Remembering Everything Makes You Vulnerable: A Limelight on Machine Unlearning for Personalized Healthcare Sector

0

Sign in to get full access
Overview
- This paper explores the concept of "machine unlearning" in the context of personalized healthcare applications.
- Machine unlearning is the process of selectively removing or forgetting specific pieces of information from a trained machine learning model.
- The researchers investigate the implications of machine unlearning for improving data privacy and security in personalized healthcare systems.
Plain English Explanation
The paper discusses the idea of "machine unlearning," which is the ability to selectively remove or forget certain information from a trained machine learning model. This is particularly relevant for personalized healthcare applications, where patient data needs to be protected and secured.
Imagine you have a machine learning model that's been trained on a large dataset of medical records. This model could be used to provide personalized healthcare recommendations. However, if a patient decides they no longer want their data to be part of the model, the researchers suggest that the model should be able to "unlearn" that specific information.
By allowing the model to forget certain data, it can help improve data privacy and security in personalized healthcare systems. The researchers explore the technical details and challenges of implementing this machine unlearning capability.
Technical Explanation
The paper presents a framework for enabling machine unlearning in personalized healthcare applications. The key components include:
-
Selective Unlearning: The ability to identify and remove specific data points or features from a trained model, without affecting its overall performance on the remaining data.
-
Efficient Unlearning: Techniques to update the model parameters in a computationally efficient manner, rather than retraining the entire model from scratch.
-
Provable Unlearning Guarantees: Formal theoretical analysis to ensure that the unlearned model behaves indistinguishably from a model that was never trained on the removed data.
The researchers evaluate their proposed machine unlearning framework on several personalized healthcare tasks, such as predicting disease risk and optimizing treatment recommendations. The results demonstrate the effectiveness of their approach in selectively forgetting sensitive patient data while maintaining the model's predictive performance.
Critical Analysis
The paper raises important considerations around data privacy and security in personalized healthcare systems. By enabling machine unlearning, the researchers aim to give patients more control over their personal data and the ability to request the removal of specific information from the models used to provide them with healthcare recommendations.
However, the paper also acknowledges some potential limitations and areas for further research. For example, the unlearning process may not always be perfect, and there could be residual information retained in the model that could potentially be recovered through advanced techniques.
Additionally, the researchers note that the computational efficiency of the unlearning process is an important consideration, as frequent or large-scale unlearning operations could have a significant impact on the system's overall performance.
Overall, the paper presents a promising approach to addressing data privacy and security concerns in personalized healthcare, but further exploration of the real-world implications and practical implementation challenges would be valuable.
Conclusion
This paper highlights the importance of machine unlearning for improving data privacy and security in personalized healthcare applications. By allowing models to selectively forget specific pieces of information, the researchers aim to empower patients and increase trust in these systems.
The proposed framework demonstrates the technical feasibility of implementing machine unlearning, but there are still important considerations around the completeness of the unlearning process and the impact on system performance. Continued research in this area could lead to more robust and trustworthy personalized healthcare solutions that prioritize patient privacy and control over their data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Remembering Everything Makes You Vulnerable: A Limelight on Machine Unlearning for Personalized Healthcare Sector
Ahan Chatterjee, Sai Anirudh Aryasomayajula, Rajat Chaudhari, Subhajit Paul, Vishwa Mohan Singh
As the prevalence of data-driven technologies in healthcare continues to rise, concerns regarding data privacy and security become increasingly paramount. This thesis aims to address the vulnerability of personalized healthcare models, particularly in the context of ECG monitoring, to adversarial attacks that compromise patient privacy. We propose an approach termed Machine Unlearning to mitigate the impact of exposed data points on machine learning models, thereby enhancing model robustness against adversarial attacks while preserving individual privacy. Specifically, we investigate the efficacy of Machine Unlearning in the context of personalized ECG monitoring, utilizing a dataset of clinical ECG recordings. Our methodology involves training a deep neural classifier on ECG data and fine-tuning the model for individual patients. We demonstrate the susceptibility of fine-tuned models to adversarial attacks, such as the Fast Gradient Sign Method (FGSM), which can exploit additional data points in personalized models. To address this vulnerability, we propose a Machine Unlearning algorithm that selectively removes sensitive data points from fine-tuned models, effectively enhancing model resilience against adversarial manipulation. Experimental results demonstrate the effectiveness of our approach in mitigating the impact of adversarial attacks while maintaining the pre-trained model accuracy.
Read more7/8/2024

0
Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
Keltin Grimes, Collin Abidi, Cole Frank, Shannon Gallagher
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
Read more5/30/2024
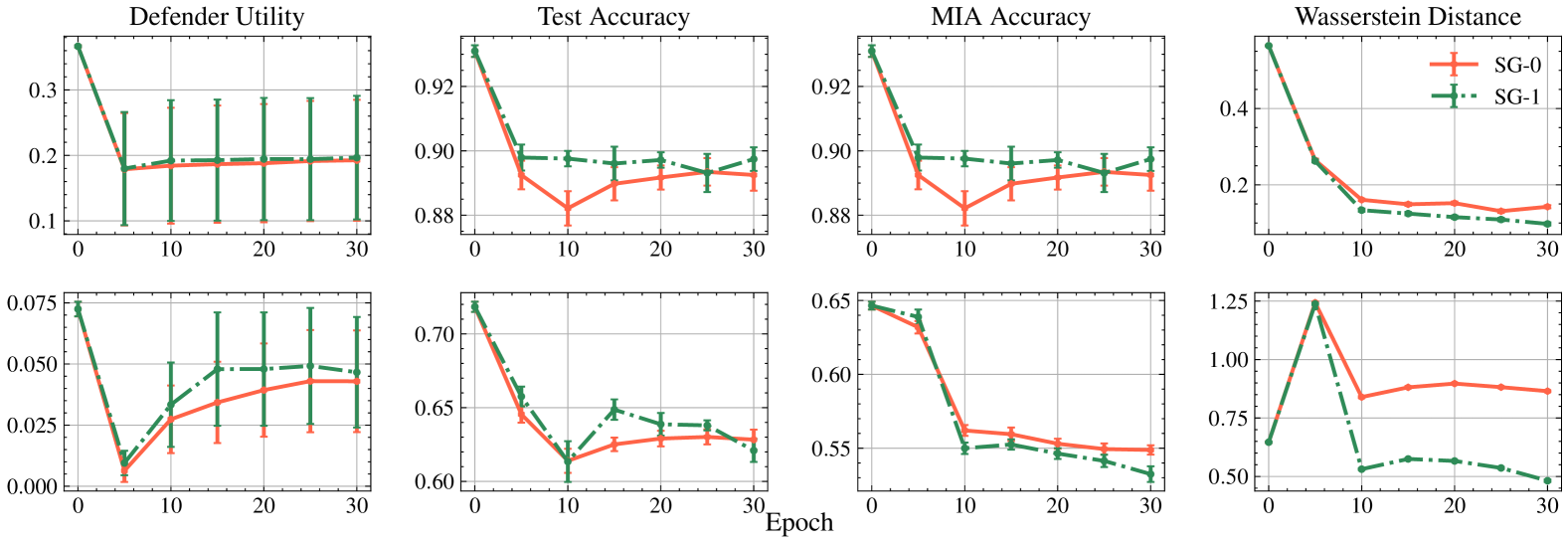
0
Adversarial Machine Unlearning
Zonglin Di, Sixie Yu, Yevgeniy Vorobeychik, Yang Liu
This paper focuses on the challenge of machine unlearning, aiming to remove the influence of specific training data on machine learning models. Traditionally, the development of unlearning algorithms runs parallel with that of membership inference attacks (MIA), a type of privacy threat to determine whether a data instance was used for training. However, the two strands are intimately connected: one can view machine unlearning through the lens of MIA success with respect to removed data. Recognizing this connection, we propose a game-theoretic framework that integrates MIAs into the design of unlearning algorithms. Specifically, we model the unlearning problem as a Stackelberg game in which an unlearner strives to unlearn specific training data from a model, while an auditor employs MIAs to detect the traces of the ostensibly removed data. Adopting this adversarial perspective allows the utilization of new attack advancements, facilitating the design of unlearning algorithms. Our framework stands out in two ways. First, it takes an adversarial approach and proactively incorporates the attacks into the design of unlearning algorithms. Secondly, it uses implicit differentiation to obtain the gradients that limit the attacker's success, thus benefiting the process of unlearning. We present empirical results to demonstrate the effectiveness of the proposed approach for machine unlearning.
Read more6/13/2024

0
Jogging the Memory of Unlearned Model Through Targeted Relearning Attack
Shengyuan Hu, Yiwei Fu, Zhiwei Steven Wu, Virginia Smith
Machine unlearning is a promising approach to mitigate undesirable memorization of training data in ML models. However, in this work we show that existing approaches for unlearning in LLMs are surprisingly susceptible to a simple set of targeted relearning attacks. With access to only a small and potentially loosely related set of data, we find that we can 'jog' the memory of unlearned models to reverse the effects of unlearning. We formalize this unlearning-relearning pipeline, explore the attack across three popular unlearning benchmarks, and discuss future directions and guidelines that result from our study.
Read more6/21/2024