Posterior Sampling-Based Bayesian Optimization with Tighter Bayesian Regret Bounds

0
🛠️
Sign in to get full access
Overview
- Bayesian optimization (BO) is a powerful technique for optimizing expensive black-box functions
- Gaussian process upper confidence bound (GP-UCB) and Thompson sampling (TS) are well-known acquisition functions (AFs) used in BO
- Recent research has shown that a randomized variant of GP-UCB achieves a tighter Bayesian cumulative regret (BCR) bound compared to standard GP-UCB
- This paper explores whether TS and another AF called probability of improvement from the maximum of a sample path (PIMS) can also achieve this tighter BCR bound
- The paper also analyzes the practical advantages of PIMS over GP-UCB and TS
Plain English Explanation
Bayesian optimization is a technique used to efficiently find the best settings for complicated systems or processes. It works by building a statistical model of the system and then carefully exploring different settings to find the optimal one. Two popular methods used in Bayesian optimization are Gaussian process upper confidence bound (GP-UCB) and Thompson sampling (TS).
Recent research has shown that a modified version of GP-UCB can achieve better performance in terms of a metric called Bayesian cumulative regret (BCR), which measures how much the system's performance suffers while finding the optimal settings. This paper investigates whether TS can also achieve this improved BCR bound, and also looks at a new acquisition function called probability of improvement from the maximum of a sample path (PIMS).
The key advantage of PIMS is that it can avoid some of the practical issues with GP-UCB and TS, such as the need to carefully tune hyperparameters (GP-UCB) or the tendency to over-explore (TS). The paper demonstrates through experiments that PIMS can match the theoretical BCR guarantees of the modified GP-UCB, while also offering better practical performance in many cases.
Technical Explanation
This paper focuses on Bayesian optimization (BO), a powerful technique for optimizing expensive black-box functions. Within BO, the authors consider two well-known acquisition functions (AFs): Gaussian process upper confidence bound (GP-UCB) and Thompson sampling (TS).
The authors note that a randomized variant of GP-UCB has been shown to achieve a tighter Bayesian cumulative regret (BCR) bound compared to standard GP-UCB. Inspired by this, the paper first proves that TS also achieves this tighter BCR bound.
However, the authors point out that both GP-UCB and TS often suffer from practical issues, such as the need for manual hyperparameter tuning (GP-UCB) and a tendency towards over-exploration (TS). To address these problems, the authors analyze a new AF called probability of improvement from the maximum of a sample path (PIMS).
The key contributions of the paper are:
- Showing that TS achieves the tighter BCR bound, like the randomized variant of GP-UCB.
- Demonstrating that PIMS also achieves the tighter BCR bound, while avoiding the hyperparameter tuning issues of GP-UCB.
- Providing a wide range of experiments that highlight the effectiveness of PIMS in mitigating the practical problems of GP-UCB and TS.
Critical Analysis
The paper provides a thorough theoretical and empirical analysis of various acquisition functions in Bayesian optimization. The authors make a strong case for the practical advantages of the PIMS acquisition function, which appears to match the theoretical guarantees of the modified GP-UCB while offering improved performance in many real-world scenarios.
One potential limitation of the research is that the theoretical analysis focuses solely on the Bayesian cumulative regret (BCR) metric, which may not capture all aspects of practical performance. The authors acknowledge this and suggest that future work could explore other performance metrics.
Additionally, the paper does not provide much insight into the underlying reasons why PIMS outperforms GP-UCB and TS in practice. A deeper exploration of the mechanisms driving PIMS's advantages could further strengthen the conclusions and provide more guidance for practitioners.
Overall, this paper presents a valuable contribution to the Bayesian optimization literature by introducing a new acquisition function with appealing theoretical and practical properties. The findings encourage readers to think critically about the trade-offs between different BO approaches and to consider PIMS as a compelling alternative to more established methods.
Conclusion
This paper makes significant advancements in the field of Bayesian optimization by analyzing the theoretical and practical properties of various acquisition functions. The key takeaways are:
- Thompson sampling (TS) can achieve the same tighter Bayesian cumulative regret (BCR) bound as a randomized variant of Gaussian process upper confidence bound (GP-UCB).
- The authors introduce a new acquisition function called probability of improvement from the maximum of a sample path (PIMS), which also achieves the tighter BCR bound while avoiding the practical issues of GP-UCB and TS.
- The experimental results demonstrate that PIMS can outperform GP-UCB and TS in a wide range of real-world scenarios, making it a promising alternative for Bayesian optimization practitioners.
These findings have the potential to significantly impact the application of Bayesian optimization techniques, as PIMS offers a robust and effective approach that addresses many of the challenges associated with more established methods. The paper encourages researchers and practitioners to carefully consider the trade-offs between different acquisition functions and to explore the use of PIMS in their own optimization tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Posterior Sampling-Based Bayesian Optimization with Tighter Bayesian Regret Bounds
Shion Takeno, Yu Inatsu, Masayuki Karasuyama, Ichiro Takeuchi
Among various acquisition functions (AFs) in Bayesian optimization (BO), Gaussian process upper confidence bound (GP-UCB) and Thompson sampling (TS) are well-known options with established theoretical properties regarding Bayesian cumulative regret (BCR). Recently, it has been shown that a randomized variant of GP-UCB achieves a tighter BCR bound compared with GP-UCB, which we call the tighter BCR bound for brevity. Inspired by this study, this paper first shows that TS achieves the tighter BCR bound. On the other hand, GP-UCB and TS often practically suffer from manual hyperparameter tuning and over-exploration issues, respectively. Therefore, we analyze yet another AF called a probability of improvement from the maximum of a sample path (PIMS). We show that PIMS achieves the tighter BCR bound and avoids the hyperparameter tuning, unlike GP-UCB. Furthermore, we demonstrate a wide range of experiments, focusing on the effectiveness of PIMS that mitigates the practical issues of GP-UCB and TS.
Read more6/5/2024

0
Regret Analysis for Randomized Gaussian Process Upper Confidence Bound
Shion Takeno, Yu Inatsu, Masayuki Karasuyama
Gaussian process upper confidence bound (GP-UCB) is a theoretically established algorithm for Bayesian optimization (BO), where we assume the objective function $f$ follows GP. One notable drawback of GP-UCB is that the theoretical confidence parameter $beta$ increased along with the iterations is too large. To alleviate this drawback, this paper analyzes the randomized variant of GP-UCB called improved randomized GP-UCB (IRGP-UCB), which uses the confidence parameter generated from the shifted exponential distribution. We analyze the expected regret and conditional expected regret, where the expectation and the probability are taken respectively with $f$ and noises and with the randomness of the BO algorithm. In both regret analyses, IRGP-UCB achieves a sub-linear regret upper bound without increasing the confidence parameter if the input domain is finite. Finally, we show numerical experiments using synthetic and benchmark functions and real-world emulators.
Read more9/17/2024
0
Epsilon-Greedy Thompson Sampling to Bayesian Optimization
Bach Do, Taiwo Adebiyi, Ruda Zhang
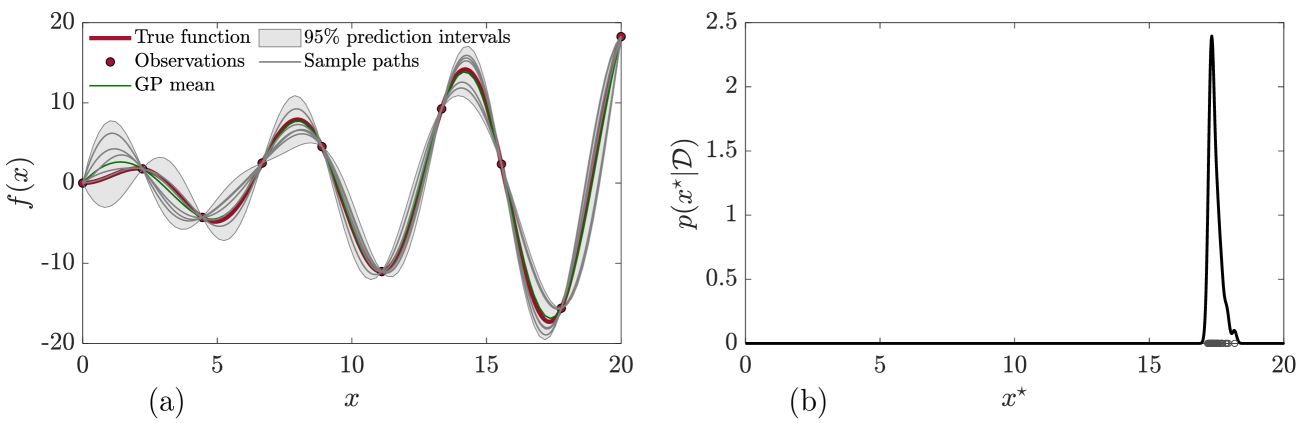
Bayesian optimization (BO) has become a powerful tool for solving simulation-based engineering optimization problems thanks to its ability to integrate physical and mathematical understandings, consider uncertainty, and address the exploitation--exploration dilemma. Thompson sampling (TS) is a preferred solution for BO to handle the exploitation--exploration trade-off. While it prioritizes exploration by generating and minimizing random sample paths from probabilistic models -- a fundamental ingredient of BO -- TS weakly manages exploitation by gathering information about the true objective function after it obtains new observations. In this work, we improve the exploitation of TS by incorporating the $varepsilon$-greedy policy, a well-established selection strategy in reinforcement learning. We first delineate two extremes of TS, namely the generic TS and the sample-average TS. The former promotes exploration, while the latter favors exploitation. We then adopt the $varepsilon$-greedy policy to randomly switch between these two extremes. Small and large values of $varepsilon$ govern exploitation and exploration, respectively. By minimizing two benchmark functions and solving an inverse problem of a steel cantilever beam,we empirically show that $varepsilon$-greedy TS equipped with an appropriate $varepsilon$ is more robust than its two extremes,matching or outperforming the better of the generic TS and the sample-average TS.
Read more5/7/2024
0
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
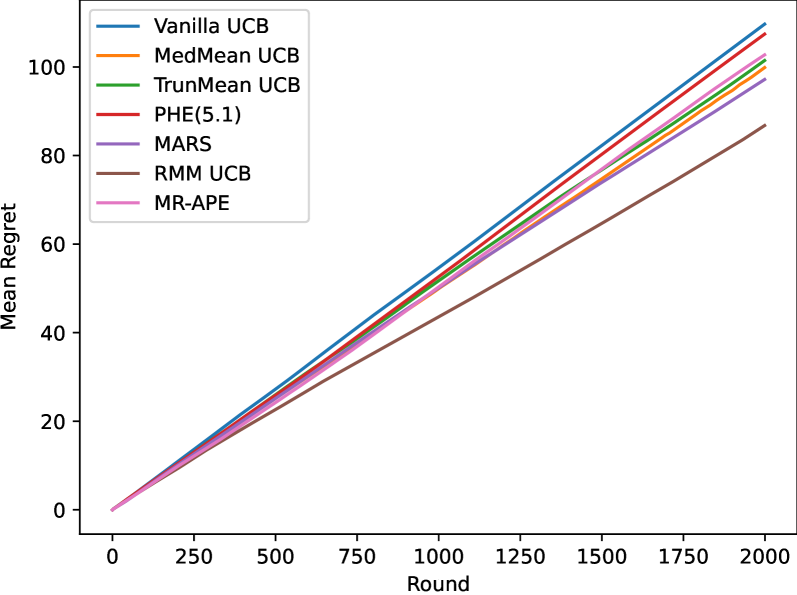
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
Read more6/11/2024