Rephrase, Augment, Reason: Visual Grounding of Questions for Vision-Language Models
2310.05861
0
0
🤖
Abstract
An increasing number of vision-language tasks can be handled with little to no training, i.e., in a zero and few-shot manner, by marrying large language models (LLMs) to vision encoders, resulting in large vision-language models (LVLMs). While this has huge upsides, such as not requiring training data or custom architectures, how an input is presented to an LVLM can have a major impact on zero-shot model performance. In particular, inputs phrased in an underspecified way can result in incorrect answers due to factors like missing visual information, complex implicit reasoning, or linguistic ambiguity. Therefore, adding visually-grounded information to the input as a preemptive clarification should improve model performance by reducing underspecification, e.g., by localizing objects and disambiguating references. Similarly, in the VQA setting, changing the way questions are framed can make them easier for models to answer. To this end, we present Rephrase, Augment and Reason (RepARe), a gradient-free framework that extracts salient details about the image using the underlying LVLM as a captioner and reasoner, in order to propose modifications to the original question. We then use the LVLM's confidence over a generated answer as an unsupervised scoring function to select the rephrased question most likely to improve zero-shot performance. Focusing on three visual question answering tasks, we show that RepARe can result in a 3.85% (absolute) increase in zero-shot accuracy on VQAv2, 6.41%, and 7.94% points increase on A-OKVQA, and VizWiz respectively. Additionally, we find that using gold answers for oracle question candidate selection achieves a substantial gain in VQA accuracy by up to 14.41%. Through extensive analysis, we demonstrate that outputs from RepARe increase syntactic complexity, and effectively utilize vision-language interaction and the frozen LLM.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers are developing large vision-language models (LVLMs) that can handle various vision-language tasks with little to no training.
- However, how the input is presented to the LVLM can significantly impact its zero-shot performance.
- Underspecified inputs can lead to incorrect answers due to missing visual information, complex reasoning, or linguistic ambiguity.
- Adding visually-grounded information and rephrasing questions can improve model performance by reducing underspecification.
Plain English Explanation
These new large vision-language models are quite impressive. They can tackle all sorts of tasks related to understanding both images and language, without needing to be trained on tons of data. That's a big deal, as it means these models can be more flexible and applicable to a wider range of scenarios.
However, the way you present information to these models can make a big difference in how well they perform. If the input is a bit vague or lacking key details, the model may struggle to come up with the right answer. For example, if you ask a question about an image but don't point out what specific parts of the image you're referring to, the model might get confused and give you the wrong response.
The researchers realized that by adding more visual context or rephrasing the questions in a clearer way, they could help these models perform much better, even without any additional training. It's kind of like when you're explaining something to a person - if you use more specific language and provide relevant details, they're much more likely to understand you correctly.
So the researchers developed a system called RepARe that looks at the original input, uses the LVLM's own language generation abilities to extract relevant details, and then proposes modified versions of the input that should be easier for the model to work with. This allows the model to perform significantly better on various visual question answering tasks, without needing any changes to the model itself.
Technical Explanation
The key innovation presented in this paper is the RepARe framework, which aims to improve the zero-shot performance of large vision-language models (LVLMs) on visual question answering tasks.
The core idea is that the way an input is presented to an LVLM can have a major impact on its ability to provide the correct answer, even without any additional training. Underspecified or ambiguous inputs can lead the model astray, causing it to produce incorrect responses due to missing visual information, complex implicit reasoning, or linguistic ambiguity.
To address this, RepARe extracts salient details about the image using the LVLM's own captioning and reasoning abilities. It then proposes modified versions of the original question, rephrasing and augmenting it with this additional visually-grounded information. The framework uses the LVLM's own confidence in its generated answer as an unsupervised scoring function to select the question most likely to improve zero-shot performance.
The researchers evaluate RepARe on three visual question answering datasets: VQAv2, A-OKVQA, and VizWiz. They show that RepARe can lead to substantial gains in zero-shot accuracy, with improvements of 3.85%, 6.41%, and 7.94% on the respective datasets. Furthermore, using gold standard answers for oracle question candidate selection achieves even greater gains, up to 14.41%.
Through analysis, the authors demonstrate that the rephrased questions generated by RepARe increase syntactic complexity and effectively leverage the LVLM's vision-language interaction and frozen language model capabilities.
Critical Analysis
The research presented in this paper highlights an important and overlooked challenge in the use of large vision-language models: the sensitivity of their performance to the way inputs are framed. The authors rightly point out that underspecified or ambiguous inputs can lead to incorrect answers, even for these powerful models.
The RepARe framework is a clever solution to this problem, leveraging the LVLM's own captioning and reasoning abilities to augment and rephrase the input in a way that improves zero-shot performance. The substantial gains demonstrated across multiple datasets are a strong testament to the effectiveness of this approach.
That said, the paper does not explore the limits or potential downsides of this technique. For instance, it's unclear how well RepARe would scale to more complex or open-ended vision-language tasks, where the space of possible question reformulations could become unwieldy. There are also potential concerns around the reliability and bias of the LVLM's own captioning and reasoning, which could be propagated through the RepARe process.
Additionally, the paper focuses solely on improving zero-shot performance, without considering the potential impact on few-shot or fully supervised learning scenarios. It would be valuable to understand how RepARe might interact with or complement other fine-tuning or data augmentation techniques.
Overall, this research represents an important step forward in making large vision-language models more robust and useful in real-world applications. However, further exploration of the limitations and broader implications of this approach would be a valuable area for future work.
Conclusion
The key takeaway from this paper is that the way inputs are presented to large vision-language models can have a significant impact on their zero-shot performance, even for these powerful AI systems. The RepARe framework provides a compelling solution to this challenge, leveraging the models' own captioning and reasoning abilities to rephrase and augment underspecified inputs in a way that substantially boosts accuracy on visual question answering tasks.
This research highlights the importance of carefully designing how users interact with these large, pre-trained models, as even small changes in how information is conveyed can lead to vastly different outcomes. As vision-language models continue to advance, developing techniques like RepARe will be crucial for unlocking their full potential and ensuring they can be reliably deployed in real-world applications.
Related Papers
💬
Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves
Yihe Deng, Weitong Zhang, Zixiang Chen, Quanquan Gu
0
0
Misunderstandings arise not only in interpersonal communication but also between humans and Large Language Models (LLMs). Such discrepancies can make LLMs interpret seemingly unambiguous questions in unexpected ways, yielding incorrect responses. While it is widely acknowledged that the quality of a prompt, such as a question, significantly impacts the quality of the response provided by LLMs, a systematic method for crafting questions that LLMs can better comprehend is still underdeveloped. In this paper, we present a method named `Rephrase and Respond' (RaR), which allows LLMs to rephrase and expand questions posed by humans and provide responses in a single prompt. This approach serves as a simple yet effective prompting method for improving performance. We also introduce a two-step variant of RaR, where a rephrasing LLM first rephrases the question and then passes the original and rephrased questions together to a different responding LLM. This facilitates the effective utilization of rephrased questions generated by one LLM with another. Our experiments demonstrate that our methods significantly improve the performance of different models across a wide range to tasks. We further provide a comprehensive comparison between RaR and the popular Chain-of-Thought (CoT) methods, both theoretically and empirically. We show that RaR is complementary to CoT and can be combined with CoT to achieve even better performance. Our work not only contributes to enhancing LLM performance efficiently and effectively but also sheds light on a fair evaluation of LLM capabilities. Data and codes are available at https://github.com/uclaml/Rephrase-and-Respond.
4/22/2024

Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts
Ovgu Ozdemir, Erdem Akagunduz
0
0
Visual question answering (VQA) is known as an AI-complete task as it requires understanding, reasoning, and inferring about the vision and the language content. Over the past few years, numerous neural architectures have been suggested for the VQA problem. However, achieving success in zero-shot VQA remains a challenge due to its requirement for advanced generalization and reasoning skills. This study explores the impact of incorporating image captioning as an intermediary process within the VQA pipeline. Specifically, we explore the efficacy of utilizing image captions instead of images and leveraging large language models (LLMs) to establish a zero-shot setting. Since image captioning is the most crucial step in this process, we compare the impact of state-of-the-art image captioning models on VQA performance across various question types in terms of structure and semantics. We propose a straightforward and efficient question-driven image captioning approach within this pipeline to transfer contextual information into the question-answering (QA) model. This method involves extracting keywords from the question, generating a caption for each image-question pair using the keywords, and incorporating the question-driven caption into the LLM prompt. We evaluate the efficacy of using general-purpose and question-driven image captions in the VQA pipeline. Our study highlights the potential of employing image captions and harnessing the capabilities of LLMs to achieve competitive performance on GQA under the zero-shot setting. Our code is available at url{https://github.com/ovguyo/captions-in-VQA}.
4/15/2024
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
0
0
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
4/17/2024
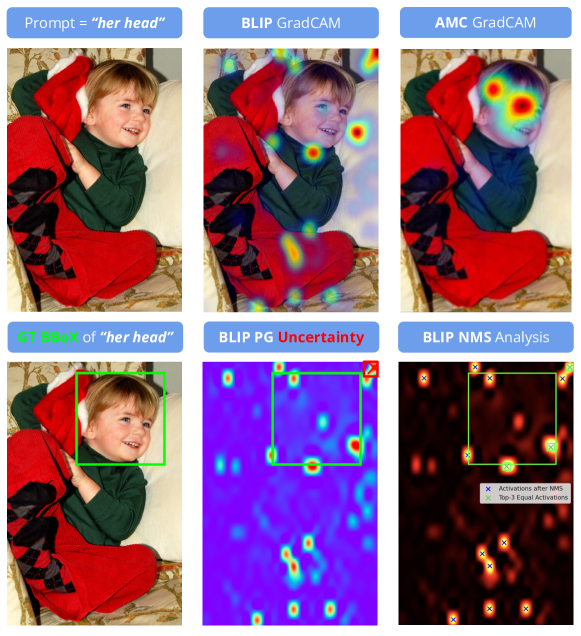
Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM
Navid Rajabi, Jana Kosecka
0
0
Vision and Language Models (VLMs) continue to demonstrate remarkable zero-shot (ZS) performance across various tasks. However, many probing studies have revealed that even the best-performing VLMs struggle to capture aspects of compositional scene understanding, lacking the ability to properly ground and localize linguistic phrases in images. Recent VLM advancements include scaling up both model and dataset sizes, additional training objectives and levels of supervision, and variations in the model architectures. To characterize the grounding ability of VLMs, such as phrase grounding, referring expressions comprehension, and relationship understanding, Pointing Game has been used as an evaluation metric for datasets with bounding box annotations. In this paper, we introduce a novel suite of quantitative metrics that utilize GradCAM activations to rigorously evaluate the grounding capabilities of pre-trained VLMs like CLIP, BLIP, and ALBEF. These metrics offer an explainable and quantifiable approach for a more detailed comparison of the zero-shot capabilities of VLMs and enable measuring models' grounding uncertainty. This characterization reveals interesting tradeoffs between the size of the model, the dataset size, and their performance.
5/1/2024