RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale
2406.16801
2
0
Abstract
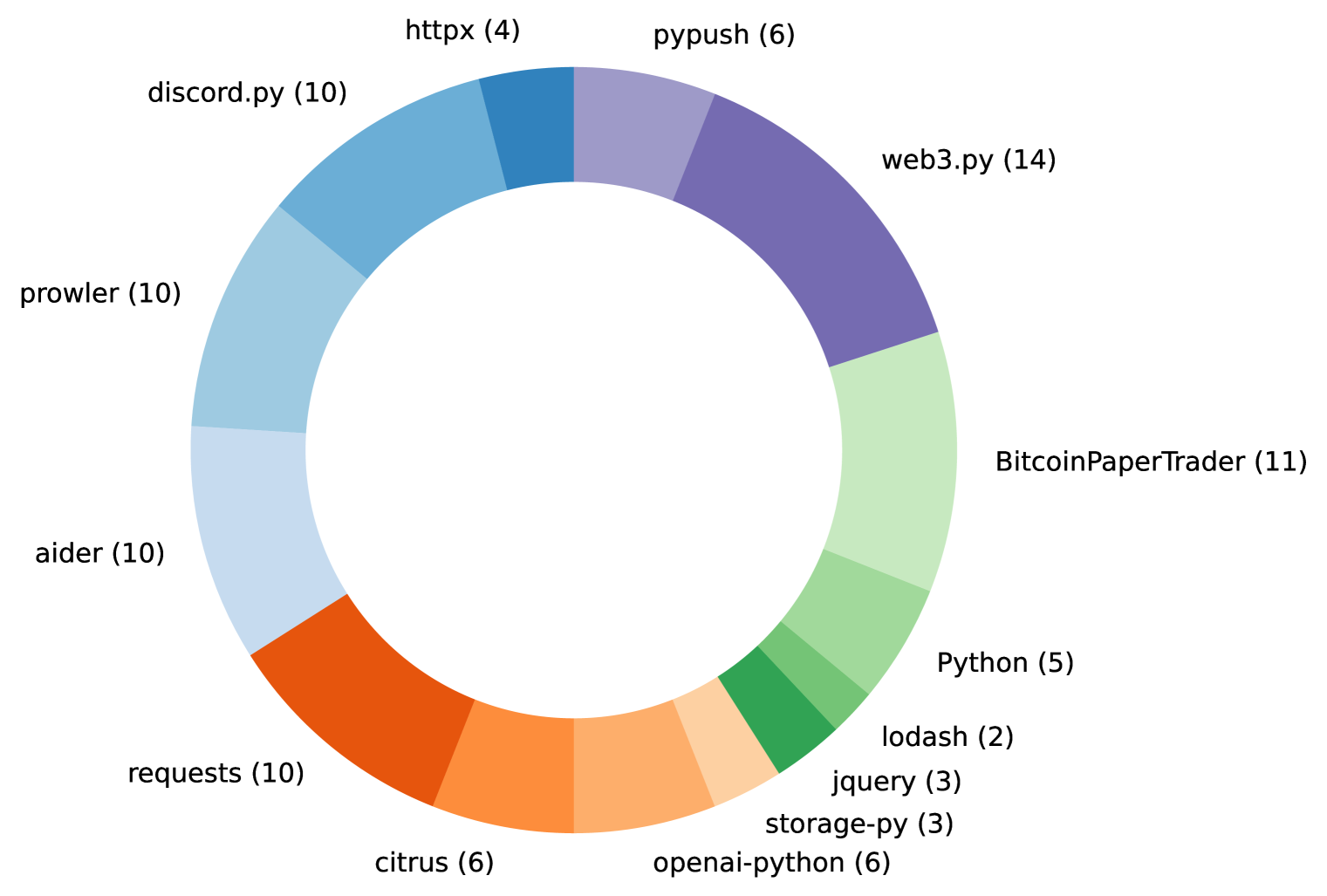
The instruction-following ability of Large Language Models (LLMs) has cultivated a class of LLM-based systems capable of approaching complex tasks such as making edits to large code repositories. Due to the high sensitivity and unpredictability of LLM behavior in response to changes in prompting, robust evaluation tools are needed to drive future iteration of these systems. We propose RES-Q, a natural language instruction-based benchmark for evaluating $textbf{R}$epository $textbf{E}$diting $textbf{S}$ystems, which consists of 100 handcrafted repository editing tasks derived from real GitHub commits. Given an edit instruction and a code repository, RES-Q evaluates an LLM system's ability to interpret the instruction, navigate the repository to gather relevant information, and construct an appropriate edit that satisfies the specified criteria. We argue that evaluating LLMs in this way addresses issues with traditional benchmarks and provides a more holistic assessment of a model's abilities. We evaluate various state-of-the-art LLMs as language agents in a repository-editing system built on Qurrent OS, our language agent development software. Despite their 1% pass@1 performance difference on HumanEval, we find Claude Sonnet 3.5 outperforms GPT-4o by 12% pass@1 on RES-Q, indicating RES-Q's capacity to differentiate model capability as traditional benchmarks approach saturation. We further investigate token efficiency, performance relationships with existing benchmarks, and interesting disparities between closed and open-source LLMs. Code and dataset are available at https://github.com/Qurrent-AI/RES-Q.
Create account to get full access
Overview
- This paper, titled "RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale," explores the potential of large language models (LLMs) to automate software development tasks.
- The researchers propose a new benchmark, RES-Q, which aims to assess the code-editing capabilities of LLMs at a repository scale, beyond the traditional code-generation or code-understanding tasks.
- The paper presents the design and implementation of the RES-Q benchmark, as well as experiments conducted to evaluate the performance of various LLM systems on this task.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive abilities in generating human-like text, and researchers are now exploring how these models can be applied to software development tasks. The idea is that LLMs could potentially automate certain code-related activities, such as fixing bugs, refactoring code, or even writing entire programs from scratch.
The authors of this paper have developed a new benchmark called RES-Q, which aims to evaluate how well LLMs can perform code-editing tasks at a larger, repository-scale level. Rather than just looking at how well an LLM can generate or understand small snippets of code, RES-Q assesses the model's ability to comprehend the context of an entire codebase and make meaningful changes to it.
The researchers ran experiments using various LLM systems and found that while these models can perform well on certain code-editing tasks, they still struggle with more complex, context-dependent challenges. This suggests that while LLMs show promise for automating software development, there is still a lot of room for improvement before they can fully replace human programmers.
Technical Explanation
The paper introduces the RES-Q benchmark, which is designed to assess the code-editing capabilities of LLMs at a repository scale. The benchmark consists of a collection of programming tasks, such as bug fixing, code refactoring, and feature addition, that are applied to real-world code repositories.
To evaluate the performance of LLMs on these tasks, the researchers collected a dataset of code repositories, along with corresponding human-written edits and explanations. They then fine-tuned several LLM systems, including GPT-3 and CodeT5, on this dataset and measured their ability to generate the correct code edits given the repository context.
The experiments revealed that while the LLMs were able to perform well on some code-editing tasks, they struggled with more complex challenges that required a deeper understanding of the codebase and its context. For example, the models had difficulty identifying the appropriate locations within the code to make changes and ensuring that the edits were consistent with the overall structure and functionality of the program.
Critical Analysis
The RES-Q benchmark represents an important step forward in evaluating the code-editing capabilities of LLMs, as it moves beyond the traditional code-generation or code-understanding tasks and focuses on the more complex and realistic challenges of working with large, real-world codebases.
However, the paper also acknowledges several limitations of the current approach. For example, the dataset used for fine-tuning the LLMs may not be comprehensive enough to capture the full range of code-editing challenges that developers face in practice. Additionally, the evaluation metrics used in the study may not fully capture the nuances of code quality and maintainability, which are crucial considerations in software development.
Furthermore, the paper does not address the potential ethical and societal implications of automating software development tasks with LLMs. As these models become more capable, there are concerns about job displacement, the risk of introducing new types of software vulnerabilities, and the potential for biases and errors to be amplified at scale.
Conclusion
The RES-Q benchmark represents an important step forward in evaluating the code-editing capabilities of large language models. While the results suggest that these models show promise for automating certain software development tasks, they also highlight the significant challenges that remain before LLMs can fully replace human programmers.
As the field of AI-assisted software development continues to evolve, it will be crucial to address the technical, ethical, and societal implications of these technologies. Ongoing research and development in this area will be essential for ensuring that the benefits of LLMs are realized in a responsible and sustainable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
ML-Bench: Evaluating Large Language Models and Agents for Machine Learning Tasks on Repository-Level Code
Xiangru Tang, Yuliang Liu, Zefan Cai, Yanjun Shao, Junjie Lu, Yichi Zhang, Zexuan Deng, Helan Hu, Kaikai An, Ruijun Huang, Shuzheng Si, Sheng Chen, Haozhe Zhao, Liang Chen, Yan Wang, Tianyu Liu, Zhiwei Jiang, Baobao Chang, Yin Fang, Yujia Qin, Wangchunshu Zhou, Yilun Zhao, Arman Cohan, Mark Gerstein
0
0
Despite Large Language Models (LLMs) like GPT-4 achieving impressive results in function-level code generation, they struggle with repository-scale code understanding (e.g., coming up with the right arguments for calling routines), requiring a deeper comprehension of complex file interactions. Also, recently, people have developed LLM agents that attempt to interact with repository code (e.g., compiling and evaluating its execution), prompting the need to evaluate their performance. These gaps have motivated our development of ML-Bench, a benchmark rooted in real-world programming applications that leverage existing code repositories to perform tasks. Addressing the need for LLMs to interpret long code contexts and translate instructions into precise, executable scripts, ML-Bench encompasses annotated 9,641 examples across 18 GitHub repositories, challenging LLMs to accommodate user-specified arguments and documentation intricacies effectively. To evaluate both LLMs and AI agents, two setups are employed: ML-LLM-Bench for assessing LLMs' text-to-code conversion within a predefined deployment environment, and ML-Agent-Bench for testing autonomous agents in an end-to-end task execution within a Linux sandbox environment. Our findings indicate that while GPT-4o leads with a Pass@5 rate surpassing 50%, there remains significant scope for improvement, highlighted by issues such as hallucinated outputs and difficulties with bash script generation. Notably, in the more demanding ML-Agent-Bench, GPT-4o achieves a 76.47% success rate, reflecting the efficacy of iterative action and feedback in complex task resolution. Our code, dataset, and models are available at https://github.com/gersteinlab/ML-bench.
6/19/2024
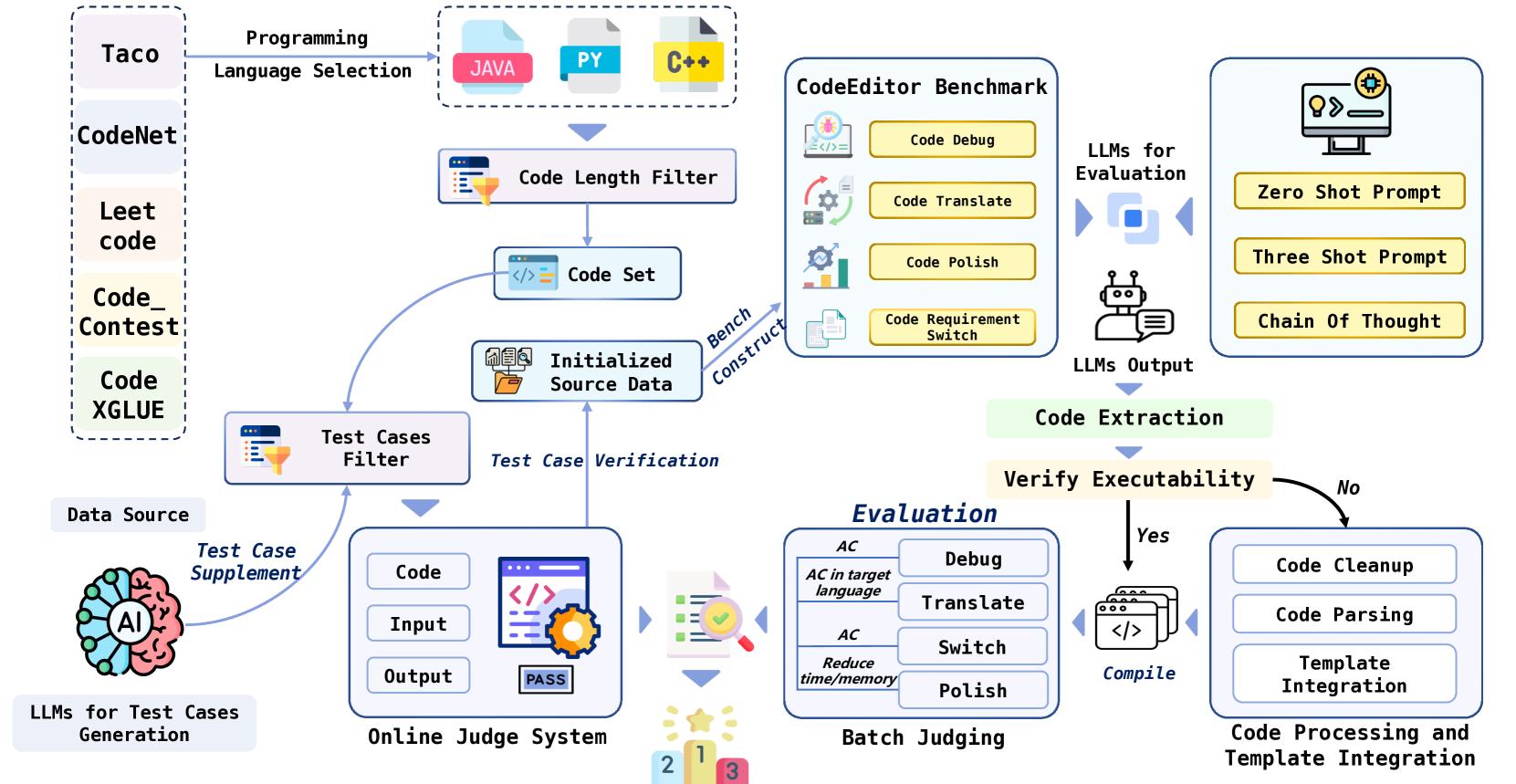
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
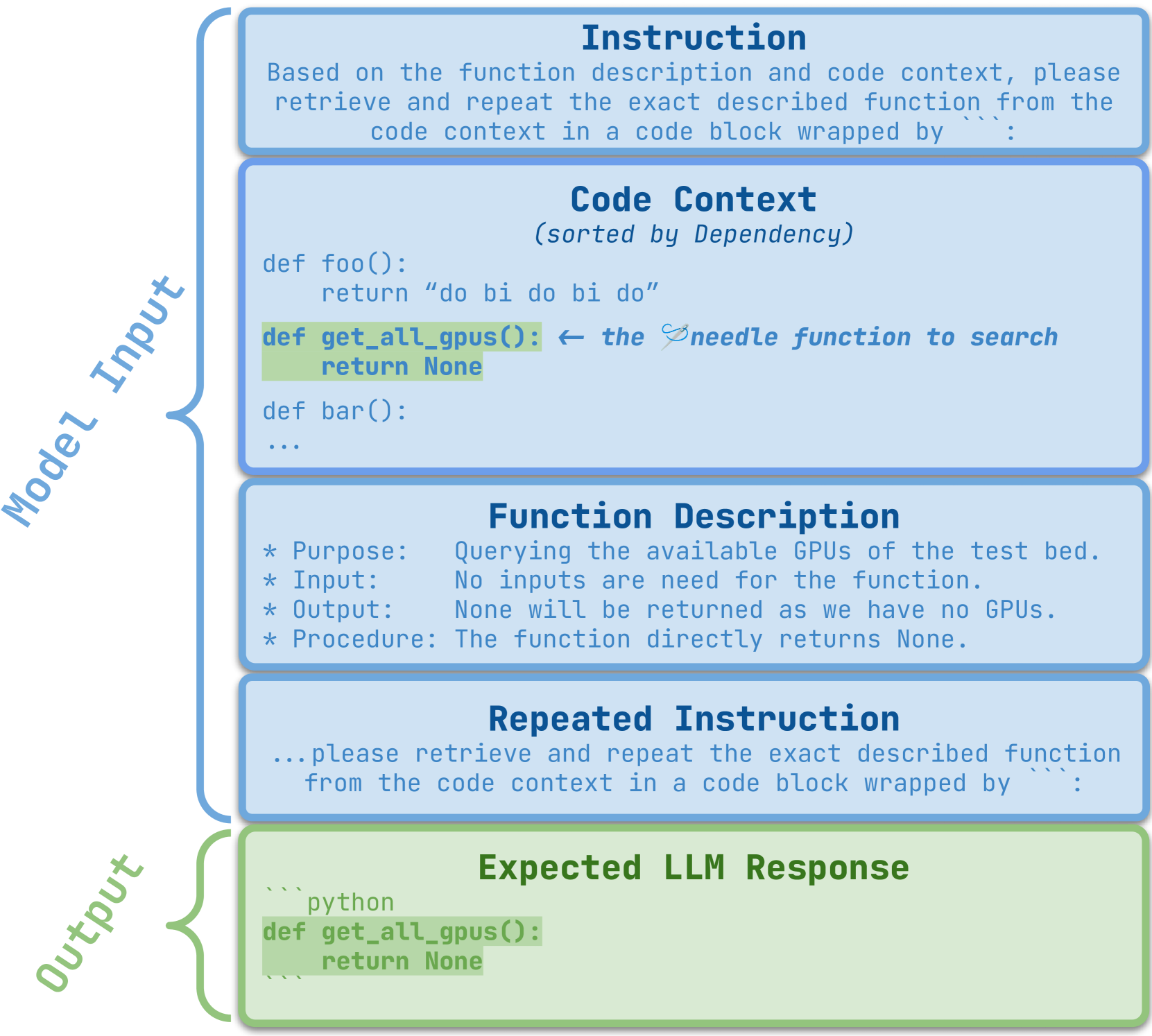
RepoQA: Evaluating Long Context Code Understanding
Jiawei Liu, Jia Le Tian, Vijay Daita, Yuxiang Wei, Yifeng Ding, Yuhan Katherine Wang, Jun Yang, Lingming Zhang
0
0
Recent advances have been improving the context windows of Large Language Models (LLMs). To quantify the real long-context capabilities of LLMs, evaluators such as the popular Needle in a Haystack have been developed to test LLMs over a large chunk of raw texts. While effective, current evaluations overlook the insight of how LLMs work with long-context code, i.e., repositories. To this end, we initiate the RepoQA benchmark to evaluate LLMs on long-context code understanding. Traditional needle testers ask LLMs to directly retrieve the answer from the context without necessary deep understanding. In RepoQA, we built our initial task, namely Searching Needle Function (SNF), which exercises LLMs to search functions given their natural-language description, i.e., LLMs cannot find the desired function if they cannot understand the description and code. RepoQA is multilingual and comprehensive: it includes 500 code search tasks gathered from 50 popular repositories across 5 modern programming languages. By evaluating 26 general and code-specific LLMs on RepoQA, we show (i) there is still a small gap between the best open and proprietary models; (ii) different models are good at different languages; and (iii) models may understand code better without comments.
6/11/2024
🛸
Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository
Ajinkya Deshpande, Anmol Agarwal, Shashank Shet, Arun Iyer, Aditya Kanade, Ramakrishna Bairi, Suresh Parthasarathy
0
0
LLMs have demonstrated significant potential in code generation tasks, achieving promising results at the function or statement level across various benchmarks. However, the complexities associated with creating code artifacts like classes, particularly within the context of real-world software repositories, remain underexplored. Prior research treats class-level generation as an isolated task, neglecting the intricate dependencies & interactions that characterize real-world software environments. To address this gap, we introduce RepoClassBench, a comprehensive benchmark designed to rigorously evaluate LLMs in generating complex, class-level code within real-world repositories. RepoClassBench includes Natural Language to Class generation tasks across Java, Python & C# from a selection of repositories. We ensure that each class in our dataset not only has cross-file dependencies within the repository but also includes corresponding test cases to verify its functionality. We find that current models struggle with the realistic challenges posed by our benchmark, primarily due to their limited exposure to relevant repository contexts. To address this shortcoming, we introduce Retrieve-Repotools-Reflect (RRR), a novel approach that equips LLMs with static analysis tools to iteratively navigate & reason about repository-level context in an agent-based framework. Our experiments demonstrate that RRR significantly outperforms existing baselines on RepoClassBench, showcasing its effectiveness across programming languages & under various settings. Our findings emphasize the critical need for code-generation benchmarks to incorporate repo-level dependencies to more accurately reflect the complexities of software development. Our work shows the benefits of leveraging specialized tools to enhance LLMs' understanding of repository context. We plan to make our dataset & evaluation harness public.
6/6/2024