Region Attention Transformer for Medical Image Restoration

0

Sign in to get full access
Overview
- The paper presents a Region Attention Transformer (RAT) model for medical image restoration, which aims to improve the quality of degraded or incomplete medical images.
- The key ideas include a Segment Anything Model (SAM) to identify focal regions in the image, a Region Attention Transformer to capture long-range dependencies, and a Focal Region Loss to focus the model on important areas.
- The proposed approach is evaluated on several medical image restoration tasks, demonstrating improved performance compared to previous methods.
Plain English Explanation
Medical imaging technologies like MRI and CT scans are crucial for disease diagnosis and treatment. However, these images can sometimes be degraded or incomplete due to various factors, making them harder for doctors to interpret. The Region Attention Transformer for Medical Image Restoration paper tackles this problem by developing a deep learning model to restore and enhance low-quality medical images.
At the heart of the model is the idea of "focal regions" - the most important parts of the image that doctors need to focus on, like tumors or organ structures. The researchers use a Segment Anything Model (SAM) to automatically identify these focal regions in the image. Then, a Region Attention Transformer is used to capture the long-range relationships between different parts of the image, which is important for accurately restoring the image. Finally, the model is trained using a Focal Region Loss that emphasizes the restoration of the most important regions.
By focusing on the key areas of the image and using advanced deep learning techniques, the Region Attention Transformer model is able to produce higher-quality, more informative medical images that can aid doctors in making accurate diagnoses and treatment plans.
Technical Explanation
The Region Attention Transformer for Medical Image Restoration paper proposes a deep learning model that leverages several key components to improve the restoration of degraded or incomplete medical images.
-
Segment Anything Model (SAM): The researchers use a pre-trained SAM to automatically identify the "focal regions" - the most important areas of the medical image that doctors need to focus on, such as tumors or organ structures. This allows the model to prioritize the restoration of these critical regions.
-
Region Attention Transformer: The core of the restoration model is a Region Attention Transformer, which uses a transformer-based architecture to capture long-range dependencies between different parts of the image. This is crucial for accurately restoring the image, as the degradation or missing information in one area can impact other regions.
-
Focal Region Loss: The model is trained using a Focal Region Loss function that emphasizes the importance of accurately restoring the focal regions identified by the SAM. This ensures that the model prioritizes the most critical areas of the image during training and optimization.
The researchers evaluate the Region Attention Transformer model on several medical image restoration tasks, including CT image denoising, MRI image super-resolution, and medical image inpainting. The results demonstrate that the proposed approach outperforms previous state-of-the-art methods, highlighting the benefits of the Segment Anything Model, Region Attention Transformer, and Focal Region Loss components.
Critical Analysis
The Region Attention Transformer for Medical Image Restoration paper presents a compelling approach to improving the quality of degraded or incomplete medical images. The use of the Segment Anything Model to identify focal regions and the Region Attention Transformer to capture long-range dependencies are well-motivated and seem to contribute to the model's strong performance.
However, the paper does not discuss the potential limitations or drawbacks of the proposed approach. For example, the reliance on the pre-trained SAM model may limit the model's applicability to domains or tasks where such a model is not available. Additionally, the computational complexity of the Region Attention Transformer could be a concern, especially for real-time or resource-constrained medical imaging applications.
Furthermore, the paper does not address the potential ethical implications of using AI-powered medical image restoration. While the technology can undoubtedly improve patient outcomes, there are concerns about the reliability, interpretability, and potential biases in AI-generated medical images that should be carefully considered.
Overall, the Region Attention Transformer for Medical Image Restoration paper presents an interesting and promising approach, but future research should delve deeper into the limitations, potential risks, and broader implications of this technology.
Conclusion
The Region Attention Transformer for Medical Image Restoration paper introduces a novel deep learning model that leverages the Segment Anything Model, Region Attention Transformer, and Focal Region Loss to improve the quality of degraded or incomplete medical images. By focusing on the most important regions of the image and using advanced deep learning techniques, the proposed approach demonstrates superior performance compared to previous methods.
This research has the potential to significantly impact the field of medical imaging, as high-quality images are crucial for accurate disease diagnosis and effective treatment planning. By enhancing the clarity and information content of medical images, the Region Attention Transformer model could lead to better-informed clinical decisions and improved patient outcomes.
However, the paper does not address the potential limitations and ethical considerations surrounding the use of AI-powered medical image restoration. Future work should explore these aspects to ensure the safe and responsible deployment of this technology in real-world healthcare settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Region Attention Transformer for Medical Image Restoration
Zhiwen Yang, Haowei Chen, Ziniu Qian, Yang Zhou, Hui Zhang, Dan Zhao, Bingzheng Wei, Yan Xu
Transformer-based methods have demonstrated impressive results in medical image restoration, attributed to the multi-head self-attention (MSA) mechanism in the spatial dimension. However, the majority of existing Transformers conduct attention within fixed and coarsely partitioned regions (text{e.g.} the entire image or fixed patches), resulting in interference from irrelevant regions and fragmentation of continuous image content. To overcome these challenges, we introduce a novel Region Attention Transformer (RAT) that utilizes a region-based multi-head self-attention mechanism (R-MSA). The R-MSA dynamically partitions the input image into non-overlapping semantic regions using the robust Segment Anything Model (SAM) and then performs self-attention within these regions. This region partitioning is more flexible and interpretable, ensuring that only pixels from similar semantic regions complement each other, thereby eliminating interference from irrelevant regions. Moreover, we introduce a focal region loss to guide our model to adaptively focus on recovering high-difficulty regions. Extensive experiments demonstrate the effectiveness of RAT in various medical image restoration tasks, including PET image synthesis, CT image denoising, and pathological image super-resolution. Code is available at href{https://github.com/Yaziwel/Region-Attention-Transformer-for-Medical-Image-Restoration.git}{https://github.com/RAT}.
Read more7/15/2024
🖼️
0
Multi-dimension Transformer with Attention-based Filtering for Medical Image Segmentation
Wentao Wang, Xi Xiao, Mingjie Liu, Qing Tian, Xuanyao Huang, Qizhen Lan, Swalpa Kumar Roy, Tianyang Wang
The accurate segmentation of medical images is crucial for diagnosing and treating diseases. Recent studies demonstrate that vision transformer-based methods have significantly improved performance in medical image segmentation, primarily due to their superior ability to establish global relationships among features and adaptability to various inputs. However, these methods struggle with the low signal-to-noise ratio inherent to medical images. Additionally, the effective utilization of channel and spatial information, which are essential for medical image segmentation, is limited by the representation capacity of self-attention. To address these challenges, we propose a multi-dimension transformer with attention-based filtering (MDT-AF), which redesigns the patch embedding and self-attention mechanism for medical image segmentation. MDT-AF incorporates an attention-based feature filtering mechanism into the patch embedding blocks and employs a coarse-to-fine process to mitigate the impact of low signal-to-noise ratio. To better capture complex structures in medical images, MDT-AF extends the self-attention mechanism to incorporate spatial and channel dimensions, enriching feature representation. Moreover, we introduce an interaction mechanism to improve the feature aggregation between spatial and channel dimensions. Experimental results on three public medical image segmentation benchmarks show that MDT-AF achieves state-of-the-art (SOTA) performance.
Read more5/22/2024
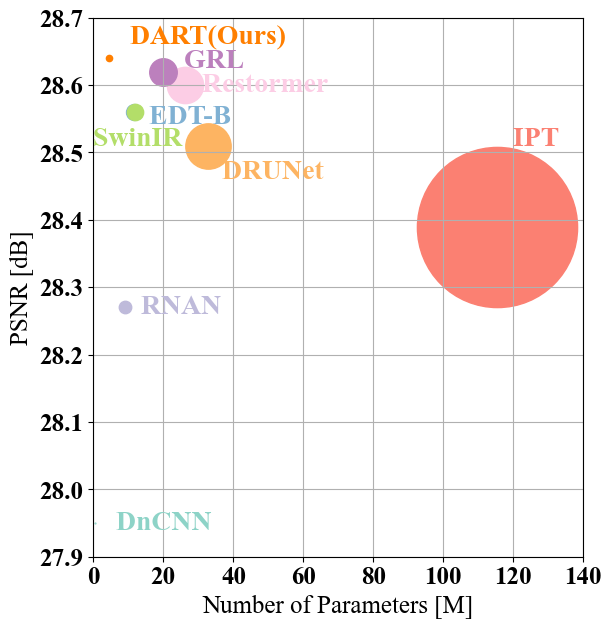
0
Empowering Image Recovery_ A Multi-Attention Approach
Juan Wen, Yawei Li, Chao Zhang, Weiyan Hou, Radu Timofte, Luc Van Gool
We propose Diverse Restormer (DART), a novel image restoration method that effectively integrates information from various sources (long sequences, local and global regions, feature dimensions, and positional dimensions) to address restoration challenges. While Transformer models have demonstrated excellent performance in image restoration due to their self-attention mechanism, they face limitations in complex scenarios. Leveraging recent advancements in Transformers and various attention mechanisms, our method utilizes customized attention mechanisms to enhance overall performance. DART, our novel network architecture, employs windowed attention to mimic the selective focusing mechanism of human eyes. By dynamically adjusting receptive fields, it optimally captures the fundamental features crucial for image resolution reconstruction. Efficiency and performance balance are achieved through the LongIR attention mechanism for long sequence image restoration. Integration of attention mechanisms across feature and positional dimensions further enhances the recovery of fine details. Evaluation across five restoration tasks consistently positions DART at the forefront. Upon acceptance, we commit to providing publicly accessible code and models to ensure reproducibility and facilitate further research.
Read more4/10/2024

0
SMAFormer: Synergistic Multi-Attention Transformer for Medical Image Segmentation
Fuchen Zheng, Xuhang Chen, Weihuang Liu, Haolun Li, Yingtie Lei, Jiahui He, Chi-Man Pun, Shounjun Zhou
In medical image segmentation, specialized computer vision techniques, notably transformers grounded in attention mechanisms and residual networks employing skip connections, have been instrumental in advancing performance. Nonetheless, previous models often falter when segmenting small, irregularly shaped tumors. To this end, we introduce SMAFormer, an efficient, Transformer-based architecture that fuses multiple attention mechanisms for enhanced segmentation of small tumors and organs. SMAFormer can capture both local and global features for medical image segmentation. The architecture comprises two pivotal components. First, a Synergistic Multi-Attention (SMA) Transformer block is proposed, which has the benefits of Pixel Attention, Channel Attention, and Spatial Attention for feature enrichment. Second, addressing the challenge of information loss incurred during attention mechanism transitions and feature fusion, we design a Feature Fusion Modulator. This module bolsters the integration between the channel and spatial attention by mitigating reshaping-induced information attrition. To evaluate our method, we conduct extensive experiments on various medical image segmentation tasks, including multi-organ, liver tumor, and bladder tumor segmentation, achieving state-of-the-art results. Code and models are available at: url{https://github.com/CXH-Research/SMAFormer}.
Read more9/17/2024