Benchmarks and leaderboards for sound demixing tasks

0
👨🏫
Sign in to get full access
Overview
- The paper introduces two new benchmarks for sound source separation tasks, such as separating drums, bass, and vocals from a single audio signal.
- The authors compare popular models for sound demixing, including their ensembles, on these new benchmarks.
- They provide a leaderboard at https://mvsep.com/quality_checker/ to compare the performance of various models.
- The authors also propose a novel approach for audio separation, based on ensembling different models that are best suited for particular audio stems.
- The proposed solution was evaluated in the context of the Music Demixing Challenge 2023 and achieved top results.
- The code and the approach are open-sourced on GitHub.
Plain English Explanation
Music demixing is the process of separating different musical tracks, such as drums, bass, and vocals, from a single audio recording. This can be useful for a variety of applications, including entertainment and hearing aids.
The paper introduces two new datasets that can be used to benchmark the performance of different models for sound source separation. The authors then compare the performance of popular models, including their ensembles, on these new benchmarks. They provide a leaderboard where you can see how different models perform.
The authors also propose a new approach for audio separation, which involves combining multiple models that are each specialized for a particular type of audio stem (e.g., drums, bass, vocals). This ensemble approach was evaluated in the Music Demixing Challenge 2023 and achieved top results.
The code and the approach developed by the authors are available on GitHub, so other researchers and developers can use and build upon their work.
Technical Explanation
The paper introduces two new benchmarks for the sound source separation task: https://aimodels.fyi/papers/arxiv/sound-demixing-challenge-2023-dollarunicodex2013dollar-music-demixing and https://aimodels.fyi/papers/arxiv/sound-demixing-challenge-2023-dollarunicodex2013dollar-cinematic-demixing. These benchmarks provide a standardized way to evaluate the performance of sound demixing models.
The authors then compare the performance of popular models for sound demixing, such as https://aimodels.fyi/papers/arxiv/toward-deep-drum-source-separation, https://aimodels.fyi/papers/arxiv/weakly-supervised-audio-separation-via-bi-modal, and https://aimodels.fyi/papers/arxiv/music-consistency-models, as well as their ensembles. They provide a leaderboard at https://mvsep.com/quality_checker/ to showcase the performance of these models.
The key innovation in this paper is the authors' proposed approach for audio separation, which involves ensembling different models that are best suited for particular audio stems (e.g., drums, bass, vocals). This ensemble approach was evaluated in the context of the Music Demixing Challenge 2023 and achieved top results in different tracks of the challenge.
Critical Analysis
The paper provides a comprehensive evaluation of various models for sound source separation and introduces two new benchmarks for this task. The use of ensembles to combine the strengths of different models is an interesting approach, and the authors' results in the Music Demixing Challenge 2023 demonstrate the effectiveness of this approach.
However, the paper does not provide much detail on the specific models and architectures used, nor does it delve into the limitations of the proposed approach. It would be helpful to have more information on the trade-offs and potential drawbacks of the ensemble method, as well as any areas for further research or improvement.
Additionally, the paper does not discuss the potential real-world applications and implications of this research, beyond the general mention of entertainment and hearing aids. It would be valuable to explore the broader impact and use cases of sound demixing technology.
Conclusion
This paper makes a significant contribution to the field of sound source separation by introducing two new benchmarks and proposing a novel ensemble-based approach for audio demixing. The authors' work has demonstrated the potential of this technology to improve various applications, and the open-sourcing of their code and methods will likely spur further advancements in this area.
Overall, the paper provides a solid foundation for future research and development in the field of music and audio separation, with the potential to unlock new possibilities in entertainment, accessibility, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Benchmarks and leaderboards for sound demixing tasks
Roman Solovyev, Alexander Stempkovskiy, Tatiana Habruseva
Music demixing is the task of separating different tracks from the given single audio signal into components, such as drums, bass, and vocals from the rest of the accompaniment. Separation of sources is useful for a range of areas, including entertainment and hearing aids. In this paper, we introduce two new benchmarks for the sound source separation tasks and compare popular models for sound demixing, as well as their ensembles, on these benchmarks. For the models' assessments, we provide the leaderboard at https://mvsep.com/quality_checker/, giving a comparison for a range of models. The new benchmark datasets are available for download. We also develop a novel approach for audio separation, based on the ensembling of different models that are suited best for the particular stem. The proposed solution was evaluated in the context of the Music Demixing Challenge 2023 and achieved top results in different tracks of the challenge. The code and the approach are open-sourced on GitHub.
Read more5/8/2024

0
Improving Real-Time Music Accompaniment Separation with MMDenseNet
Chun-Hsiang Wang, Chung-Che Wang, Jun-You Wang, Jyh-Shing Roger Jang, Yen-Hsun Chu
Music source separation aims to separate polyphonic music into different types of sources. Most existing methods focus on enhancing the quality of separated results by using a larger model structure, rendering them unsuitable for deployment on edge devices. Moreover, these methods may produce low-quality output when the input duration is short, making them impractical for real-time applications. Therefore, the goal of this paper is to enhance a lightweight model, MMDenstNet, to strike a balance between separation quality and latency for real-time applications. Different directions of improvement are explored or proposed in this paper, including complex ideal ratio mask, self-attention, band-merge-split method, and feature look back. Source-to-distortion ratio, real-time factor, and optimal latency are employed to evaluate the performance. To align with our application requirements, the evaluation process in this paper focuses on the separation performance of the accompaniment part. Experimental results demonstrate that our improvement achieves low real-time factor and optimal latency while maintaining acceptable separation quality.
Read more7/2/2024
🛠️
0
The Sound Demixing Challenge 2023 $unicode{x2013}$ Music Demixing Track
Giorgio Fabbro, Stefan Uhlich, Chieh-Hsin Lai, Woosung Choi, Marco Mart'inez-Ram'irez, Weihsiang Liao, Igor Gadelha, Geraldo Ramos, Eddie Hsu, Hugo Rodrigues, Fabian-Robert Stoter, Alexandre D'efossez, Yi Luo, Jianwei Yu, Dipam Chakraborty, Sharada Mohanty, Roman Solovyev, Alexander Stempkovskiy, Tatiana Habruseva, Nabarun Goswami, Tatsuya Harada, Minseok Kim, Jun Hyung Lee, Yuanliang Dong, Xinran Zhang, Jiafeng Liu, Yuki Mitsufuji
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers and musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
Read more4/22/2024
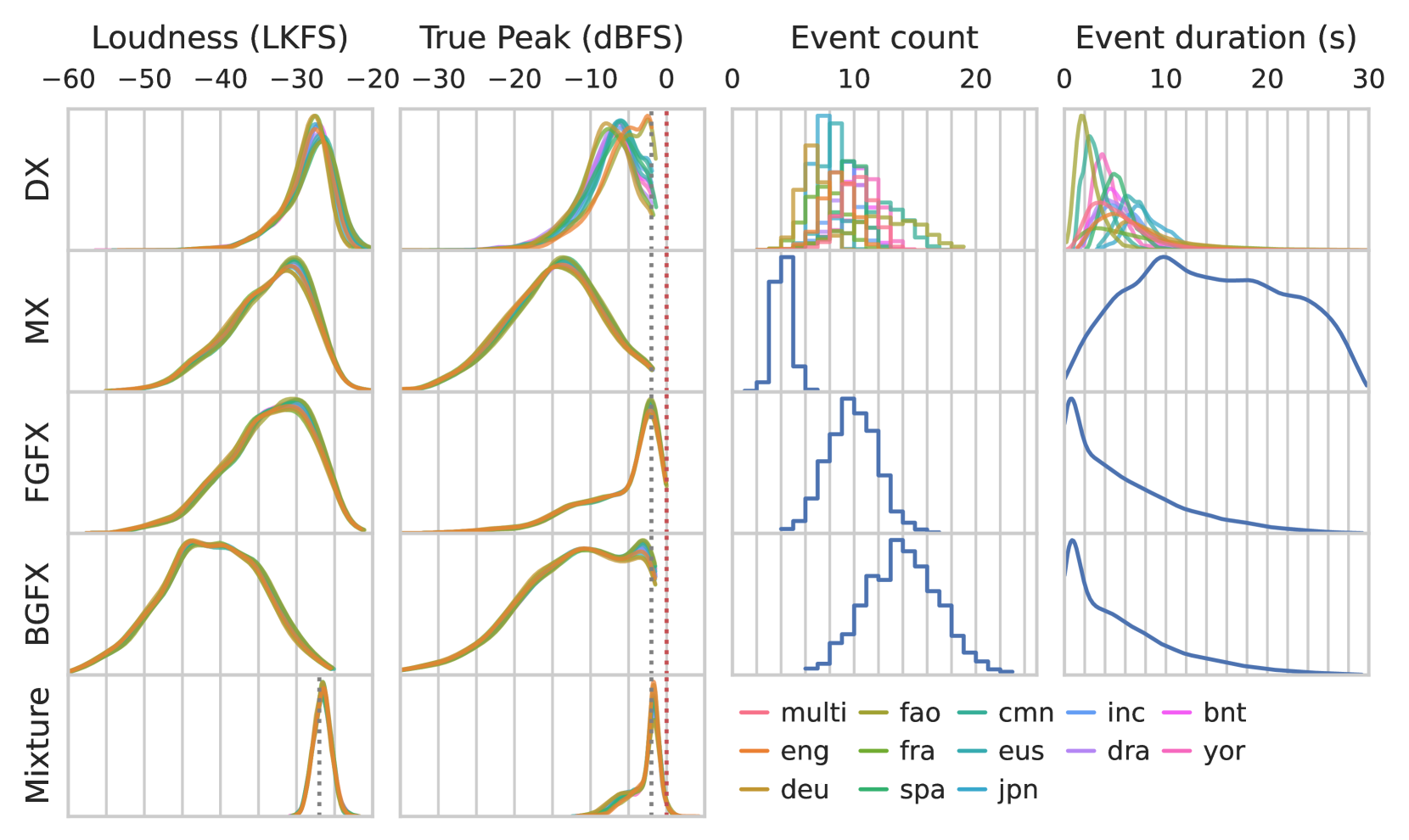
0
Remastering Divide and Remaster: A Cinematic Audio Source Separation Dataset with Multilingual Support
Karn N. Watcharasupat, Chih-Wei Wu, Iroro Orife
Cinematic audio source separation (CASS), as a problem of extracting the dialogue, music, and effects stems from their mixture, is a relatively new subtask of audio source separation. To date, only one publicly available dataset exists for CASS, that is, the Divide and Remaster (DnR) dataset, which is currently at version 2. While DnR v2 has been an incredibly useful resource for CASS, several areas of improvement have been identified, particularly through its use in the 2023 Sound Demixing Challenge. In this work, we develop version 3 of the DnR dataset, addressing issues relating to vocal content in non-dialogue stems, loudness distributions, mastering process, and linguistic diversity. In particular, the dialogue stem of DnR v3 includes speech content from more than 30 languages from multiple families including but not limited to the Germanic, Romance, Indo-Aryan, Dravidian, Malayo-Polynesian, and Bantu families. Benchmark results using the Bandit model indicated that training on multilingual data yields significant generalizability to the model even in languages with low data availability. Even in languages with high data availability, the multilingual model often performs on par or better than dedicated models trained on monolingual CASS datasets. Dataset and model implementation will be made available at https://github.com/kwatcharasupat/source-separation-landing.
Read more8/27/2024