Reproducibility in Machine Learning-based Research: Overview, Barriers and Drivers

0
Sign in to get full access
Overview
- This paper provides an overview of the challenges and drivers of reproducibility in machine learning-based research.
- It discusses the definition of reproducibility and its importance in the field of machine learning.
- The paper identifies key barriers to reproducibility, such as data and code availability, and explores potential solutions to address these challenges.
- It also examines the role of various stakeholders, including researchers, publishers, and funding agencies, in promoting reproducible research practices.
Plain English Explanation
Reproducibility is a crucial aspect of scientific research, as it allows other scientists to verify and build upon the findings of previous studies. However, in the field of machine learning, achieving reproducibility can be particularly challenging.
The paper Integrating Measures of Replicability into Scholarly Search Challenges explores the reasons why machine learning research can be difficult to reproduce. One key issue is the complexity of the models and algorithms used, which can make it challenging to fully document all the details necessary for others to replicate the study. Additionally, the availability of data and code used in the research is often limited, making it hard for other researchers to verify the results.
To address these challenges, the paper Design Principles for Falsifiable, Replicable, Reproducible Empirical ML suggests that researchers should strive to make their work more transparent and accessible. This may involve providing detailed documentation of their methods, sharing their data and code, and following best practices for experimental design and reporting.
The paper also highlights the role of various stakeholders in promoting reproducible research. For example, Towards Enhancing Reproducibility in Deep Learning: Bugs, Empirical Studies suggests that funding agencies and publishers can play a crucial part by requiring researchers to demonstrate the reproducibility of their work as a condition of funding or publication.
By addressing the challenges of reproducibility in machine learning research, the scientific community can work to ensure that the findings in this field are robust, reliable, and can be built upon to advance our understanding of the world.
Technical Explanation
The paper [Reproducibility in Machine Learning-based Research: Overview, Barriers and Drivers] provides a comprehensive overview of the challenges and drivers of reproducibility in the field of machine learning-based research.
The authors begin by defining the concept of reproducibility, highlighting its importance in the scientific process and the specific challenges it poses in the context of machine learning. They note that reproducibility is crucial for verifying research findings, building upon previous work, and ensuring the reliability of machine learning systems in real-world applications.
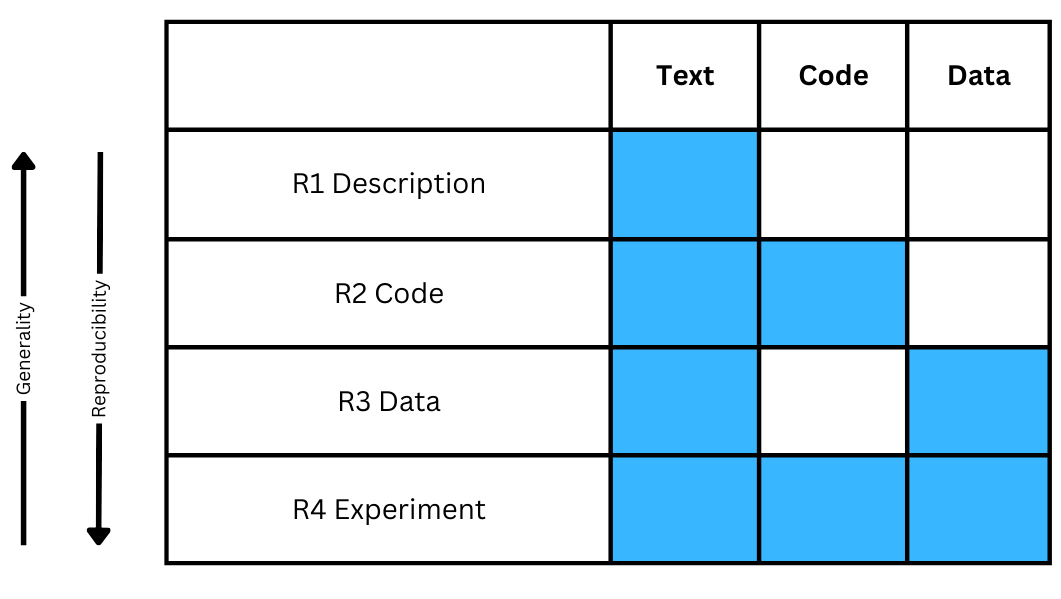
The paper then delves into the key barriers to reproducibility in machine learning research. One significant challenge is the availability and accessibility of the data and code used in the studies. The authors note that many researchers do not share their data and code, making it difficult for others to replicate the experiments and validate the results. Additionally, the complexity of machine learning models and the large number of hyperparameters involved can make it challenging to fully document and reproduce the experimental setup.
The paper also explores potential solutions and drivers for promoting reproducible research practices. It discusses the role of various stakeholders, such as researchers, publishers, and funding agencies, in addressing the reproducibility challenge. For example, the paper Can Citations Tell Us About Papers' Reproducibility? suggests that publishers can incentivize reproducible research by requiring authors to make their data and code publicly available as a condition of publication.
Furthermore, the paper From Model Performance to Claim: How Change highlights the importance of developing best practices for experimental design, data management, and result reporting in machine learning research. By adopting these practices, researchers can improve the transparency and replicability of their studies, ultimately contributing to the overall reliability and progress of the field.
Critical Analysis
The paper provides a comprehensive overview of the challenges and drivers of reproducibility in machine learning-based research, highlighting the critical importance of this issue for the field's advancement. The authors have done an excellent job of identifying the key barriers to reproducibility, such as data and code availability, model complexity, and the lack of standardized reporting practices.
However, the paper could have delved deeper into some of the specific solutions and best practices for addressing these challenges. While it touches on the role of various stakeholders, such as researchers, publishers, and funding agencies, the discussion could have been more detailed and actionable. Additionally, the paper could have explored the potential trade-offs and challenges associated with implementing these solutions, as well as any potential unintended consequences that may arise.
Furthermore, the paper does not address the potential cultural and incentive structures within the research community that may hinder the adoption of reproducible practices. Addressing these underlying issues may be crucial for driving sustainable change in the field.
Despite these minor limitations, the paper provides a valuable contribution to the ongoing discussion around reproducibility in machine learning research. By raising awareness of the challenges and highlighting potential solutions, the authors have set the stage for further research and the development of more robust and reliable machine learning systems.
Conclusion
This paper provides a comprehensive overview of the challenges and drivers of reproducibility in machine learning-based research. It highlights the critical importance of reproducibility for the field's advancement, as it allows for the verification and validation of research findings, enabling the scientific community to build upon previous work and develop more reliable machine learning systems.
The paper identifies key barriers to reproducibility, such as data and code availability, model complexity, and the lack of standardized reporting practices. It also explores potential solutions and the role of various stakeholders, including researchers, publishers, and funding agencies, in promoting reproducible research practices.
By addressing the challenges of reproducibility, the scientific community can work to ensure that the findings in machine learning research are robust, reliable, and can be built upon to advance our understanding of the world and drive innovation in various domains. The insights and recommendations provided in this paper can serve as a valuable guide for researchers, policymakers, and other stakeholders committed to enhancing the reproducibility and integrity of machine learning-based research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reproducibility in Machine Learning-based Research: Overview, Barriers and Drivers
Harald Semmelrock, Tony Ross-Hellauer, Simone Kopeinik, Dieter Theiler, Armin Haberl, Stefan Thalmann, Dominik Kowald
Research in various fields is currently experiencing challenges regarding the reproducibility of results. This problem is also prevalent in machine learning (ML) research. The issue arises primarily due to unpublished data and/or source code and the sensitivity of ML training conditions. Although different solutions have been proposed to address this issue, such as using ML platforms, the level of reproducibility in ML-driven research remains unsatisfactory. Therefore, in this article, we discuss the reproducibility of ML-driven research with three main aims: (i) identify the barriers to reproducibility when applying ML in research as well as categorize the barriers to different types of reproducibility (description, code, data, and experiment reproducibility), (ii) identify potential drivers such as tools, practices, and interventions that support ML reproducibility as well as distinguish between technology-driven drivers, procedural drivers, and drivers related to awareness and education, and (iii) map the drivers to the barriers. With this work, we hope to provide insights and contribute to the decision-making process regarding the adoption of different solutions to support ML reproducibility.
Read more6/21/2024
0
What is Reproducibility in Artificial Intelligence and Machine Learning Research?
Abhyuday Desai, Mohamed Abdelhamid, Nakul R. Padalkar
In the rapidly evolving fields of Artificial Intelligence (AI) and Machine Learning (ML), the reproducibility crisis underscores the urgent need for clear validation methodologies to maintain scientific integrity and encourage advancement. The crisis is compounded by the prevalent confusion over validation terminology. Responding to this challenge, we introduce a validation framework that clarifies the roles and definitions of key validation efforts: repeatability, dependent and independent reproducibility, and direct and conceptual replicability. This structured framework aims to provide AI/ML researchers with the necessary clarity on these essential concepts, facilitating the appropriate design, conduct, and interpretation of validation studies. By articulating the nuances and specific roles of each type of validation study, we hope to contribute to a more informed and methodical approach to addressing the challenges of reproducibility, thereby supporting the community's efforts to enhance the reliability and trustworthiness of its research findings.
Read more7/16/2024
0
AI Research is not Magic, it has to be Reproducible and Responsible: Challenges in the AI field from the Perspective of its PhD Students
Andrea Hrckova, Jennifer Renoux, Rafael Tolosana Calasanz, Daniela Chuda, Martin Tamajka, Jakub Simko
With the goal of uncovering the challenges faced by European AI students during their research endeavors, we surveyed 28 AI doctoral candidates from 13 European countries. The outcomes underscore challenges in three key areas: (1) the findability and quality of AI resources such as datasets, models, and experiments; (2) the difficulties in replicating the experiments in AI papers; (3) and the lack of trustworthiness and interdisciplinarity. From our findings, it appears that although early stage AI researchers generally tend to share their AI resources, they lack motivation or knowledge to engage more in dataset and code preparation and curation, and ethical assessments, and are not used to cooperate with well-versed experts in application domains. Furthermore, we examine existing practices in data governance and reproducibility both in computer science and in artificial intelligence. For instance, only a minority of venues actively promote reproducibility initiatives such as reproducibility evaluations. Critically, there is need for immediate adoption of responsible and reproducible AI research practices, crucial for society at large, and essential for the AI research community in particular. This paper proposes a combination of social and technical recommendations to overcome the identified challenges. Socially, we propose the general adoption of reproducibility initiatives in AI conferences and journals, as well as improved interdisciplinary collaboration, especially in data governance practices. On the technical front, we call for enhanced tools to better support versioning control of datasets and code, and a computing infrastructure that facilitates the sharing and discovery of AI resources, as well as the sharing, execution, and verification of experiments.
Read more8/14/2024
📊
0
Integrating measures of replicability into scholarly search: Challenges and opportunities
Chuhao Wu, Tatiana Chakravorti, John Carroll, Sarah Rajtmajer
Challenges to reproducibility and replicability have gained widespread attention, driven by large replication projects with lukewarm success rates. A nascent work has emerged developing algorithms to estimate the replicability of published findings. The current study explores ways in which AI-enabled signals of confidence in research might be integrated into the literature search. We interview 17 PhD researchers about their current processes for literature search and ask them to provide feedback on a replicability estimation tool. Our findings suggest that participants tend to confuse replicability with generalizability and related concepts. Information about replicability can support researchers throughout the research design processes. However, the use of AI estimation is debatable due to the lack of explainability and transparency. The ethical implications of AI-enabled confidence assessment must be further studied before such tools could be widely accepted. We discuss implications for the design of technological tools to support scholarly activities and advance replicability.
Read more5/6/2024