Regret Analysis for Randomized Gaussian Process Upper Confidence Bound

0

Sign in to get full access
Overview
- This paper analyzes the regret bounds for a randomized Gaussian process upper confidence bound (GP-UCB) algorithm used in Bayesian optimization.
- It provides theoretical guarantees on the cumulative regret of this algorithm under certain assumptions.
- The analysis builds upon previous work on GP-UCB and introduces a new randomization technique to improve the regret bounds.
Plain English Explanation
Bayesian optimization is a popular technique for efficiently optimizing expensive black-box functions, such as the performance of a machine learning model on a dataset. The Gaussian process upper confidence bound (GP-UCB) algorithm is a common approach used in Bayesian optimization.
In this paper, the researchers analyze the regret, or the difference between the optimal function value and the values obtained by the algorithm, for a randomized version of GP-UCB. They show that by adding a small amount of randomness to the algorithm, they can obtain tighter regret bounds compared to the standard GP-UCB algorithm.
The key idea is to randomly perturb the acquisition function used by GP-UCB to select the next point to evaluate. This randomization helps the algorithm explore the search space more effectively, leading to better overall performance.
The paper provides theoretical guarantees on the cumulative regret of this randomized GP-UCB algorithm, demonstrating that it can outperform the original GP-UCB approach under certain assumptions about the underlying function being optimized.
Technical Explanation
The paper analyzes the regret bounds for a randomized version of the Gaussian process upper confidence bound (GP-UCB) algorithm, which is a popular approach for Bayesian optimization.
The standard GP-UCB algorithm selects the next point to evaluate by maximizing an acquisition function that balances exploration and exploitation. The randomized version introduced in this paper adds a small amount of noise to the acquisition function, which can lead to better exploration of the search space.
The key technical contributions of the paper are:
-
Regret Analysis: The authors provide theoretical guarantees on the cumulative regret of the randomized GP-UCB algorithm, showing that it can achieve tighter regret bounds compared to the original GP-UCB under certain assumptions.
-
Randomization Technique: The paper introduces a novel randomization technique that perturbs the acquisition function used by GP-UCB. This helps the algorithm explore the search space more effectively, leading to improved performance.
-
Assumptions and Limitations: The analysis relies on assumptions about the underlying function being optimized, such as having a bounded norm in the associated reproducing kernel Hilbert space. The paper also discusses potential limitations and areas for future research.
Critical Analysis
The paper provides a rigorous theoretical analysis of the regret bounds for the randomized GP-UCB algorithm, which is a valuable contribution to the literature on Bayesian optimization. The randomization technique introduced in the paper is an interesting approach to improving the exploration-exploitation trade-off in GP-UCB.
However, the analysis is dependent on several assumptions, such as the boundedness of the function norm in the associated RKHS. While these assumptions are common in the Bayesian optimization literature, they may not always hold in practice. It would be interesting to see further investigation of the algorithm's performance under more relaxed assumptions or in the presence of noise.
Additionally, the paper does not provide any empirical evaluation of the randomized GP-UCB algorithm. Experimental results comparing its performance to the standard GP-UCB and other Bayesian optimization methods would help validate the theoretical findings and provide a more comprehensive understanding of the algorithm's practical benefits.
Conclusion
This paper presents a regret analysis for a randomized version of the Gaussian process upper confidence bound (GP-UCB) algorithm used in Bayesian optimization. By introducing a small amount of randomness into the acquisition function, the authors show that the randomized GP-UCB can achieve tighter regret bounds compared to the original algorithm under certain assumptions.
The theoretical guarantees provided in this work contribute to our understanding of the trade-offs between exploration and exploitation in Bayesian optimization. The randomization technique could potentially be applied to other Bayesian optimization methods to improve their performance. However, further empirical evaluation and analysis under more relaxed assumptions would be valuable to assess the practical implications of this research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Regret Analysis for Randomized Gaussian Process Upper Confidence Bound
Shion Takeno, Yu Inatsu, Masayuki Karasuyama
Gaussian process upper confidence bound (GP-UCB) is a theoretically established algorithm for Bayesian optimization (BO), where we assume the objective function $f$ follows GP. One notable drawback of GP-UCB is that the theoretical confidence parameter $beta$ increased along with the iterations is too large. To alleviate this drawback, this paper analyzes the randomized variant of GP-UCB called improved randomized GP-UCB (IRGP-UCB), which uses the confidence parameter generated from the shifted exponential distribution. We analyze the expected regret and conditional expected regret, where the expectation and the probability are taken respectively with $f$ and noises and with the randomness of the BO algorithm. In both regret analyses, IRGP-UCB achieves a sub-linear regret upper bound without increasing the confidence parameter if the input domain is finite. Finally, we show numerical experiments using synthetic and benchmark functions and real-world emulators.
Read more9/17/2024
🛠️
0
Posterior Sampling-Based Bayesian Optimization with Tighter Bayesian Regret Bounds
Shion Takeno, Yu Inatsu, Masayuki Karasuyama, Ichiro Takeuchi
Among various acquisition functions (AFs) in Bayesian optimization (BO), Gaussian process upper confidence bound (GP-UCB) and Thompson sampling (TS) are well-known options with established theoretical properties regarding Bayesian cumulative regret (BCR). Recently, it has been shown that a randomized variant of GP-UCB achieves a tighter BCR bound compared with GP-UCB, which we call the tighter BCR bound for brevity. Inspired by this study, this paper first shows that TS achieves the tighter BCR bound. On the other hand, GP-UCB and TS often practically suffer from manual hyperparameter tuning and over-exploration issues, respectively. Therefore, we analyze yet another AF called a probability of improvement from the maximum of a sample path (PIMS). We show that PIMS achieves the tighter BCR bound and avoids the hyperparameter tuning, unlike GP-UCB. Furthermore, we demonstrate a wide range of experiments, focusing on the effectiveness of PIMS that mitigates the practical issues of GP-UCB and TS.
Read more6/5/2024
🗣️
0
Regret Bounds for Noise-Free Cascaded Kernelized Bandits
Zihan Li, Jonathan Scarlett
We consider optimizing a function network in the noise-free grey-box setting with RKHS function classes, where the exact intermediate results are observable. We assume that the structure of the network is known (but not the underlying functions comprising it), and we study three types of structures: (1) chain: a cascade of scalar-valued functions, (2) multi-output chain: a cascade of vector-valued functions, and (3) feed-forward network: a fully connected feed-forward network of scalar-valued functions. We propose a sequential upper confidence bound based algorithm GPN-UCB along with a general theoretical upper bound on the cumulative regret. In addition, we propose a non-adaptive sampling based method along with its theoretical upper bound on the simple regret for the Mat'ern kernel. We also provide algorithm-independent lower bounds on the simple regret and cumulative regret. Our regret bounds for GPN-UCB have the same dependence on the time horizon as the best known in the vanilla black-box setting, as well as near-optimal dependencies on other parameters (e.g., RKHS norm and network length).
Read more5/14/2024
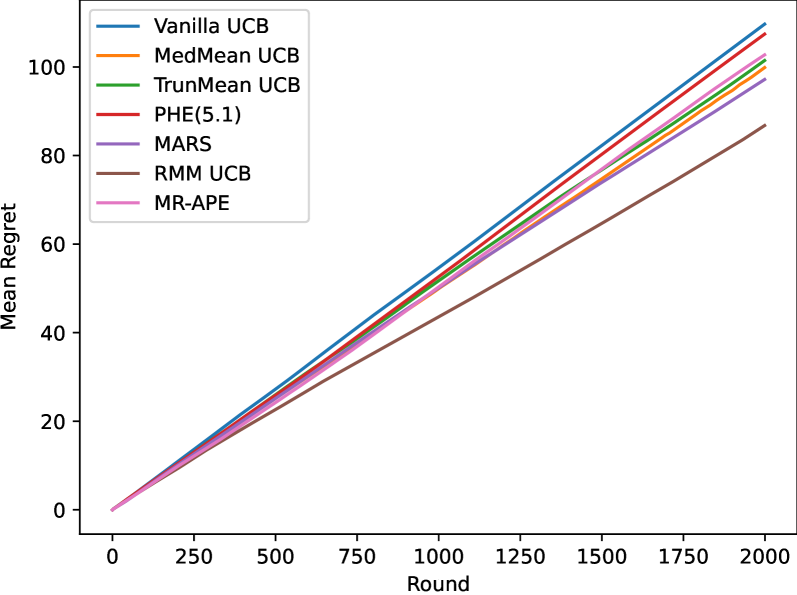
0
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
Read more6/11/2024