understanding of code syntax and serve as a bridge among different programming languages. CodeGRAG significantly improves the code generation ability of LLMs and can even offer performance gain for cross-lingual code generation, e.g., C++ for Python.
5/7/2024

CodeRAG-Bench: Can Retrieval Augment Code Generation?
Zora Zhiruo Wang, Akari Asai, Xinyan Velocity Yu, Frank F. Xu, Yiqing Xie, Graham Neubig, Daniel Fried
0
0
While language models (LMs) have proven remarkably adept at generating code, many programs are challenging for LMs to generate using their parametric knowledge alone. Providing external contexts such as library documentation can facilitate generating accurate and functional code. Despite the success of retrieval-augmented generation (RAG) in various text-oriented tasks, its potential for improving code generation remains under-explored. In this work, we conduct a systematic, large-scale analysis by asking: in what scenarios can retrieval benefit code generation models? and what challenges remain? We first curate a comprehensive evaluation benchmark, CodeRAG-Bench, encompassing three categories of code generation tasks, including basic programming, open-domain, and repository-level problems. We aggregate documents from five sources for models to retrieve contexts: competition solutions, online tutorials, library documentation, StackOverflow posts, and GitHub repositories. We examine top-performing models on CodeRAG-Bench by providing contexts retrieved from one or multiple sources. While notable gains are made in final code generation by retrieving high-quality contexts across various settings, our analysis reveals room for improvement -- current retrievers still struggle to fetch useful contexts especially with limited lexical overlap, and generators fail to improve with limited context lengths or abilities to integrate additional contexts. We hope CodeRAG-Bench serves as an effective testbed to encourage further development of advanced code-oriented RAG methods.
6/21/2024