Reliable Representations Learning for Incomplete Multi-View Partial Multi-Label Classification

0
🏷️
Sign in to get full access
Overview
- Multi-view multi-label classification is a growing field that combines multi-view learning and multi-label classification.
- Applying multi-view contrastive learning has further advanced this field, but existing methods have issues with how they handle negative pairs and missing data.
- This paper proposes a new model called RANK that addresses these problems.
Plain English Explanation
RANK is a machine learning model that can work with multi-view data and partial multi-label data. In multi-view data, each object has multiple "views" or representations, like an image and text description. Partial multi-label data means some objects are missing labels or have incomplete label information.
The key innovations in RANK are:
-
Label-driven contrastive learning: RANK uses the label information to guide how it compares and aligns the different views of an object, rather than just separating "negative" pairs randomly.
-
Quality-aware sub-network: RANK dynamically evaluates the quality or reliability of each view for each object, rather than treating all views equally.
-
Leveraging label correlations: RANK fully utilizes the relationships between the different labels to improve its final multi-label classification performance.
These techniques allow RANK to work well even when there are missing views or labels in the dataset. The authors show RANK outperforms other state-of-the-art methods on a variety of benchmarks.
Technical Explanation
The core of RANK is a multi-view contrastive learning strategy that leverages the available label information. Rather than randomly pairing views as positive and negative examples, RANK uses the labels to identify views that should be aligned (positive) and views that should be separated (negative).
RANK also includes a "quality-aware sub-network" that dynamically assigns quality scores to each view of each sample. This allows RANK to prioritize the more reliable views when making predictions.
Finally, RANK's multi-label classification loss function explicitly models the relationships between the different labels, further boosting its performance.
RANK is evaluated on several standard multi-view multi-label datasets, including some with missing views and labels. The results show RANK outperforms other state-of-the-art methods, demonstrating the benefits of its label-driven contrastive learning, quality-aware weighting, and leveraging of label correlations.
Critical Analysis
The authors thoroughly evaluate RANK and provide strong empirical evidence of its advantages. However, the paper does not deeply explore the limitations or potential downsides of the approach.
For example, the dynamic view weighting scheme could be sensitive to noisy or unreliable quality scores, which could negatively impact performance. The authors also do not discuss how RANK might scale to datasets with a very large number of labels or views.
Additionally, while the authors claim RANK can handle missing views and labels, the extent of this capability is not fully characterized. More analysis on the model's robustness to different levels and patterns of missing data could provide a clearer understanding of its practical applicability.
Overall, the RANK model represents a promising advance in multi-view multi-label classification, but further research is needed to fully understand its strengths, weaknesses, and the scope of problems it can effectively address.
Conclusion
This paper proposes a novel multi-view multi-label classification model called RANK that outperforms existing state-of-the-art methods. The key innovations include a label-driven contrastive learning strategy, a quality-aware view weighting mechanism, and the explicit modeling of label correlations.
RANK's ability to handle incomplete data, along with its strong empirical performance, suggests it could be a valuable tool for a variety of real-world applications that involve multi-view and multi-label data. Further research is needed to fully characterize the model's capabilities and limitations, but this work represents an important step forward in this growing field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Reliable Representations Learning for Incomplete Multi-View Partial Multi-Label Classification
Chengliang Liu, Jie Wen, Yong Xu, Bob Zhang, Liqiang Nie, Min Zhang
As a cross-topic of multi-view learning and multi-label classification, multi-view multi-label classification has gradually gained traction in recent years. The application of multi-view contrastive learning has further facilitated this process, however, the existing multi-view contrastive learning methods crudely separate the so-called negative pair, which largely results in the separation of samples belonging to the same category or similar ones. Besides, plenty of multi-view multi-label learning methods ignore the possible absence of views and labels. To address these issues, in this paper, we propose an incomplete multi-view partial multi-label classification network named RANK. In this network, a label-driven multi-view contrastive learning strategy is proposed to leverage supervised information to preserve the structure within view and perform consistent alignment across views. Furthermore, we break through the view-level weights inherent in existing methods and propose a quality-aware sub-network to dynamically assign quality scores to each view of each sample. The label correlation information is fully utilized in the final multi-label cross-entropy classification loss, effectively improving the discriminative power. Last but not least, our model is not only able to handle complete multi-view multi-label datasets, but also works on datasets with missing instances and labels. Extensive experiments confirm that our RANK outperforms existing state-of-the-art methods.
Read more8/27/2024
🤿
0
Masked Two-channel Decoupling Framework for Incomplete Multi-view Weak Multi-label Learning
Chengliang Liu, Jie Wen, Yabo Liu, Chao Huang, Zhihao Wu, Xiaoling Luo, Yong Xu
Multi-view learning has become a popular research topic in recent years, but research on the cross-application of classic multi-label classification and multi-view learning is still in its early stages. In this paper, we focus on the complex yet highly realistic task of incomplete multi-view weak multi-label learning and propose a masked two-channel decoupling framework based on deep neural networks to solve this problem. The core innovation of our method lies in decoupling the single-channel view-level representation, which is common in deep multi-view learning methods, into a shared representation and a view-proprietary representation. We also design a cross-channel contrastive loss to enhance the semantic property of the two channels. Additionally, we exploit supervised information to design a label-guided graph regularization loss, helping the extracted embedding features preserve the geometric structure among samples. Inspired by the success of masking mechanisms in image and text analysis, we develop a random fragment masking strategy for vector features to improve the learning ability of encoders. Finally, it is important to emphasize that our model is fully adaptable to arbitrary view and label absences while also performing well on the ideal full data. We have conducted sufficient and convincing experiments to confirm the effectiveness and advancement of our model.
Read more4/29/2024

0
Task-Augmented Cross-View Imputation Network for Partial Multi-View Incomplete Multi-Label Classification
Xiaohuan Lu, Lian Zhao, Wai Keung Wong, Jie Wen, Jiang Long, Wulin Xie
In real-world scenarios, multi-view multi-label learning often encounters the challenge of incomplete training data due to limitations in data collection and unreliable annotation processes. The absence of multi-view features impairs the comprehensive understanding of samples, omitting crucial details essential for classification. To address this issue, we present a task-augmented cross-view imputation network (TACVI-Net) for the purpose of handling partial multi-view incomplete multi-label classification. Specifically, we employ a two-stage network to derive highly task-relevant features to recover the missing views. In the first stage, we leverage the information bottleneck theory to obtain a discriminative representation of each view by extracting task-relevant information through a view-specific encoder-classifier architecture. In the second stage, an autoencoder based multi-view reconstruction network is utilized to extract high-level semantic representation of the augmented features and recover the missing data, thereby aiding the final classification task. Extensive experiments on five datasets demonstrate that our TACVI-Net outperforms other state-of-the-art methods.
Read more9/14/2024
0
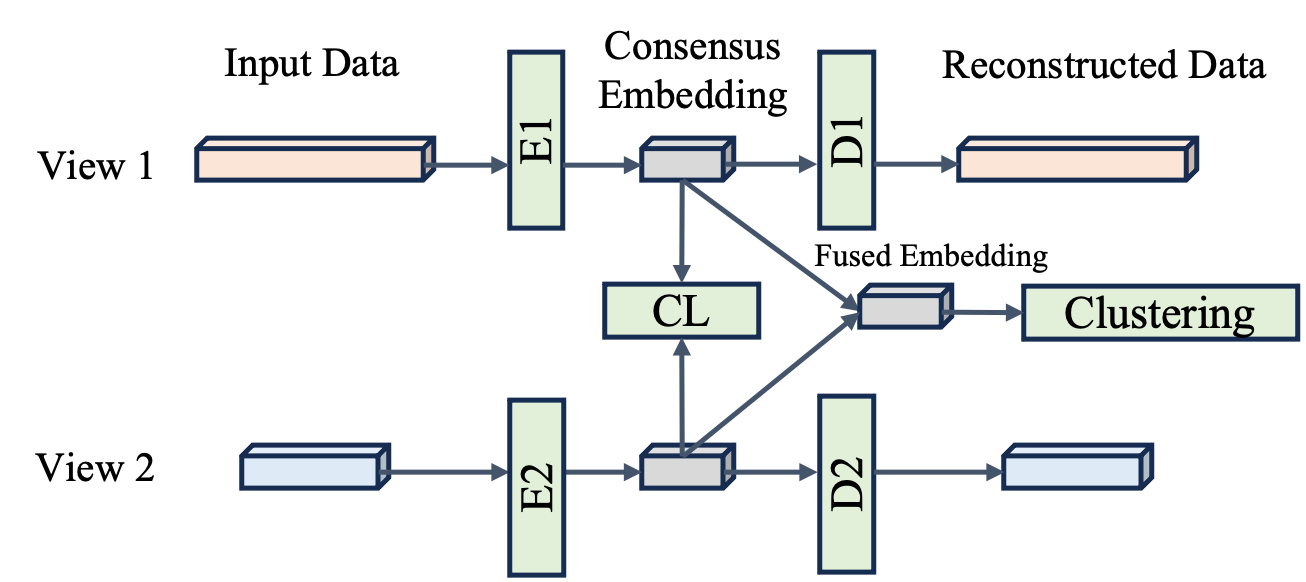
URRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering
Ge Teng, Ting Mao, Chen Shen, Xiang Tian, Xuesong Liu, Yaowu Chen, Jieping Ye
Incomplete multi-view clustering (IMVC) aims to cluster multi-view data that are only partially available. This poses two main challenges: effectively leveraging multi-view information and mitigating the impact of missing views. Prevailing solutions employ cross-view contrastive learning and missing view recovery techniques. However, they either neglect valuable complementary information by focusing only on consensus between views or provide unreliable recovered views due to the absence of supervision. To address these limitations, we propose a novel Unified and Robust Representation Learning for Incomplete Multi-View Clustering (URRL-IMVC). URRL-IMVC directly learns a unified embedding that is robust to view missing conditions by integrating information from multiple views and neighboring samples. Firstly, to overcome the limitations of cross-view contrastive learning, URRL-IMVC incorporates an attention-based auto-encoder framework to fuse multi-view information and generate unified embeddings. Secondly, URRL-IMVC directly enhances the robustness of the unified embedding against view-missing conditions through KNN imputation and data augmentation techniques, eliminating the need for explicit missing view recovery. Finally, incremental improvements are introduced to further enhance the overall performance, such as the Clustering Module and the customization of the Encoder. We extensively evaluate the proposed URRL-IMVC framework on various benchmark datasets, demonstrating its state-of-the-art performance. Furthermore, comprehensive ablation studies are performed to validate the effectiveness of our design.
Read more7/15/2024