Remastering Divide and Remaster: A Cinematic Audio Source Separation Dataset with Multilingual Support

0
Sign in to get full access
Overview
- This paper presents a new dataset called "Remastering Divide and Remaster" (RDAREM) for cinematic audio source separation with multilingual support.
- The dataset contains high-quality audio recordings of various film scenes, with individual audio tracks for different elements like dialogue, music, and sound effects.
- The dataset aims to enable research and development of advanced audio source separation models that can handle the complexity of cinematic audio.
- The paper also discusses the dataset's setup, including the curation process, audio characteristics, and multilingual support.
Plain English Explanation
The researchers have created a new dataset called "Remastering Divide and Remaster" (RDAREM) that can be used to train and test audio source separation models. Audio source separation is the process of taking a mixed audio recording and separating it into its individual components, like dialogue, music, and sound effects.
This dataset is focused on cinematic audio, which can be particularly challenging because it often contains a complex mixture of different audio elements. The researchers have carefully curated high-quality audio recordings from various film scenes and labeled the individual tracks for each component, like the actors' dialogue, the background music, and the sound effects.
The dataset also supports multiple languages, which is important because cinematic audio can come from films and TV shows in different languages. This multilingual support will allow researchers to develop audio source separation models that can work with a wide range of content.
By providing this dataset, the researchers hope to enable more advanced research and development in the field of audio source separation, particularly for applications in film, television, and other multimedia contexts. The availability of this high-quality, diverse dataset can help drive progress in this important area of audio processing.
Technical Explanation
The RDAREM dataset is composed of high-quality audio recordings from various film scenes, with individual tracks labeled for different audio elements like dialogue, music, and sound effects. The dataset was curated by the researchers to provide a comprehensive resource for training and evaluating audio source separation models in the context of cinematic audio.
The dataset includes recordings in multiple languages, enabling the development of multilingual audio source separation models. This is particularly important for applications in the film and television industries, where content is often produced in diverse languages.
The researchers followed a thorough process to ensure the dataset's quality and diversity. They collected audio recordings from a range of film genres and production styles, and they carefully labeled the individual audio tracks to provide ground truth data for model training and evaluation.
The dataset's audio characteristics, such as sample rate, bit depth, and channel layout, were chosen to reflect the technical specifications typically used in professional audio production. This attention to detail helps ensure that the dataset is representative of real-world cinematic audio and can be used to develop models that are suitable for practical applications.
The availability of the RDAREM dataset provides a valuable resource for researchers and practitioners working on audio source separation, particularly in the context of cinematic audio. By offering high-quality, diverse, and multilingual data, the dataset can help drive advancements in this field and enable the development of more robust and versatile audio processing models.
Critical Analysis
The RDAREM dataset addresses an important need in the field of audio source separation by providing a comprehensive dataset focused on cinematic audio. The inclusion of multilingual support is a particularly valuable feature, as it allows researchers to develop models that can handle the linguistic diversity often found in film and television content.
However, the paper does not provide detailed information about the specific audio content and characteristics of the dataset, such as the distribution of audio elements (e.g., dialogue, music, sound effects) or the languages represented. This information would be helpful for researchers to better understand the dataset's scope and potential biases.
Additionally, the paper does not discuss potential limitations or challenges that may arise when using the dataset. For example, it does not address issues related to audio quality, recording conditions, or the potential presence of post-production processing that could impact the effectiveness of source separation models.
Further research could also explore the dataset's suitability for other audio-related tasks, such as speech recognition, music analysis, or audio event detection. Investigating the cross-task applicability of the RDAREM dataset could help expand its utility and impact.
Overall, the RDAREM dataset represents a valuable contribution to the field of audio source separation, particularly in the context of cinematic audio. However, additional details and analysis of the dataset's characteristics and limitations would be beneficial for researchers to better understand its potential and limitations.
Conclusion
The "Remastering Divide and Remaster" (RDAREM) dataset presented in this paper provides a significant resource for researchers and practitioners working on audio source separation, especially in the domain of cinematic audio. By offering high-quality, multilingual audio recordings with labeled individual tracks, the dataset enables the development and evaluation of advanced audio processing models that can handle the complexity of real-world cinematic audio.
The availability of this dataset is an important step forward in advancing the state of the art in audio source separation, with potential applications in film, television, and other multimedia contexts. The dataset's support for multiple languages is a particularly noteworthy feature, as it allows for the creation of models that can work with a diverse range of audio content.
While the paper could benefit from additional details and analysis of the dataset's characteristics and limitations, the RDAREM dataset represents a valuable contribution to the research community. By providing this resource, the authors have laid the groundwork for further advancements in audio source separation and related audio processing tasks, ultimately driving progress in the field and enhancing our experiences with multimedia content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Remastering Divide and Remaster: A Cinematic Audio Source Separation Dataset with Multilingual Support
Karn N. Watcharasupat, Chih-Wei Wu, Iroro Orife
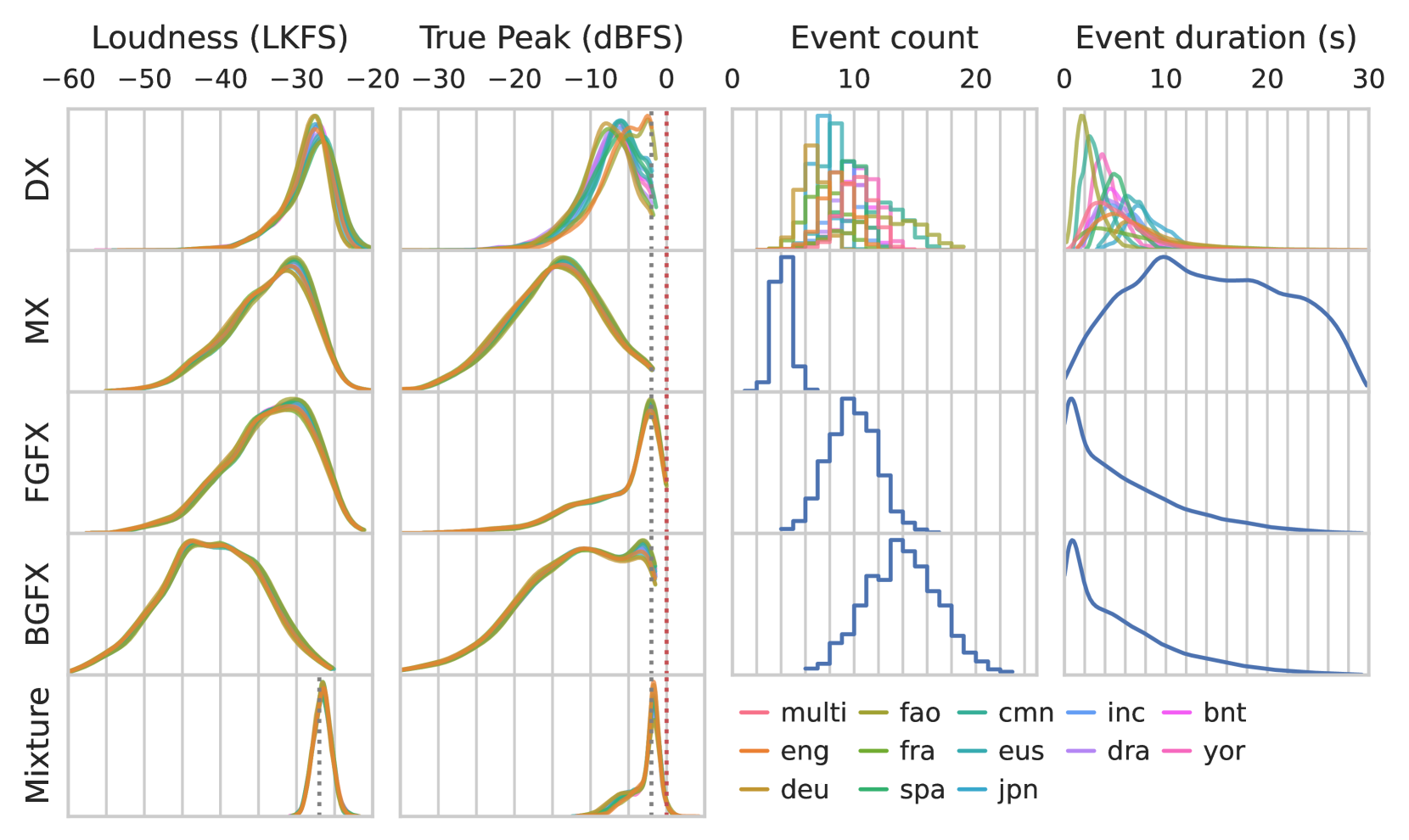
Cinematic audio source separation (CASS), as a problem of extracting the dialogue, music, and effects stems from their mixture, is a relatively new subtask of audio source separation. To date, only one publicly available dataset exists for CASS, that is, the Divide and Remaster (DnR) dataset, which is currently at version 2. While DnR v2 has been an incredibly useful resource for CASS, several areas of improvement have been identified, particularly through its use in the 2023 Sound Demixing Challenge. In this work, we develop version 3 of the DnR dataset, addressing issues relating to vocal content in non-dialogue stems, loudness distributions, mastering process, and linguistic diversity. In particular, the dialogue stem of DnR v3 includes speech content from more than 30 languages from multiple families including but not limited to the Germanic, Romance, Indo-Aryan, Dravidian, Malayo-Polynesian, and Bantu families. Benchmark results using the Bandit model indicated that training on multilingual data yields significant generalizability to the model even in languages with low data availability. Even in languages with high data availability, the multilingual model often performs on par or better than dedicated models trained on monolingual CASS datasets. Dataset and model implementation will be made available at https://github.com/kwatcharasupat/source-separation-landing.
Read more8/27/2024

0
Facing the Music: Tackling Singing Voice Separation in Cinematic Audio Source Separation
Karn N. Watcharasupat, Chih-Wei Wu, Iroro Orife
Cinematic audio source separation (CASS), as a standalone problem of extracting individual stems from their mixture, is a fairly new subtask of audio source separation. A typical setup of CASS is a three-stem problem, with the aim of separating the mixture into the dialogue (DX), music (MX), and effects (FX) stems. Given the creative nature of cinematic sound production, however, several edge cases exist; some sound sources do not fit neatly in any of these three stems, necessitating the use of additional auxiliary stems in production. One very common edge case is the singing voice in film audio, which may belong in either the DX or MX or neither, depending heavily on the cinematic context. In this work, we demonstrate a very straightforward extension of the dedicated-decoder Bandit and query-based single-decoder Banquet models to a four-stem problem, treating non-musical dialogue, instrumental music, singing voice, and effects as separate stems. Interestingly, the query-based Banquet model outperformed the dedicated-decoder Bandit model. We hypothesized that this is due to a better feature alignment at the bottleneck as enforced by the band-agnostic FiLM layer. Dataset and model implementation will be made available at https://github.com/kwatcharasupat/source-separation-landing.
Read more8/27/2024
🧠
0
The Sound Demixing Challenge 2023 $unicode{x2013}$ Cinematic Demixing Track
Stefan Uhlich, Giorgio Fabbro, Masato Hirano, Shusuke Takahashi, Gordon Wichern, Jonathan Le Roux, Dipam Chakraborty, Sharada Mohanty, Kai Li, Yi Luo, Jianwei Yu, Rongzhi Gu, Roman Solovyev, Alexander Stempkovskiy, Tatiana Habruseva, Mikhail Sukhovei, Yuki Mitsufuji
This paper summarizes the cinematic demixing (CDX) track of the Sound Demixing Challenge 2023 (SDX'23). We provide a comprehensive summary of the challenge setup, detailing the structure of the competition and the datasets used. Especially, we detail CDXDB23, a new hidden dataset constructed from real movies that was used to rank the submissions. The paper also offers insights into the most successful approaches employed by participants. Compared to the cocktail-fork baseline, the best-performing system trained exclusively on the simulated Divide and Remaster (DnR) dataset achieved an improvement of 1.8 dB in SDR, whereas the top-performing system on the open leaderboard, where any data could be used for training, saw a significant improvement of 5.7 dB. A significant source of this improvement was making the simulated data better match real cinematic audio, which we further investigate in detail.
Read more4/19/2024
👨🏫
0
Benchmarks and leaderboards for sound demixing tasks
Roman Solovyev, Alexander Stempkovskiy, Tatiana Habruseva
Music demixing is the task of separating different tracks from the given single audio signal into components, such as drums, bass, and vocals from the rest of the accompaniment. Separation of sources is useful for a range of areas, including entertainment and hearing aids. In this paper, we introduce two new benchmarks for the sound source separation tasks and compare popular models for sound demixing, as well as their ensembles, on these benchmarks. For the models' assessments, we provide the leaderboard at https://mvsep.com/quality_checker/, giving a comparison for a range of models. The new benchmark datasets are available for download. We also develop a novel approach for audio separation, based on the ensembling of different models that are suited best for the particular stem. The proposed solution was evaluated in the context of the Music Demixing Challenge 2023 and achieved top results in different tracks of the challenge. The code and the approach are open-sourced on GitHub.
Read more5/8/2024