Regret Bounds for Noise-Free Cascaded Kernelized Bandits

0
🗣️
Sign in to get full access
Overview
- The paper explores optimizing a function network in a noise-free grey-box setting using RKHS (Reproducing Kernel Hilbert Space) function classes.
- The researchers assume the structure of the network is known but the underlying functions are unknown.
- Three network structures are studied: (1) chain, (2) multi-output chain, and (3) feed-forward network.
- The paper proposes a sequential upper confidence bound algorithm called GPN-UCB and provides theoretical upper bounds on the cumulative regret.
- A non-adaptive sampling method is also proposed with theoretical upper bounds on simple regret for the Mat'ern kernel.
- Algorithm-independent lower bounds on simple regret and cumulative regret are provided.
Plain English Explanation
In this research, the authors look at a problem where they have a network of functions, but they don't know exactly what those functions are. They call this a "grey-box" setting, meaning they have some information about the structure of the network, but not all the details.
The researchers consider three different types of network structures: a chain (where the functions are connected in a series), a multi-output chain (where each function produces multiple outputs), and a feed-forward network (where the functions are all connected to each other).
The goal is to find the best set of functions to use in the network to optimize some overall objective. To do this, the researchers propose two different algorithms:
-
GPN-UCB: This is a sequential algorithm that uses upper confidence bounds to guide the search for the optimal functions. The authors provide theoretical guarantees on how well this algorithm will perform.
-
Non-adaptive sampling: This is a simpler approach that doesn't adapt to the problem as it goes along. The authors show that this method also has good theoretical performance, at least for a particular type of function (the Mat'ern kernel).
In addition to these algorithms, the paper also provides lower bounds on the best possible performance that any algorithm can achieve. This helps put the results of the proposed algorithms in context.
The key idea behind this work is to leverage the known structure of the network to improve the optimization process, compared to treating the network as a black box. By using this additional information, the authors show that their algorithms can achieve similar performance guarantees as the best known black-box optimization methods, but with better dependence on other problem parameters.
Technical Explanation
The paper considers the problem of optimizing a function network in a noise-free grey-box setting, where the structure of the network is known but the underlying functions are not. Three types of network structures are studied:
- Chain: A cascade of scalar-valued functions.
- Multi-output chain: A cascade of vector-valued functions.
- Feed-forward network: A fully connected feed-forward network of scalar-valued functions.
The authors propose a sequential upper confidence bound algorithm called GPN-UCB, which leverages the known network structure to guide the search for the optimal functions. They provide a theoretical upper bound on the cumulative regret of this algorithm, showing that it has the same dependence on the time horizon as the best known black-box optimization methods, as well as near-optimal dependencies on other problem parameters (e.g., RKHS norm and network length).
In addition, the authors propose a non-adaptive sampling method and derive a theoretical upper bound on the simple regret for the Mat'ern kernel. They also provide algorithm-independent lower bounds on the simple regret and cumulative regret, which help put the performance of their algorithms in context.
Critical Analysis
The paper makes several important contributions, but also has some limitations and areas for further research:
Strengths:
- The proposed algorithms, GPN-UCB and non-adaptive sampling, provide strong theoretical guarantees on their performance.
- The analysis covers a range of network structures, going beyond the simple chain case.
- The lower bounds establish fundamental limits on the achievable performance, which is valuable for understanding the optimality of the proposed methods.
Limitations:
- The analysis is restricted to the noise-free setting, which may not always be realistic in practice.
- The assumption of known network structure may be strong in some applications, and it would be interesting to relax this.
- The non-adaptive sampling method is only analyzed for the Mat'ern kernel, and it's unclear how it would perform for other kernel functions.
Future research:
- Extending the analysis to noisy settings, as in BanditQ or limited adaptivity scenarios.
- Considering more general network structures, potentially with unknown connectivity.
- Developing efficient algorithms that can handle larger-scale networks and more complex function classes.
Overall, this paper makes important theoretical contributions to the understanding of function network optimization in grey-box settings, but there are still many exciting avenues for future research in this area.
Conclusion
This research explores the problem of optimizing a function network in a noise-free grey-box setting, where the structure of the network is known but the underlying functions are not. The authors propose two algorithms, GPN-UCB and non-adaptive sampling, and provide theoretical guarantees on their performance.
The key insights are that by leveraging the known network structure, the authors are able to achieve similar performance guarantees as the best known black-box optimization methods, but with better dependencies on other problem parameters. The lower bounds also provide valuable insights into the fundamental limits of this problem.
While the paper has some limitations, such as the focus on noise-free settings and known network structure, it opens up many interesting directions for future research in this area. As machine learning models become more complex, tools for optimizing function networks in grey-box settings will become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Regret Bounds for Noise-Free Cascaded Kernelized Bandits
Zihan Li, Jonathan Scarlett
We consider optimizing a function network in the noise-free grey-box setting with RKHS function classes, where the exact intermediate results are observable. We assume that the structure of the network is known (but not the underlying functions comprising it), and we study three types of structures: (1) chain: a cascade of scalar-valued functions, (2) multi-output chain: a cascade of vector-valued functions, and (3) feed-forward network: a fully connected feed-forward network of scalar-valued functions. We propose a sequential upper confidence bound based algorithm GPN-UCB along with a general theoretical upper bound on the cumulative regret. In addition, we propose a non-adaptive sampling based method along with its theoretical upper bound on the simple regret for the Mat'ern kernel. We also provide algorithm-independent lower bounds on the simple regret and cumulative regret. Our regret bounds for GPN-UCB have the same dependence on the time horizon as the best known in the vanilla black-box setting, as well as near-optimal dependencies on other parameters (e.g., RKHS norm and network length).
Read more5/14/2024

0
Regret Analysis for Randomized Gaussian Process Upper Confidence Bound
Shion Takeno, Yu Inatsu, Masayuki Karasuyama
Gaussian process upper confidence bound (GP-UCB) is a theoretically established algorithm for Bayesian optimization (BO), where we assume the objective function $f$ follows GP. One notable drawback of GP-UCB is that the theoretical confidence parameter $beta$ increased along with the iterations is too large. To alleviate this drawback, this paper analyzes the randomized variant of GP-UCB called improved randomized GP-UCB (IRGP-UCB), which uses the confidence parameter generated from the shifted exponential distribution. We analyze the expected regret and conditional expected regret, where the expectation and the probability are taken respectively with $f$ and noises and with the randomness of the BO algorithm. In both regret analyses, IRGP-UCB achieves a sub-linear regret upper bound without increasing the confidence parameter if the input domain is finite. Finally, we show numerical experiments using synthetic and benchmark functions and real-world emulators.
Read more9/17/2024
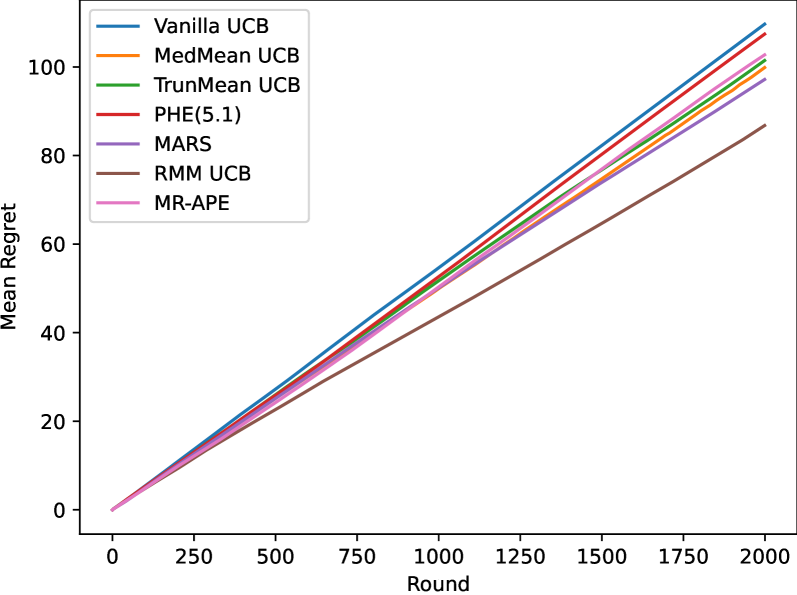
0
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
Read more6/11/2024
👨🏫
0
Open Problem: Tight Bounds for Kernelized Multi-Armed Bandits with Bernoulli Rewards
Marco Mussi, Simone Drago, Alberto Maria Metelli
We consider Kernelized Bandits (KBs) to optimize a function $f : mathcal{X} rightarrow [0,1]$ belonging to the Reproducing Kernel Hilbert Space (RKHS) $mathcal{H}_k$. Mainstream works on kernelized bandits focus on a subgaussian noise model in which observations of the form $f(mathbf{x}_t)+epsilon_t$, being $epsilon_t$ a subgaussian noise, are available (Chowdhury and Gopalan, 2017). Differently, we focus on the case in which we observe realizations $y_t sim text{Ber}(f(mathbf{x}_t))$ sampled from a Bernoulli distribution with parameter $f(mathbf{x}_t)$. While the Bernoulli model has been investigated successfully in multi-armed bandits (Garivier and Capp'e, 2011), logistic bandits (Faury et al., 2022), bandits in metric spaces (Magureanu et al., 2014), it remains an open question whether tight results can be obtained for KBs. This paper aims to draw the attention of the online learning community to this open problem.
Read more7/10/2024