RELIANCE: Reliable Ensemble Learning for Information and News Credibility Evaluation
2401.10940
0
0
➖
Abstract
In the era of information proliferation, discerning the credibility of news content poses an ever-growing challenge. This paper introduces RELIANCE, a pioneering ensemble learning system designed for robust information and fake news credibility evaluation. Comprising five diverse base models, including Support Vector Machine (SVM), naive Bayes, logistic regression, random forest, and Bidirectional Long Short Term Memory Networks (BiLSTMs), RELIANCE employs an innovative approach to integrate their strengths, harnessing the collective intelligence of the ensemble for enhanced accuracy. Experiments demonstrate the superiority of RELIANCE over individual models, indicating its efficacy in distinguishing between credible and non-credible information sources. RELIANCE, also surpasses baseline models in information and news credibility assessment, establishing itself as an effective solution for evaluating the reliability of information sources.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces RELIANCE, a novel ensemble learning system for evaluating the credibility of information and detecting fake news.
- RELIANCE combines five diverse machine learning models, including Support Vector Machines (SVMs), naive Bayes, logistic regression, random forests, and Bidirectional Long Short Term Memory Networks (BiLSTMs).
- The ensemble approach allows RELIANCE to leverage the strengths of each individual model, resulting in improved accuracy in distinguishing credible and non-credible information sources.
Plain English Explanation
In today's world, where information is readily available from countless sources, it can be challenging to determine the credibility of news and other online content. The RELIANCE system aims to address this problem by using a combination of different machine learning models to evaluate the trustworthiness of information sources.
The researchers behind RELIANCE have developed an ensemble system that brings together five distinct models, each with its own strengths. These include widely used techniques like Support Vector Machines, naive Bayes, and logistic regression, as well as more advanced approaches like random forests and Bidirectional Long Short Term Memory Networks.
By combining the insights from these different models, RELIANCE can make more accurate judgments about whether a given information source is credible or not. This is a significant improvement over relying on a single model, as each approach has its own strengths and weaknesses. The ensemble approach allows RELIANCE to capitalize on the collective intelligence of the various models, leading to more reliable results.
Technical Explanation
The RELIANCE system is designed to assess the credibility of information sources using an ensemble learning approach. The researchers have incorporated five diverse machine learning models into the system: Support Vector Machines (SVMs), naive Bayes, logistic regression, random forests, and Bidirectional Long Short Term Memory Networks (BiLSTMs).
The ensemble approach allows RELIANCE to leverage the strengths of each individual model, resulting in improved accuracy in distinguishing credible and non-credible information sources. The researchers conducted experiments to evaluate the performance of RELIANCE, and the results demonstrate that the ensemble system outperforms the individual models, establishing it as an effective solution for evaluating the reliability of information sources.
Critical Analysis
The paper provides a thorough evaluation of the RELIANCE system, including comparisons to baseline models. However, the authors do not delve into the potential limitations or caveats of their approach. For instance, it would be beneficial to understand how RELIANCE performs on different types of information sources or in the face of evolving fake news tactics.
Additionally, the paper does not address potential biases or imbalances in the dataset used for training and evaluation. These factors can significantly impact the system's performance in real-world scenarios, and it would be valuable for the researchers to acknowledge and discuss these concerns.
Further research could explore the generalizability of RELIANCE to different domains or languages, as well as its scalability in handling large-scale information sources. Incorporating user feedback or leveraging external knowledge bases could also be explored to enhance the system's credibility assessments.
Conclusion
The RELIANCE system represents a significant step forward in the quest to combat the proliferation of misinformation and fake news. By integrating five diverse machine learning models into an ensemble approach, the researchers have developed a robust and accurate tool for evaluating the credibility of information sources.
The results of the experiments conducted in this paper highlight the potential of RELIANCE to be an effective solution for organizations, policymakers, and individuals seeking to navigate the complex landscape of online content. As the challenges of information credibility continue to evolve, the insights and techniques presented in this work can serve as a foundation for further advancements in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Reliability Estimation of News Media Sources: Birds of a Feather Flock Together
Sergio Burdisso, Dairazalia S'anchez-Cort'es, Esa'u Villatoro-Tello, Petr Motlicek
0
0
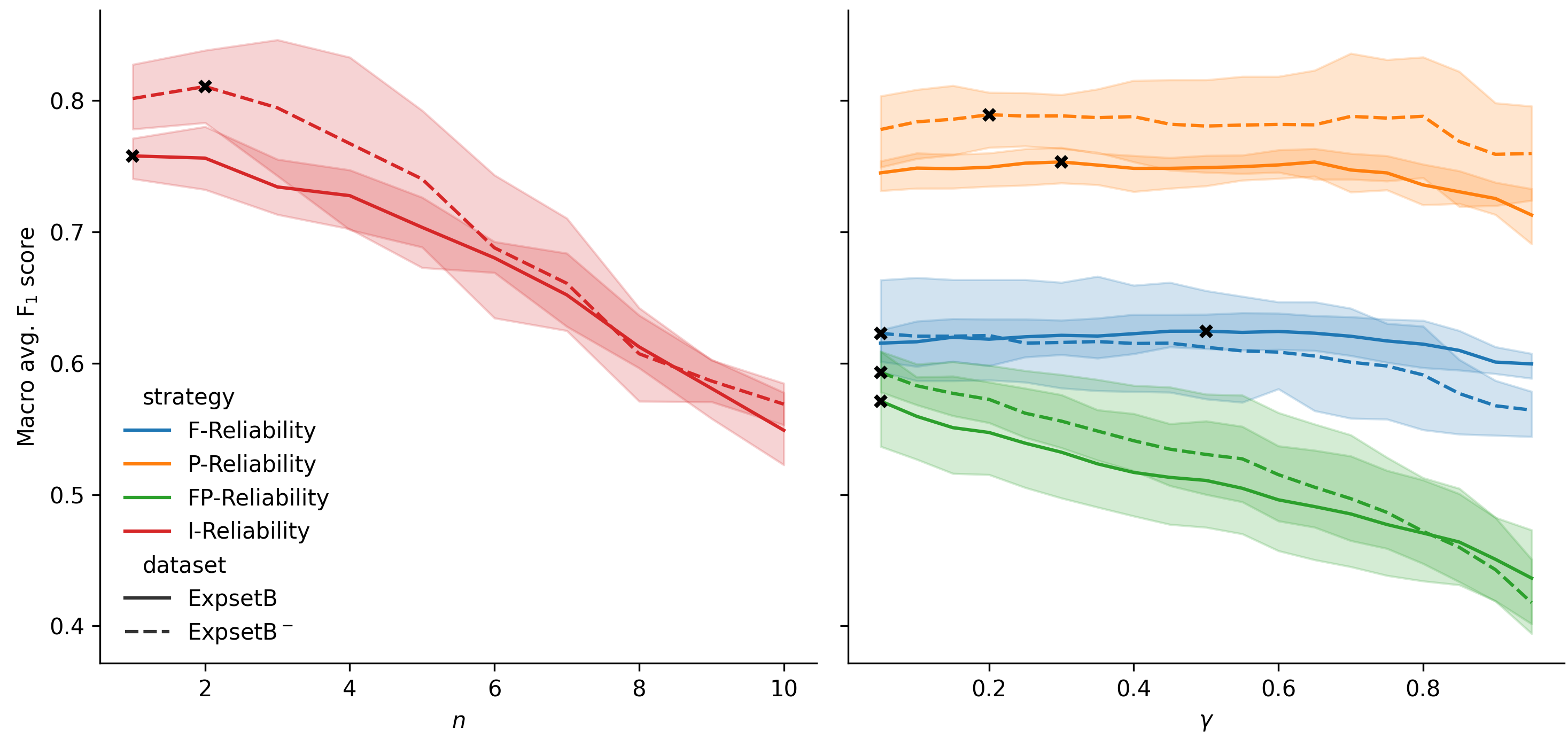
Evaluating the reliability of news sources is a routine task for journalists and organizations committed to acquiring and disseminating accurate information. Recent research has shown that predicting sources' reliability represents an important first-prior step in addressing additional challenges such as fake news detection and fact-checking. In this paper, we introduce a novel approach for source reliability estimation that leverages reinforcement learning strategies for estimating the reliability degree of news sources. Contrary to previous research, our proposed approach models the problem as the estimation of a reliability degree, and not a reliability label, based on how all the news media sources interact with each other on the Web. We validated the effectiveness of our method on a news media reliability dataset that is an order of magnitude larger than comparable existing datasets. Results show that the estimated reliability degrees strongly correlates with journalists-provided scores (Spearman=0.80) and can effectively predict reliability labels (macro-avg. F$_1$ score=81.05). We release our implementation and dataset, aiming to provide a valuable resource for the NLP community working on information verification.
4/16/2024
📈
Finding fake reviews in e-commerce platforms by using hybrid algorithms
Mathivanan Periasamy, Rohith Mahadevan, Bagiya Lakshmi S, Raja CSP Raman, Hasan Kumar S, Jasper Jessiman
0
0
Sentiment analysis, a vital component in natural language processing, plays a crucial role in understanding the underlying emotions and opinions expressed in textual data. In this paper, we propose an innovative ensemble approach for sentiment analysis for finding fake reviews that amalgamate the predictive capabilities of Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Decision Tree classifiers. Our ensemble architecture strategically combines these diverse models to capitalize on their strengths while mitigating inherent weaknesses, thereby achieving superior accuracy and robustness in fake review prediction. By combining all the models of our classifiers, the predictive performance is boosted and it also fosters adaptability to varied linguistic patterns and nuances present in real-world datasets. The metrics accounted for on fake reviews demonstrate the efficacy and competitiveness of the proposed ensemble method against traditional single-model approaches. Our findings underscore the potential of ensemble techniques in advancing the state-of-the-art in finding fake reviews using hybrid algorithms, with implications for various applications in different social media and e-platforms to find the best reviews and neglect the fake ones, eliminating puffery and bluffs.
4/10/2024
REQUAL-LM: Reliability and Equity through Aggregation in Large Language Models
Sana Ebrahimi, Nima Shahbazi, Abolfazl Asudeh
0
0
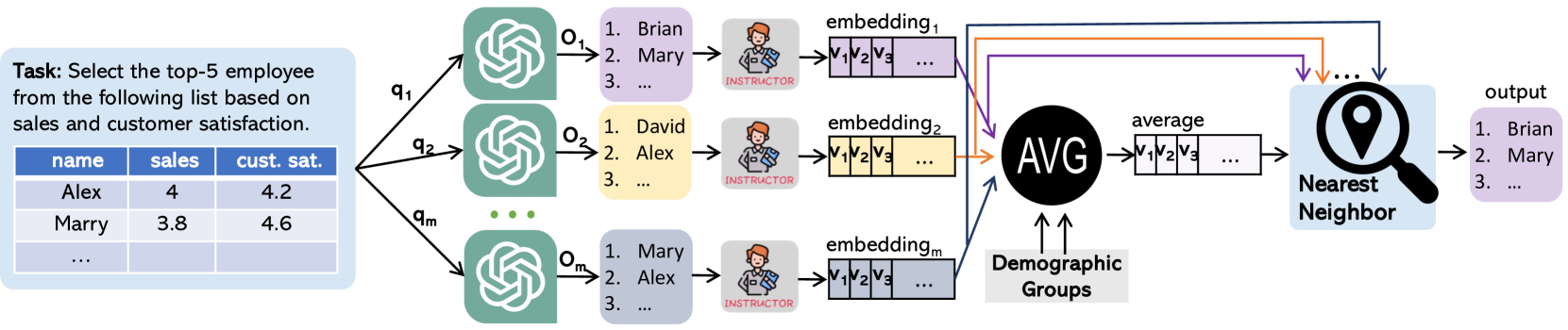
The extensive scope of large language models (LLMs) across various domains underscores the critical importance of responsibility in their application, beyond natural language processing. In particular, the randomized nature of LLMs, coupled with inherent biases and historical stereotypes in data, raises critical concerns regarding reliability and equity. Addressing these challenges are necessary before using LLMs for applications with societal impact. Towards addressing this gap, we introduce REQUAL-LM, a novel method for finding reliable and equitable LLM outputs through aggregation. Specifically, we develop a Monte Carlo method based on repeated sampling to find a reliable output close to the mean of the underlying distribution of possible outputs. We formally define the terms such as reliability and bias, and design an equity-aware aggregation to minimize harmful bias while finding a highly reliable output. REQUAL-LM does not require specialized hardware, does not impose a significant computing load, and uses LLMs as a blackbox. This design choice enables seamless scalability alongside the rapid advancement of LLM technologies. Our system does not require retraining the LLMs, which makes it deployment ready and easy to adapt. Our comprehensive experiments using various tasks and datasets demonstrate that REQUAL- LM effectively mitigates bias and selects a more equitable response, specifically the outputs that properly represents minority groups.
4/19/2024
Credible, Unreliable or Leaked?: Evidence Verification for Enhanced Automated Fact-checking
Zacharias Chrysidis, Stefanos-Iordanis Papadopoulos, Symeon Papadopoulos, Panagiotis C. Petrantonakis
0
0
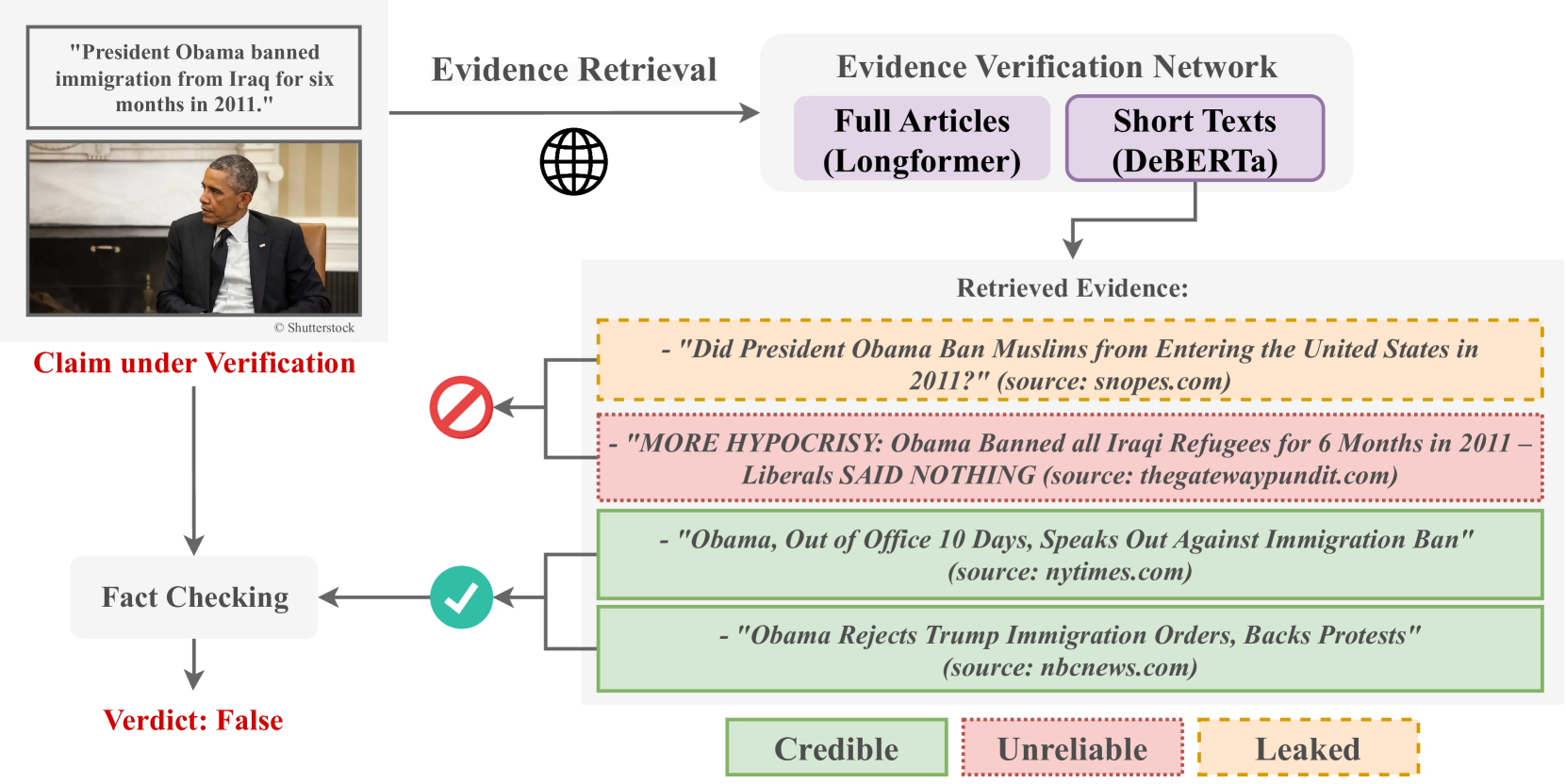
Automated fact-checking (AFC) is garnering increasing attention by researchers aiming to help fact-checkers combat the increasing spread of misinformation online. While many existing AFC methods incorporate external information from the Web to help examine the veracity of claims, they often overlook the importance of verifying the source and quality of collected evidence. One overlooked challenge involves the reliance on leaked evidence, information gathered directly from fact-checking websites and used to train AFC systems, resulting in an unrealistic setting for early misinformation detection. Similarly, the inclusion of information from unreliable sources can undermine the effectiveness of AFC systems. To address these challenges, we present a comprehensive approach to evidence verification and filtering. We create the CREDible, Unreliable or LEaked (CREDULE) dataset, which consists of 91,632 articles classified as Credible, Unreliable and Fact checked (Leaked). Additionally, we introduce the EVidence VERification Network (EVVER-Net), trained on CREDULE to detect leaked and unreliable evidence in both short and long texts. EVVER-Net can be used to filter evidence collected from the Web, thus enhancing the robustness of end-to-end AFC systems. We experiment with various language models and show that EVVER-Net can demonstrate impressive performance of up to 91.5% and 94.4% accuracy, while leveraging domain credibility scores along with short or long texts, respectively. Finally, we assess the evidence provided by widely-used fact-checking datasets including LIAR-PLUS, MOCHEG, FACTIFY, NewsCLIPpings+ and VERITE, some of which exhibit concerning rates of leaked and unreliable evidence.
5/1/2024