Facing the Music: Tackling Singing Voice Separation in Cinematic Audio Source Separation

0

Sign in to get full access
Overview
- This paper addresses the challenge of separating singing voices from complex cinematic audio scenes.
- The researchers developed a novel neural network architecture and training approach to tackle this task.
- They evaluated their system on a new dataset of cinematic audio, demonstrating significant improvements over existing methods.
Plain English Explanation
The paper focuses on the problem of [object Object] in complex audio scenes, such as those found in movies or TV shows. Separating the singing voice from the background music, sound effects, and other elements in these types of audio can be very challenging, but is an important task for [object Object] applications.
The researchers developed a new [object Object] and training approach to tackle this problem. Their system is designed to work well on the unique characteristics of cinematic audio, which can be more complex and diverse than typical music recordings.
To evaluate their method, the researchers created a new dataset of cinematic audio clips, which they used to [object Object] their approach against existing singing voice separation techniques. Their results show significant improvements over the state-of-the-art, demonstrating the effectiveness of their novel architecture and training strategy.
Technical Explanation
The core of the researchers' approach is a [object Object] that takes a mixed audio signal as input and outputs separated tracks for the singing voice and the background. The network architecture is designed to effectively model the complex spectrotemporal patterns of singing voices in the presence of other audio elements.
The training process involves a combination of [object Object] and [object Object] learning techniques to capture both the general characteristics of singing voices and the unique properties of cinematic audio. This allows the system to generalize well to a wide range of real-world scenarios.
The researchers evaluated their method on a new dataset of cinematic audio clips, which includes a diverse range of genres, production styles, and audio characteristics. Their experiments demonstrate significant improvements in singing voice separation performance compared to existing state-of-the-art approaches, particularly in challenging scenarios with complex background audio.
Critical Analysis
The paper presents a well-designed and thorough study, addressing an important problem in the field of audio source separation. The researchers' novel neural network architecture and training approach show promising results, and the creation of a new cinematic audio dataset is a valuable contribution to the research community.
However, the paper does not address some potential limitations of the proposed system. For example, it's not clear how the method would perform on low-quality or noisy audio recordings, or how it would handle edge cases such as multiple singing voices or highly overlapping audio elements. Additionally, the researchers could have discussed potential real-world applications and deployment challenges in more detail.
Further research could explore ways to make the system more robust and adaptable, such as by incorporating [object Object] techniques or leveraging additional contextual information. Investigating the interpretability and explainability of the neural network's internal representations could also be a fruitful area of inquiry.
Conclusion
This paper presents a significant advancement in the field of singing voice separation, with a novel neural network architecture and training approach that achieves state-of-the-art performance on a new dataset of cinematic audio. The researchers' work demonstrates the potential for deep learning techniques to tackle complex audio source separation challenges, and their findings could have important implications for a wide range of audio-related applications, from music production to film and television post-processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Facing the Music: Tackling Singing Voice Separation in Cinematic Audio Source Separation
Karn N. Watcharasupat, Chih-Wei Wu, Iroro Orife
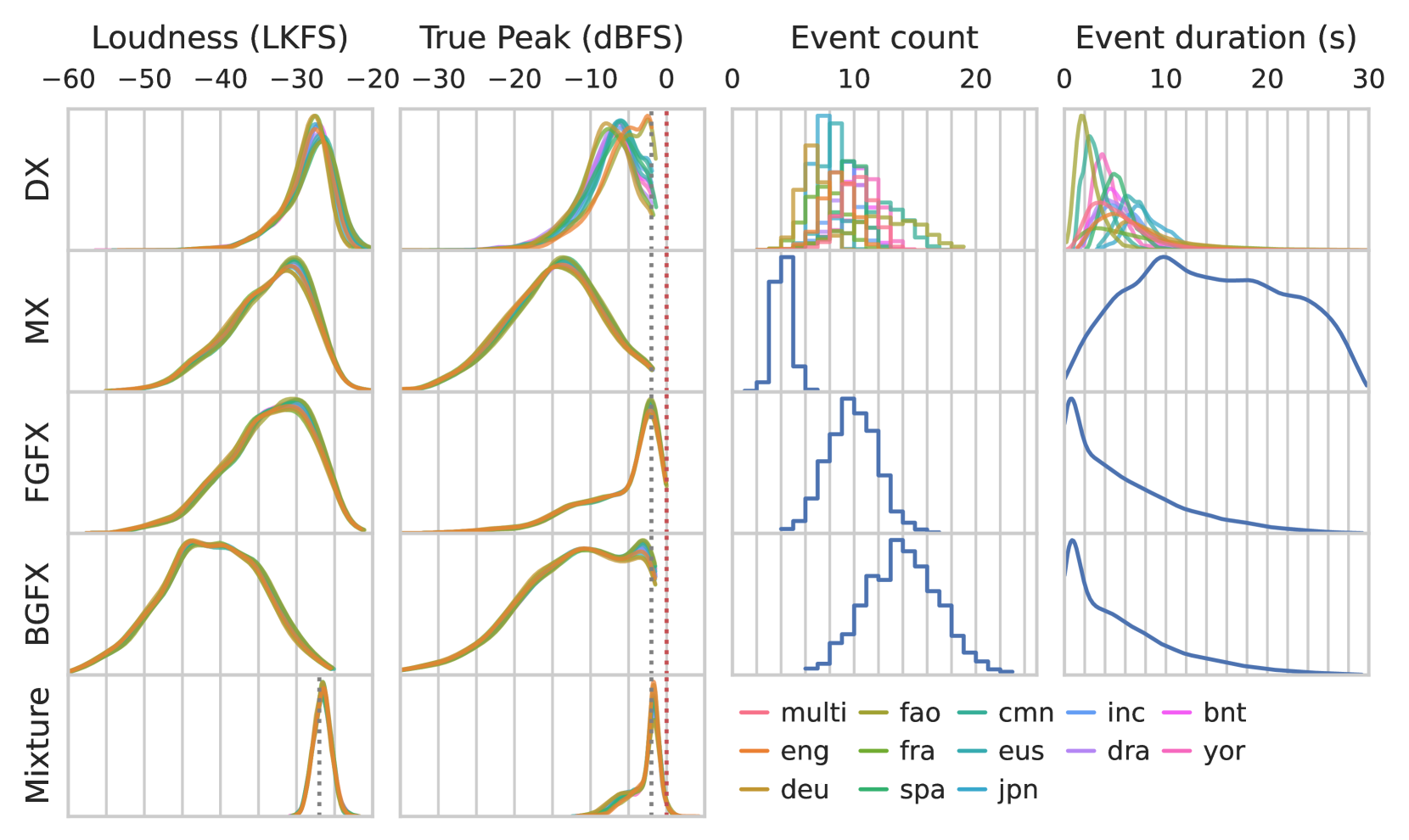
Cinematic audio source separation (CASS), as a standalone problem of extracting individual stems from their mixture, is a fairly new subtask of audio source separation. A typical setup of CASS is a three-stem problem, with the aim of separating the mixture into the dialogue (DX), music (MX), and effects (FX) stems. Given the creative nature of cinematic sound production, however, several edge cases exist; some sound sources do not fit neatly in any of these three stems, necessitating the use of additional auxiliary stems in production. One very common edge case is the singing voice in film audio, which may belong in either the DX or MX or neither, depending heavily on the cinematic context. In this work, we demonstrate a very straightforward extension of the dedicated-decoder Bandit and query-based single-decoder Banquet models to a four-stem problem, treating non-musical dialogue, instrumental music, singing voice, and effects as separate stems. Interestingly, the query-based Banquet model outperformed the dedicated-decoder Bandit model. We hypothesized that this is due to a better feature alignment at the bottleneck as enforced by the band-agnostic FiLM layer. Dataset and model implementation will be made available at https://github.com/kwatcharasupat/source-separation-landing.
Read more8/27/2024
0
Remastering Divide and Remaster: A Cinematic Audio Source Separation Dataset with Multilingual Support
Karn N. Watcharasupat, Chih-Wei Wu, Iroro Orife
Cinematic audio source separation (CASS), as a problem of extracting the dialogue, music, and effects stems from their mixture, is a relatively new subtask of audio source separation. To date, only one publicly available dataset exists for CASS, that is, the Divide and Remaster (DnR) dataset, which is currently at version 2. While DnR v2 has been an incredibly useful resource for CASS, several areas of improvement have been identified, particularly through its use in the 2023 Sound Demixing Challenge. In this work, we develop version 3 of the DnR dataset, addressing issues relating to vocal content in non-dialogue stems, loudness distributions, mastering process, and linguistic diversity. In particular, the dialogue stem of DnR v3 includes speech content from more than 30 languages from multiple families including but not limited to the Germanic, Romance, Indo-Aryan, Dravidian, Malayo-Polynesian, and Bantu families. Benchmark results using the Bandit model indicated that training on multilingual data yields significant generalizability to the model even in languages with low data availability. Even in languages with high data availability, the multilingual model often performs on par or better than dedicated models trained on monolingual CASS datasets. Dataset and model implementation will be made available at https://github.com/kwatcharasupat/source-separation-landing.
Read more8/27/2024

0
A Stem-Agnostic Single-Decoder System for Music Source Separation Beyond Four Stems
Karn N. Watcharasupat, Alexander Lerch
Despite significant recent progress across multiple subtasks of audio source separation, few music source separation systems support separation beyond the four-stem vocals, drums, bass, and other (VDBO) setup. Of the very few current systems that support source separation beyond this setup, most continue to rely on an inflexible decoder setup that can only support a fixed pre-defined set of stems. Increasing stem support in these inflexible systems correspondingly requires increasing computational complexity, rendering extensions of these systems computationally infeasible for long-tail instruments. In this work, we propose Banquet, a system that allows source separation of multiple stems using just one decoder. A bandsplit source separation model is extended to work in a query-based setup in tandem with a music instrument recognition PaSST model. On the MoisesDB dataset, Banquet, at only 24.9 M trainable parameters, approached the performance level of the significantly more complex 6-stem Hybrid Transformer Demucs on VDBO stems and outperformed it on guitar and piano. The query-based setup allows for the separation of narrow instrument classes such as clean acoustic guitars, and can be successfully applied to the extraction of less common stems such as reeds and organs. Implementation is available at https://github.com/kwatcharasupat/query-bandit.
Read more8/27/2024
🛸
0
Singer separation for karaoke content generation
Hsuan-Yu Lin, Xuanjun Chen, Jyh-Shing Roger Jang
Due to the rapid development of deep learning, we can now successfully separate singing voice from mono audio music. However, this separation can only extract human voices from other musical instruments, which is undesirable for karaoke content generation applications that only require the separation of lead singers. For this karaoke application, we need to separate the music containing male and female duets into two vocals, or extract a single lead vocal from the music containing vocal harmony. For this reason, we propose in this article to use a singer separation system, which generates karaoke content for one or two separated lead singers. In particular, we introduced three models for the singer separation task and designed an automatic model selection scheme to distinguish how many lead singers are in the song. We also collected a large enough data set, MIR-SingerSeparation, which has been publicly released to advance the frontier of this research. Our singer separation is most suitable for sentimental ballads and can be directly applied to karaoke content generation. As far as we know, this is the first singer-separation work for real-world karaoke applications.
Read more8/20/2024