Res-VMamba: Fine-Grained Food Category Visual Classification Using Selective State Space Models with Deep Residual Learning

0

Sign in to get full access
Overview
- This paper introduces Res-VMamba, a fine-grained food category visual classification model that uses selective state space models and deep residual learning.
- The model aims to improve on existing approaches for accurately classifying a wide range of food items.
- Key innovations include the use of state space models to capture fine-grained visual features and the integration of deep residual learning for enhanced performance.
Plain English Explanation
The researchers have developed a new computer vision model called Res-VMamba that can accurately classify a wide variety of food items. Classifying food visually can be challenging because there are often small but important differences between similar-looking items.
To address this, the Res-VMamba model uses a state space model to capture detailed visual features. State space models are a type of mathematical framework that can represent complex systems with many interacting parts. In this case, the state space model allows the Res-VMamba system to hone in on the subtle distinguishing characteristics of different food items.
The model also incorporates deep residual learning, an AI technique that has proven effective for image recognition tasks. Deep residual learning helps the Res-VMamba model learn efficient representations of food images, improving its overall classification accuracy.
By combining these techniques, the researchers have created a food classification system that can reliably distinguish between a wide range of food categories, even ones that appear quite similar. This could have applications in areas like nutrition tracking, restaurant inventory management, and medical image analysis.
Technical Explanation
The core innovation of the Res-VMamba model is its use of selective state space models to capture fine-grained visual features for food classification. State space models are a powerful mathematical framework that can represent complex systems with many interacting variables.
In the context of this research, the state space model allows the Res-VMamba system to hone in on the subtle distinguishing characteristics of different food items, such as texture, shape, and color patterns. This selective modeling of visual features is key to achieving high accuracy on challenging fine-grained food classification tasks.
The Res-VMamba architecture also incorporates deep residual learning, a popular technique in computer vision that has been shown to improve image recognition performance. Deep residual learning helps the model learn more efficient visual representations, which boosts its overall classification capabilities.
The researchers evaluated Res-VMamba on several benchmark food classification datasets and found that it outperformed state-of-the-art approaches. This highlights the value of combining selective state space modeling with deep residual learning for fine-grained visual recognition problems.
Critical Analysis
The Res-VMamba research makes a compelling case for the benefits of integrating state space models and deep residual learning for food classification tasks. The experimental results demonstrate significant performance improvements over prior methods, suggesting the approach has merit.
That said, the paper does not provide extensive analysis of the limitations or failure cases of the Res-VMamba model. For example, it's unclear how the model would perform on highly occluded or low-resolution food images, which are common real-world challenges. Additionally, the computational complexity and inference speed of the approach are not thoroughly investigated.
Further research could explore the trade-offs between the model's classification accuracy and its efficiency, as well as its robustness to common visual distortions. Comparisons to other advanced food classification techniques, such as those using few-shot learning or cross-modal information, could also provide additional insights.
Overall, the Res-VMamba research represents a promising step forward in fine-grained visual recognition, but additional work is needed to fully understand the strengths, limitations, and practical applications of the approach.
Conclusion
The Res-VMamba model introduced in this paper demonstrates the value of combining selective state space modeling and deep residual learning for fine-grained food category classification. By leveraging the strengths of these two techniques, the researchers have developed a system that can accurately distinguish between a wide variety of food items, even those that appear visually similar.
The potential applications of this work are broad, ranging from nutrition tracking and restaurant inventory management to medical image analysis. As the field of computer vision continues to advance, models like Res-VMamba could play an increasingly important role in automating and enhancing various tasks that require detailed visual recognition capabilities.
While the research shows promising results, further investigation is needed to fully understand the model's limitations and explore potential avenues for improvement. Nonetheless, the Res-VMamba paper represents an important contribution to the ongoing effort to develop robust and versatile visual classification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Res-VMamba: Fine-Grained Food Category Visual Classification Using Selective State Space Models with Deep Residual Learning
Chi-Sheng Chen, Guan-Ying Chen, Dong Zhou, Di Jiang, Dai-Shi Chen
Food classification is the foundation for developing food vision tasks and plays a key role in the burgeoning field of computational nutrition. Due to the complexity of food requiring fine-grained classification, recent academic research mainly modifies Convolutional Neural Networks (CNNs) and/or Vision Transformers (ViTs) to perform food category classification. However, to learn fine-grained features, the CNN backbone needs additional structural design, whereas ViT, containing the self-attention module, has increased computational complexity. In recent months, a new Sequence State Space (S4) model, through a Selection mechanism and computation with a Scan (S6), colloquially termed Mamba, has demonstrated superior performance and computation efficiency compared to the Transformer architecture. The VMamba model, which incorporates the Mamba mechanism into image tasks (such as classification), currently establishes the state-of-the-art (SOTA) on the ImageNet dataset. In this research, we introduce an academically underestimated food dataset CNFOOD-241, and pioneer the integration of a residual learning framework within the VMamba model to concurrently harness both global and local state features inherent in the original VMamba architectural design. The research results show that VMamba surpasses current SOTA models in fine-grained and food classification. The proposed Res-VMamba further improves the classification accuracy to 79.54% without pretrained weight. Our findings elucidate that our proposed methodology establishes a new benchmark for SOTA performance in food recognition on the CNFOOD-241 dataset. The code can be obtained on GitHub: https://github.com/ChiShengChen/ResVMamba.
Read more9/9/2024
0
VMamba: Visual State Space Model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu
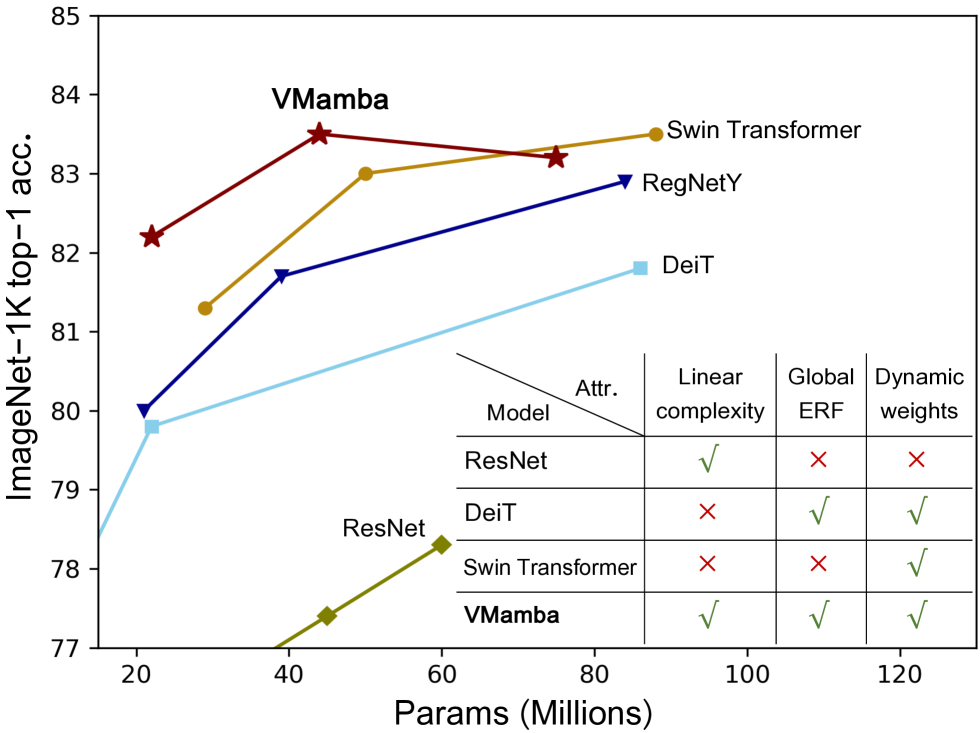
Designing computationally efficient network architectures persists as an ongoing necessity in computer vision. In this paper, we transplant Mamba, a state-space language model, into VMamba, a vision backbone that works in linear time complexity. At the core of VMamba lies a stack of Visual State-Space (VSS) blocks with the 2D Selective Scan (SS2D) module. By traversing along four scanning routes, SS2D helps bridge the gap between the ordered nature of 1D selective scan and the non-sequential structure of 2D vision data, which facilitates the gathering of contextual information from various sources and perspectives. Based on the VSS blocks, we develop a family of VMamba architectures and accelerate them through a succession of architectural and implementation enhancements. Extensive experiments showcase VMamba's promising performance across diverse visual perception tasks, highlighting its advantages in input scaling efficiency compared to existing benchmark models. Source code is available at https://github.com/MzeroMiko/VMamba.
Read more5/28/2024
📈
0
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
Yuheng Shi, Minjing Dong, Chang Xu
Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 82.8% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.2% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.6% mIoU with single-scale testing on ADE20K.Code is available at url{https://github.com/YuHengsss/MSVMamba}.
Read more5/24/2024
0
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
Read more4/29/2024