Regularized Conditional Diffusion Model for Multi-Task Preference Alignment
2404.04920
0
0
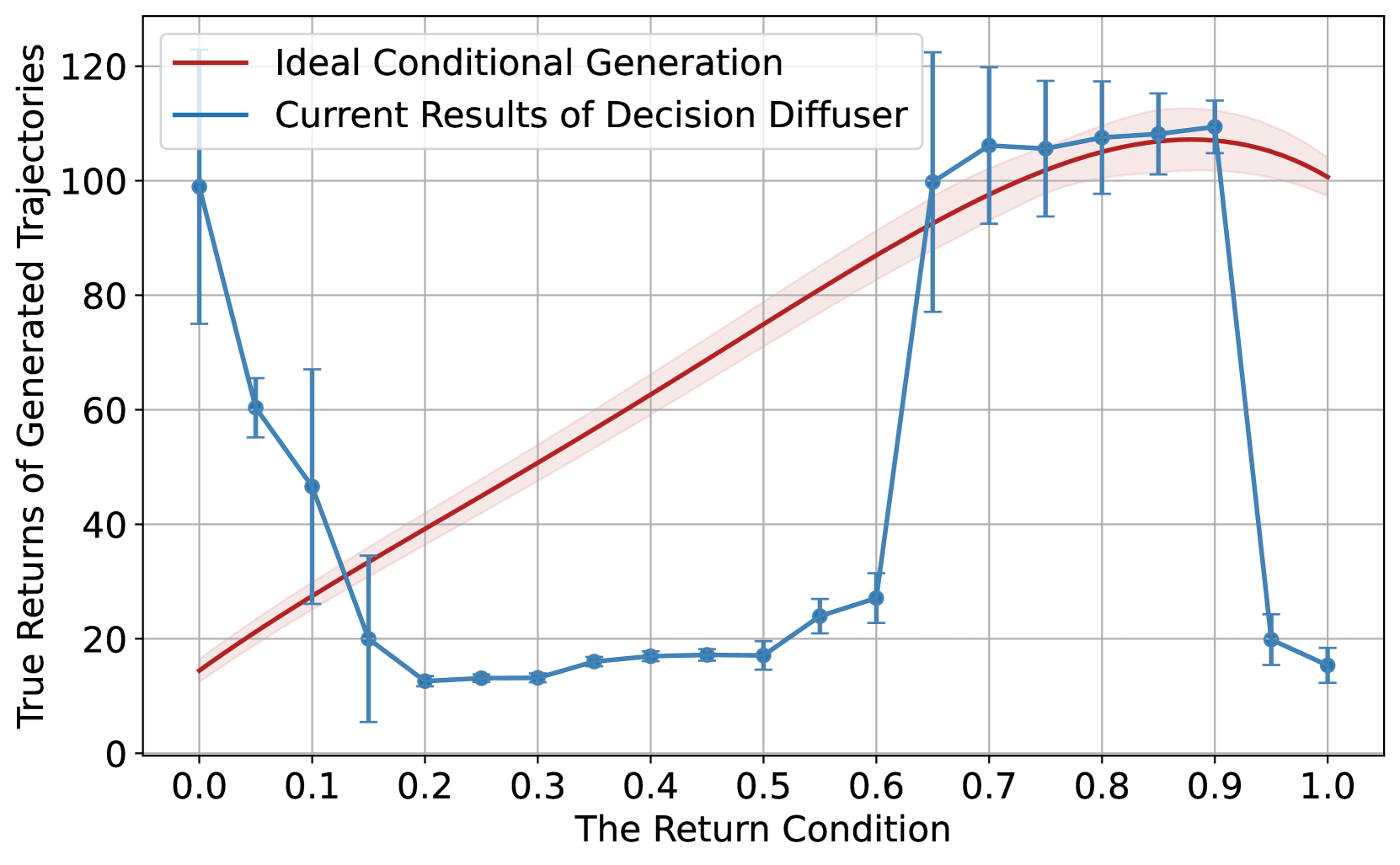
Abstract
Sequential decision-making is desired to align with human intents and exhibit versatility across various tasks. Previous methods formulate it as a conditional generation process, utilizing return-conditioned diffusion models to directly model trajectory distributions. Nevertheless, the return-conditioned paradigm relies on pre-defined reward functions, facing challenges when applied in multi-task settings characterized by varying reward functions (versatility) and showing limited controllability concerning human preferences (alignment). In this work, we adopt multi-task preferences as a unified condition for both single- and multi-task decision-making, and propose preference representations aligned with preference labels. The learned representations are used to guide the conditional generation process of diffusion models, and we introduce an auxiliary objective to maximize the mutual information between representations and corresponding generated trajectories, improving alignment between trajectories and preferences. Extensive experiments in D4RL and Meta-World demonstrate that our method presents favorable performance in single- and multi-task scenarios, and exhibits superior alignment with preferences.
Create account to get full access
Overview
- Proposes a regularized conditional diffusion model for aligning AI systems with human preferences across multiple tasks
- Leverages diffusion models to capture complex reward functions and handle high-dimensional state/action spaces
- Introduces a regularization term to encourage the model to learn general preferences that transfer across tasks
- Demonstrates the approach on simulated environments and real-world robotic control tasks
Plain English Explanation
The paper presents a new machine learning approach called a "Regularized Conditional Diffusion Model" for training AI systems to align with human preferences across multiple tasks. The key idea is to use a type of generative model called a "diffusion model" to capture the complex reward functions that humans care about, rather than relying on simple numerical rewards.
Diffusion models work by gradually adding noise to data (like images) and then learning to reverse that process, allowing them to generate new samples that match the original data distribution. The researchers show how this same approach can be applied to multi-task preference alignment, where the AI needs to learn general preferences that transfer across different tasks.
To encourage the model to learn these transferable preferences, the researchers introduce a "regularization term" that penalizes the model if it learns task-specific quirks instead of broad principles. This helps the model generalize better and behave consistently across a variety of situations.
The paper demonstrates the effectiveness of this approach on both simulated environments and real-world robotic control tasks, showing that it can outperform alternative methods for aligning AI systems with human preferences.
Technical Explanation
The core of the paper is a "regularized conditional diffusion model" for multi-task preference alignment. Diffusion models work by gradually adding noise to data (like images) and then learning to reverse that process, allowing them to generate new samples that match the original data distribution.
In this case, the researchers use diffusion models to capture complex reward functions that encode human preferences, rather than relying on simple numerical rewards. To make the model generalize across tasks, they introduce a regularization term that penalizes the model if it learns task-specific quirks instead of broad principles.
The model is trained using a combination of task-specific and general preference data, with the regularization term encouraging the model to find a balance between task-specific and transferable knowledge. This allows the model to perform well on a variety of tasks while maintaining consistent and human-aligned behavior.
The paper evaluates the approach on both simulated environments and real-world robotic control tasks, demonstrating that it can outperform alternative methods for aligning AI systems with human preferences.
Critical Analysis
The paper presents a novel and promising approach to the challenge of aligning AI systems with human preferences, particularly in complex, high-dimensional settings. The use of diffusion models to capture reward functions is an interesting and potentially powerful technique, as it allows the model to learn rich and nuanced representations of what humans care about.
However, the paper does not fully address the potential limitations and challenges of this approach. For example, the reliance on human-provided preference data raises questions about the scalability and robustness of the method, as well as potential biases in the data. Additionally, the paper does not explore the interpretability of the learned preferences, which could be an important consideration for real-world deployment.
Furthermore, the paper focuses on simulated and relatively constrained robotic control tasks, and it remains to be seen how well the approach would generalize to more complex, real-world decision-making scenarios. Further research and validation on a broader range of applications would be valuable to better understand the strengths and limitations of this approach.
Conclusion
Overall, the Regularized Conditional Diffusion Model presents a promising step forward in the challenge of aligning AI systems with human preferences. By leveraging the expressive power of diffusion models and introducing a novel regularization technique, the researchers have developed an approach that can capture complex reward functions and generalize across multiple tasks.
While the paper raises some unanswered questions and potential limitations, it represents an important contribution to the field of AI alignment and sets the stage for further exploration and development of these techniques. As AI systems become more advanced and ubiquitous, finding ways to reliably align their behavior with human values will be crucial for ensuring the safe and beneficial deployment of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
A Dense Reward View on Aligning Text-to-Image Diffusion with Preference
Shentao Yang, Tianqi Chen, Mingyuan Zhou
0
0
Aligning text-to-image diffusion model (T2I) with preference has been gaining increasing research attention. While prior works exist on directly optimizing T2I by preference data, these methods are developed under the bandit assumption of a latent reward on the entire diffusion reverse chain, while ignoring the sequential nature of the generation process. This may harm the efficacy and efficiency of preference alignment. In this paper, we take on a finer dense reward perspective and derive a tractable alignment objective that emphasizes the initial steps of the T2I reverse chain. In particular, we introduce temporal discounting into DPO-style explicit-reward-free objectives, to break the temporal symmetry therein and suit the T2I generation hierarchy. In experiments on single and multiple prompt generation, our method is competitive with strong relevant baselines, both quantitatively and qualitatively. Further investigations are conducted to illustrate the insight of our approach.
5/14/2024
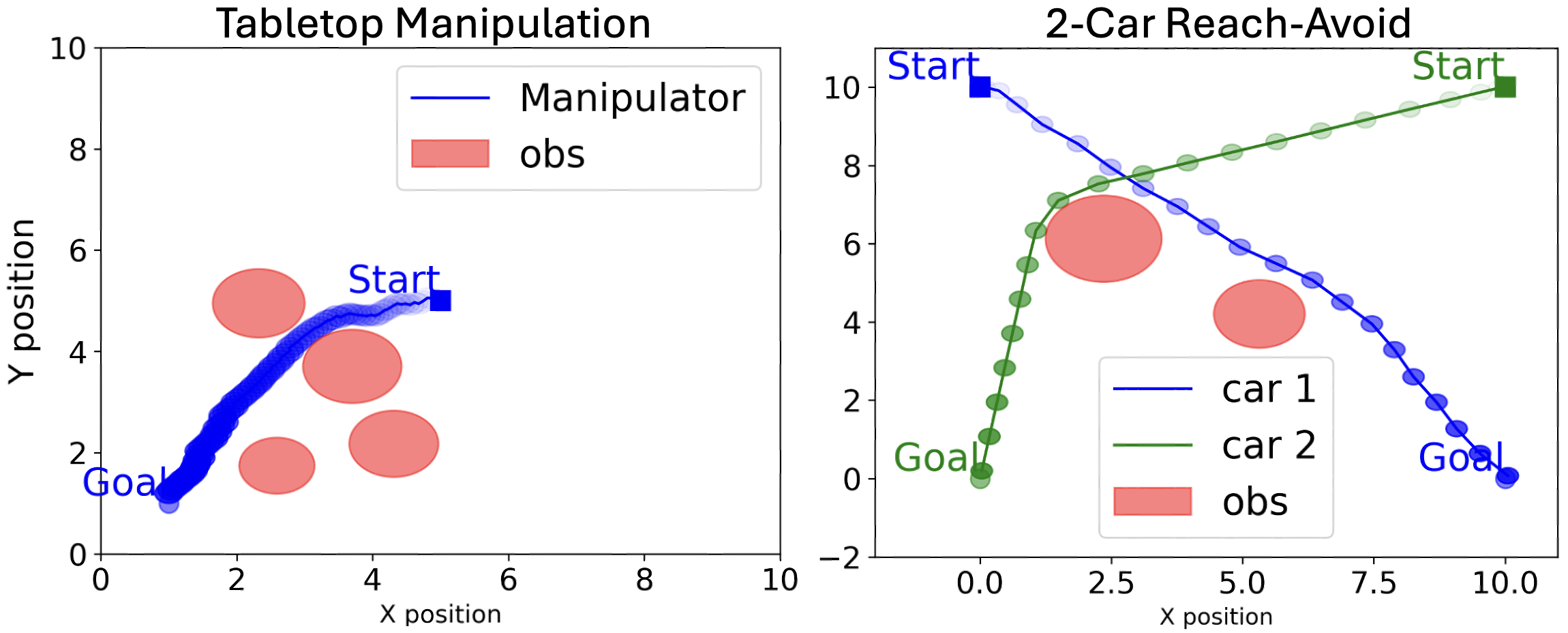
Constraint-Aware Diffusion Models for Trajectory Optimization
Anjian Li, Zihan Ding, Adji Bousso Dieng, Ryne Beeson
0
0
The diffusion model has shown success in generating high-quality and diverse solutions to trajectory optimization problems. However, diffusion models with neural networks inevitably make prediction errors, which leads to constraint violations such as unmet goals or collisions. This paper presents a novel constraint-aware diffusion model for trajectory optimization. We introduce a novel hybrid loss function for training that minimizes the constraint violation of diffusion samples compared to the groundtruth while recovering the original data distribution. Our model is demonstrated on tabletop manipulation and two-car reach-avoid problems, outperforming traditional diffusion models in minimizing constraint violations while generating samples close to locally optimal solutions.
6/4/2024
🤷
Aligning Crowd Feedback via Distributional Preference Reward Modeling
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, Yong Liu
0
0
Deep Reinforcement Learning is widely used for aligning Large Language Models (LLM) with human preference. However, the conventional reward modelling is predominantly dependent on human annotations provided by a select cohort of individuals. Such dependence may unintentionally result in skewed models that reflect the inclinations of these annotators, thereby failing to adequately represent the wider population's expectations. We propose the Distributional Preference Reward Model (DPRM), a simple yet effective framework to align large language models with diverse human preferences. To this end, we characterize multiple preferences by a categorical distribution and introduce a Bayesian updater to accommodate shifted or new preferences. On top of that, we design an optimal-transportation-based loss to calibrate DPRM to align with the preference distribution. Finally, the expected reward is utilized to fine-tune an LLM policy to generate responses favoured by the population. Our experiments show that DPRM significantly enhances the alignment of LLMs with population preference, yielding more accurate, unbiased, and contextually appropriate responses.
5/31/2024

Adding Conditional Control to Diffusion Models with Reinforcement Learning
Yulai Zhao, Masatoshi Uehara, Gabriele Scalia, Tommaso Biancalani, Sergey Levine, Ehsan Hajiramezanali
0
0
Diffusion models are powerful generative models that allow for precise control over the characteristics of the generated samples. While these diffusion models trained on large datasets have achieved success, there is often a need to introduce additional controls in downstream fine-tuning processes, treating these powerful models as pre-trained diffusion models. This work presents a novel method based on reinforcement learning (RL) to add additional controls, leveraging an offline dataset comprising inputs and corresponding labels. We formulate this task as an RL problem, with the classifier learned from the offline dataset and the KL divergence against pre-trained models serving as the reward functions. We introduce our method, $textbf{CTRL}$ ($textbf{C}$onditioning pre-$textbf{T}$rained diffusion models with $textbf{R}$einforcement $textbf{L}$earning), which produces soft-optimal policies that maximize the abovementioned reward functions. We formally demonstrate that our method enables sampling from the conditional distribution conditioned on additional controls during inference. Our RL-based approach offers several advantages over existing methods. Compared to commonly used classifier-free guidance, our approach improves sample efficiency, and can greatly simplify offline dataset construction by exploiting conditional independence between the inputs and additional controls. Furthermore, unlike classifier guidance, we avoid the need to train classifiers from intermediate states to additional controls.
6/19/2024