URRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering

0
Sign in to get full access
Overview
- This paper presents a new approach called URRL-IMVC (Unified and Robust Representation Learning for Incomplete Multi-View Clustering) for learning robust and unified representations from incomplete multi-view data.
- The method addresses the challenge of incomplete multi-view data, where some views may be missing for certain samples, by learning a shared representation across all views.
- URRL-IMVC uses a self-supervised pretraining strategy and an end-to-end clustering framework to learn a robust and unified feature representation, which is then used for incomplete multi-view clustering.
Plain English Explanation
In machine learning, multi-view data refers to datasets where each data sample has multiple different "views" or representations, such as images, text, and audio. This can be useful for tasks like classification or clustering, as the different views can provide complementary information.
However, incomplete multi-view data is a common challenge, where some data samples may be missing one or more of the views. This makes it difficult to learn a unified representation that can effectively use all the available information.
The URRL-IMVC method proposed in this paper aims to address this challenge. It learns a shared, robust representation across all the available views, even when some views are missing. This is done through a self-supervised pretraining step, where the model learns to predict the missing views from the available ones.
The learned representation is then used in an end-to-end clustering framework, allowing the model to group the data samples into clusters based on the robust, unified features. This approach is related to other work on unpaired multi-view clustering and multi-level reliable guidance for unpaired multi-view data.
By learning a shared, robust representation even when some views are missing, URRL-IMVC can improve the performance of multi-view clustering compared to methods that require complete data or cannot handle missing views effectively.
Technical Explanation
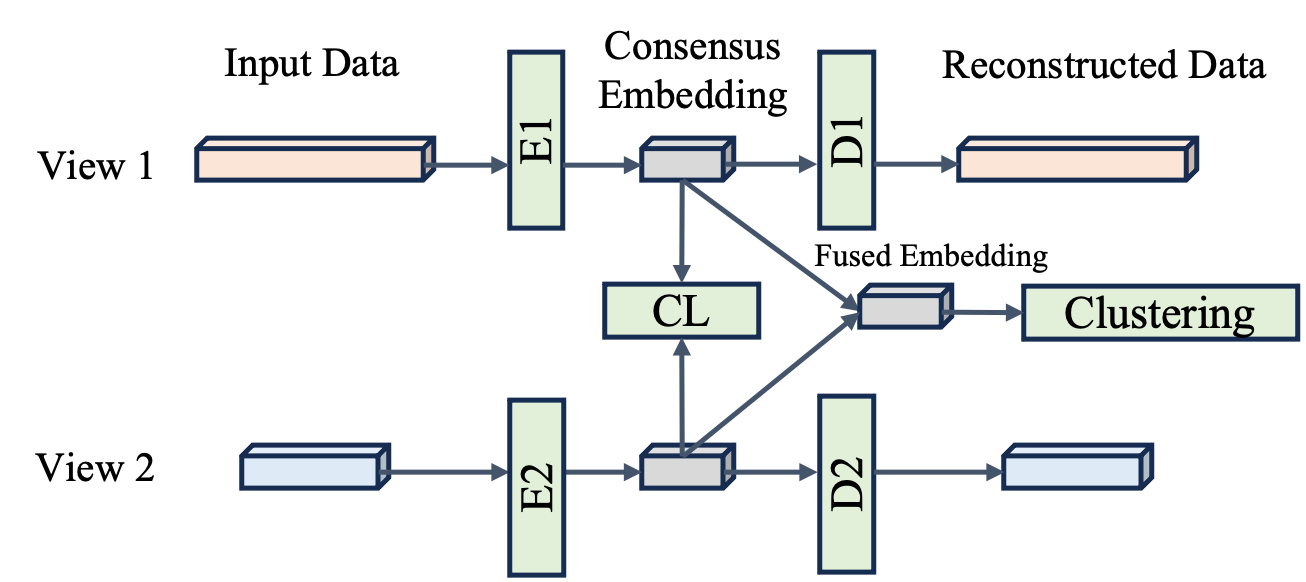
The URRL-IMVC method consists of two main components:
-
Self-supervised Pretraining: The model first learns a shared representation across all views through a self-supervised pretraining task. This involves training the model to predict the missing views from the available views, forcing it to learn a unified representation that can capture the relationships between the different views.
-
End-to-end Clustering: The pretrained representation is then used in an end-to-end clustering framework, where the model simultaneously learns the clustering assignments and refines the shared representation. This allows the model to learn a structured latent representation that is optimized for the clustering task.
The model architecture includes encoder networks to extract features from each view, and a shared projection head that maps the features into a common latent space. Manifold-based techniques are used to handle the incomplete data and learn the robust representation.
The authors evaluate URRL-IMVC on several benchmark datasets for incomplete multi-view clustering, comparing it to state-of-the-art methods. The results show that URRL-IMVC achieves significant improvements in clustering performance, demonstrating the effectiveness of the unified and robust representation learning approach.
Critical Analysis
The paper presents a well-designed and thorough approach to the important problem of incomplete multi-view clustering. The use of self-supervised pretraining and the end-to-end clustering framework are well-justified and appear to be effective based on the experimental results.
One potential limitation is that the method may still struggle with cases where the available views have very little overlap or correlation. The authors mention that the approach relies on learning a shared representation across the views, which could be challenging if the views are truly uncorrelated. Further research may be needed to address this edge case.
Additionally, the paper does not provide much discussion on the computational complexity or training time of the URRL-IMVC method. As with many deep learning approaches, the training process may be computationally intensive, which could limit its practical applicability in some scenarios.
Overall, the URRL-IMVC method represents a significant contribution to the field of multi-modal representation learning and incomplete multi-view clustering. The robust and unified representations learned by the model could have wider applications beyond just clustering tasks.
Conclusion
The URRL-IMVC paper presents a novel approach to learning a shared, robust representation from incomplete multi-view data. By using self-supervised pretraining and an end-to-end clustering framework, the method can effectively handle missing views and improve the performance of multi-view clustering.
The technical contributions of the paper, including the use of manifold-based techniques and the jointly learned representation, represent significant advances in the field of multi-view learning. While there are some potential limitations to address, the URRL-IMVC method shows promising results and could have important implications for a wide range of applications that rely on multi-view data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
URRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering
Ge Teng, Ting Mao, Chen Shen, Xiang Tian, Xuesong Liu, Yaowu Chen, Jieping Ye
Incomplete multi-view clustering (IMVC) aims to cluster multi-view data that are only partially available. This poses two main challenges: effectively leveraging multi-view information and mitigating the impact of missing views. Prevailing solutions employ cross-view contrastive learning and missing view recovery techniques. However, they either neglect valuable complementary information by focusing only on consensus between views or provide unreliable recovered views due to the absence of supervision. To address these limitations, we propose a novel Unified and Robust Representation Learning for Incomplete Multi-View Clustering (URRL-IMVC). URRL-IMVC directly learns a unified embedding that is robust to view missing conditions by integrating information from multiple views and neighboring samples. Firstly, to overcome the limitations of cross-view contrastive learning, URRL-IMVC incorporates an attention-based auto-encoder framework to fuse multi-view information and generate unified embeddings. Secondly, URRL-IMVC directly enhances the robustness of the unified embedding against view-missing conditions through KNN imputation and data augmentation techniques, eliminating the need for explicit missing view recovery. Finally, incremental improvements are introduced to further enhance the overall performance, such as the Clustering Module and the customization of the Encoder. We extensively evaluate the proposed URRL-IMVC framework on various benchmark datasets, demonstrating its state-of-the-art performance. Furthermore, comprehensive ablation studies are performed to validate the effectiveness of our design.
Read more7/15/2024
🔗
0
Unpaired Multi-view Clustering via Reliable View Guidance
Like Xin, Wanqi Yang, Lei Wang, Ming Yang
This paper focuses on unpaired multi-view clustering (UMC), a challenging problem where paired observed samples are unavailable across multiple views. The goal is to perform effective joint clustering using the unpaired observed samples in all views. In incomplete multi-view clustering, existing methods typically rely on sample pairing between views to capture their complementary. However, that is not applicable in the case of UMC. Hence, we aim to extract the consistent cluster structure across views. In UMC, two challenging issues arise: uncertain cluster structure due to lack of label and uncertain pairing relationship due to absence of paired samples. We assume that the view with a good cluster structure is the reliable view, which acts as a supervisor to guide the clustering of the other views. With the guidance of reliable views, a more certain cluster structure of these views is obtained while achieving alignment between reliable views and other views. Then we propose Reliable view Guidance with one reliable view (RG-UMC) and multiple reliable views (RGs-UMC) for UMC. Specifically, we design alignment modules with one reliable view and multiple reliable views, respectively, to adaptively guide the optimization process. Also, we utilize the compactness module to enhance the relationship of samples within the same cluster. Meanwhile, an orthogonal constraint is applied to latent representation to obtain discriminate features. Extensive experiments show that both RG-UMC and RGs-UMC outperform the best state-of-the-art method by an average of 24.14% and 29.42% in NMI, respectively.
Read more4/30/2024

0
Multi-level Reliable Guidance for Unpaired Multi-view Clustering
Like Xin, Wanqi Yang, Lei Wang, Ming Yang
In this paper, we address the challenging problem of unpaired multi-view clustering (UMC), aiming to perform effective joint clustering using unpaired observed samples across multiple views. Commonly, traditional incomplete multi-view clustering (IMC) methods often depend on paired samples to capture complementary information between views. However, the strategy becomes impractical in UMC due to the absence of paired samples. Although some researchers have attempted to tackle the issue by preserving consistent cluster structures across views, they frequently neglect the confidence of these cluster structures, especially for boundary samples and uncertain cluster structures during the initial training. Therefore, we propose a method called Multi-level Reliable Guidance for UMC (MRG-UMC), which leverages multi-level clustering to aid in learning a trustworthy cluster structure across inner-view, cross-view, and common-view, respectively. Specifically, within each view, multi-level clustering fosters a trustworthy cluster structure across different levels and reduces clustering error. In cross-view learning, reliable view guidance enhances the confidence of the cluster structures in other views. Similarly, within the multi-level framework, the incorporation of a common view aids in aligning different views, thereby reducing the clustering error and uncertainty of cluster structure. Finally, as evidenced by extensive experiments, our method for UMC demonstrates significant efficiency improvements compared to 20 state-of-the-art methods.
Read more7/2/2024
🏷️
0
Reliable Representations Learning for Incomplete Multi-View Partial Multi-Label Classification
Chengliang Liu, Jie Wen, Yong Xu, Bob Zhang, Liqiang Nie, Min Zhang
As a cross-topic of multi-view learning and multi-label classification, multi-view multi-label classification has gradually gained traction in recent years. The application of multi-view contrastive learning has further facilitated this process, however, the existing multi-view contrastive learning methods crudely separate the so-called negative pair, which largely results in the separation of samples belonging to the same category or similar ones. Besides, plenty of multi-view multi-label learning methods ignore the possible absence of views and labels. To address these issues, in this paper, we propose an incomplete multi-view partial multi-label classification network named RANK. In this network, a label-driven multi-view contrastive learning strategy is proposed to leverage supervised information to preserve the structure within view and perform consistent alignment across views. Furthermore, we break through the view-level weights inherent in existing methods and propose a quality-aware sub-network to dynamically assign quality scores to each view of each sample. The label correlation information is fully utilized in the final multi-label cross-entropy classification loss, effectively improving the discriminative power. Last but not least, our model is not only able to handle complete multi-view multi-label datasets, but also works on datasets with missing instances and labels. Extensive experiments confirm that our RANK outperforms existing state-of-the-art methods.
Read more8/27/2024