Evaluating Class Membership Relations in Knowledge Graphs using Large Language Models
2404.17000
0
0

Abstract
A backbone of knowledge graphs are their class membership relations, which assign entities to a given class. As part of the knowledge engineering process, we propose a new method for evaluating the quality of these relations by processing descriptions of a given entity and class using a zero-shot chain-of-thought classifier that uses a natural language intensional definition of a class. We evaluate the method using two publicly available knowledge graphs, Wikidata and CaLiGraph, and 7 large language models. Using the gpt-4-0125-preview large language model, the method's classification performance achieves a macro-averaged F1-score of 0.830 on data from Wikidata and 0.893 on data from CaLiGraph. Moreover, a manual analysis of the classification errors shows that 40.9% of errors were due to the knowledge graphs, with 16.0% due to missing relations and 24.9% due to incorrectly asserted relations. These results show how large language models can assist knowledge engineers in the process of knowledge graph refinement. The code and data are available on Github.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) to evaluate class membership relations in knowledge graphs.
- The researchers investigate how well LLMs can identify whether a given entity belongs to a particular class or category in a knowledge graph.
- They compare the performance of LLMs to traditional knowledge graph techniques and find that LLMs can outperform these methods in certain scenarios.
Plain English Explanation
Knowledge graphs are digital representations of information that show how different concepts and entities are related to one another. For example, a knowledge graph might capture the fact that "Paris" is a city, and that cities are a type of "location."
In this paper, the researchers explore how well large language models (LLMs) - powerful AI systems trained on vast amounts of text data - can be used to evaluate these class membership relations in knowledge graphs. Rather than relying on traditional knowledge graph techniques, which can be brittle and require a lot of carefully curated data, the researchers investigate whether LLMs can more flexibly and accurately determine whether a given entity belongs to a particular class or category.
The key insight is that LLMs, through their broad training on natural language, may be able to capture more nuanced semantic relationships between entities and classes than traditional methods. This could make LLMs a powerful tool for refining and enhancing knowledge graphs, which are essential for powering real-world AI applications.
Technical Explanation
The researchers conduct experiments on several benchmark knowledge graph datasets, evaluating how well different LLM architectures (such as BERT and GPT-3) can determine class membership relations compared to traditional techniques like rule-based reasoning and neural link prediction.
They find that in many cases, the LLMs are able to outperform the traditional methods, particularly on more complex or ambiguous class membership questions. The LLMs seem to leverage their broad understanding of language and concepts to better capture the nuances of how entities relate to classes.
The researchers also explore ways to fine-tune and adapt the LLMs to the specific knowledge graph domain, further boosting their performance. This suggests that LLMs could be a versatile and powerful tool for enhancing and refining knowledge graphs, complementing more traditional techniques.
Critical Analysis
The paper provides a thorough and well-designed experimental evaluation of the LLM approach. However, the researchers acknowledge some key limitations:
- The performance of the LLMs can still be inconsistent, and they may struggle with rare or complex class membership relations.
- Fine-tuning the LLMs requires additional data and computational resources, which may not always be feasible.
- The paper focuses on a specific task of class membership evaluation, and more research is needed to understand how well LLMs can handle other knowledge graph reasoning and refinement challenges.
Additionally, while the results are promising, it's important to consider potential biases or blindspots in the LLM's training data and how that could affect their performance on knowledge graph tasks. Further research is needed to fully understand the strengths, weaknesses, and appropriate use cases for LLMs in this domain.
Conclusion
Overall, this paper presents a compelling case for the use of large language models to enhance knowledge graph reasoning and refinement. The experimental results suggest that LLMs can outperform traditional techniques in certain scenarios, leveraging their broad semantic understanding to better capture nuanced class membership relations.
While there are still some limitations and open questions, this work highlights the potential for LLMs to be a valuable tool in the knowledge engineering toolbox, complementing other approaches and helping to build more robust and accurate knowledge graphs. As LLMs continue to advance, it will be exciting to see how they can be further applied and refined for knowledge graph-related tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
Relations Prediction for Knowledge Graph Completion using Large Language Models
Sakher Khalil Alqaaidi, Krzysztof Kochut
0
0
Knowledge Graphs have been widely used to represent facts in a structured format. Due to their large scale applications, knowledge graphs suffer from being incomplete. The relation prediction task obtains knowledge graph completion by assigning one or more possible relations to each pair of nodes. In this work, we make use of the knowledge graph node names to fine-tune a large language model for the relation prediction task. By utilizing the node names only we enable our model to operate sufficiently in the inductive settings. Our experiments show that we accomplish new scores on a widely used knowledge graph benchmark.
5/7/2024
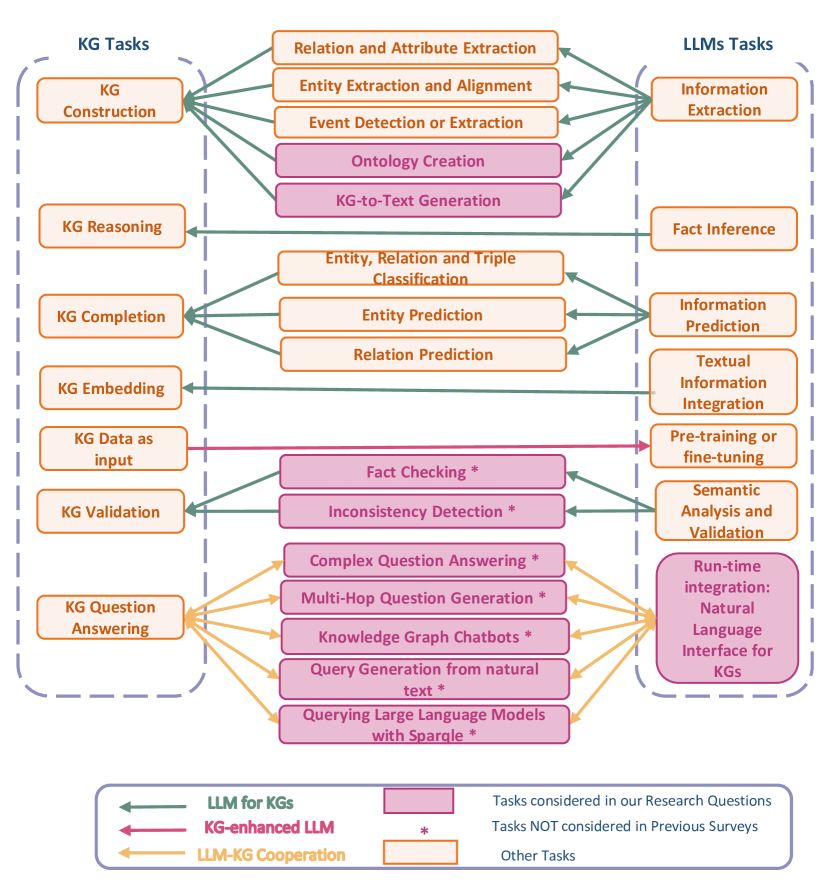
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Hanieh Khorashadizadeh, Fatima Zahra Amara, Morteza Ezzabady, Fr'ed'eric Ieng, Sanju Tiwari, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Farah Benamara, Sven Groppe
0
0
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
6/13/2024
💬
Multi-hop Question Answering over Knowledge Graphs using Large Language Models
Abir Chakraborty
0
0
Knowledge graphs (KGs) are large datasets with specific structures representing large knowledge bases (KB) where each node represents a key entity and relations amongst them are typed edges. Natural language queries formed to extract information from a KB entail starting from specific nodes and reasoning over multiple edges of the corresponding KG to arrive at the correct set of answer nodes. Traditional approaches of question answering on KG are based on (a) semantic parsing (SP), where a logical form (e.g., S-expression, SPARQL query, etc.) is generated using node and edge embeddings and then reasoning over these representations or tuning language models to generate the final answer directly, or (b) information-retrieval based that works by extracting entities and relations sequentially. In this work, we evaluate the capability of (LLMs) to answer questions over KG that involve multiple hops. We show that depending upon the size and nature of the KG we need different approaches to extract and feed the relevant information to an LLM since every LLM comes with a fixed context window. We evaluate our approach on six KGs with and without the availability of example-specific sub-graphs and show that both the IR and SP-based methods can be adopted by LLMs resulting in an extremely competitive performance.
5/1/2024

New!Chain-of-Knowledge: Integrating Knowledge Reasoning into Large Language Models by Learning from Knowledge Graphs
Yifei Zhang, Xintao Wang, Jiaqing Liang, Sirui Xia, Lida Chen, Yanghua Xiao
0
0
Large Language Models (LLMs) have exhibited impressive proficiency in various natural language processing (NLP) tasks, which involve increasingly complex reasoning. Knowledge reasoning, a primary type of reasoning, aims at deriving new knowledge from existing one.While it has been widely studied in the context of knowledge graphs (KGs), knowledge reasoning in LLMs remains underexplored. In this paper, we introduce Chain-of-Knowledge, a comprehensive framework for knowledge reasoning, including methodologies for both dataset construction and model learning. For dataset construction, we create KnowReason via rule mining on KGs. For model learning, we observe rule overfitting induced by naive training. Hence, we enhance CoK with a trial-and-error mechanism that simulates the human process of internal knowledge exploration. We conduct extensive experiments with KnowReason. Our results show the effectiveness of CoK in refining LLMs in not only knowledge reasoning, but also general reasoning benchmarkms.
7/2/2024