A Survey on Model Compression for Large Language Models

0
📈
Sign in to get full access
Overview
- Large Language Models (LLMs) have revolutionized natural language processing tasks.
- However, their large size and high computational needs pose challenges for practical use, especially in resource-limited settings.
- Model compression has emerged as a key research area to address these challenges.
Plain English Explanation
Large Language Models (LLMs) are powerful artificial intelligence systems that can understand and generate human-like text. They have been incredibly successful at tasks like language translation, question answering, and text generation. However, these models are massive in size and require a lot of computing power to run, which can make them difficult to use in real-world applications, especially on devices with limited resources like smartphones or embedded systems.
To address this issue, researchers have been exploring model compression techniques. These are methods that can shrink the size of the LLM and reduce the amount of computing power needed, without significantly compromising its performance. Some common compression techniques include quantization, where the model's parameters are represented using fewer bits, pruning, which removes parts of the model that aren't essential, and knowledge distillation, which transfers the knowledge from a large model to a smaller one.
By applying these compression techniques, researchers hope to make LLMs more practical and accessible, allowing them to be used in a wider range of applications, from smart assistants on phones to language translation on edge devices.
Technical Explanation
This paper provides a comprehensive survey of the latest model compression techniques for Large Language Models (LLMs). The authors cover a range of methods, including:
- Quantization: Reducing the precision of the model's parameters, allowing for smaller model size and faster inference.
- Pruning: Removing parts of the model that are less important, reducing the overall model size without significantly impacting performance.
- Knowledge Distillation: Training a smaller "student" model to mimic the behavior of a larger "teacher" model, transferring the knowledge from the larger to the smaller model.
The paper also discusses strategies for benchmarking and evaluating the performance of compressed LLMs, including metrics like accuracy, inference latency, and memory footprint. The authors highlight recent advancements in each compression technique and provide insights into the trade-offs and considerations involved in applying them.
Critical Analysis
The paper provides a thorough and well-structured overview of the current state of model compression for LLMs. The authors cover a wide range of compression techniques and discuss their relative strengths and weaknesses, which is valuable for researchers and practitioners looking to apply these methods.
One potential limitation of the paper is that it focuses mainly on the technical aspects of model compression, without delving too deeply into the real-world implications and challenges of deploying compressed LLMs. For example, the paper could have explored issues like the impact of compression on model interpretability, fairness, and safety, or the challenges of integrating compressed models into existing systems.
Additionally, the paper could have investigated the potential trade-offs between compression and other model optimization techniques, such as architectural changes or efficient hardware design. Exploring these broader considerations would help provide a more holistic understanding of the challenges and opportunities in making LLMs more practical and accessible.
Conclusion
This survey paper offers a comprehensive and valuable overview of the latest model compression techniques for Large Language Models. By summarizing the key methods, benchmarking strategies, and recent advancements, the authors provide a solid foundation for researchers and practitioners working to enhance the efficiency and real-world applicability of these powerful AI systems. As the field of model compression continues to evolve, this paper lays the groundwork for future advancements that may make LLMs more accessible and impactful across a wider range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
A Survey on Model Compression for Large Language Models
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang
Large Language Models (LLMs) have transformed natural language processing tasks successfully. Yet, their large size and high computational needs pose challenges for practical use, especially in resource-limited settings. Model compression has emerged as a key research area to address these challenges. This paper presents a survey of model compression techniques for LLMs. We cover methods like quantization, pruning, and knowledge distillation, highlighting recent advancements. We also discuss benchmarking strategies and evaluation metrics crucial for assessing compressed LLMs. This survey offers valuable insights for researchers and practitioners, aiming to enhance efficiency and real-world applicability of LLMs while laying a foundation for future advancements.
Read more7/31/2024
📈
0
Contemporary Model Compression on Large Language Models Inference
Dong Liu
Large Language Models (LLMs) have revolutionized natural language processing by achieving state-of-the-art results across a variety of tasks. However, the computational demands of LLM inference, including high memory consumption and slow processing speeds, pose significant challenges for real-world applications, particularly on resource-constrained devices. Efficient inference is crucial for scaling the deployment of LLMs to a broader range of platforms, including mobile and edge devices. This survey explores contemporary techniques in model compression that address these challenges by reducing the size and computational requirements of LLMs while maintaining their performance. We focus on model-level compression methods, including quantization, knowledge distillation, and pruning, as well as system-level optimizations like KV cache efficient design. Each of these methodologies offers a unique approach to optimizing LLMs, from reducing numerical precision to transferring knowledge between models and structurally simplifying neural networks. Additionally, we discuss emerging trends in system-level design that further enhance the efficiency of LLM inference. This survey aims to provide a comprehensive overview of current advancements in model compression and their potential to make LLMs more accessible and practical for diverse applications.
Read more9/4/2024

0
Comprehensive Study on Performance Evaluation and Optimization of Model Compression: Bridging Traditional Deep Learning and Large Language Models
Aayush Saxena, Arit Kumar Bishwas, Ayush Ashok Mishra, Ryan Armstrong
Deep learning models have achieved tremendous success in most of the industries in recent years. The evolution of these models has also led to an increase in the model size and energy requirement, making it difficult to deploy in production on low compute devices. An increase in the number of connected devices around the world warrants compressed models that can be easily deployed at the local devices with low compute capacity and power accessibility. A wide range of solutions have been proposed by different researchers to reduce the size and complexity of such models, prominent among them are, Weight Quantization, Parameter Pruning, Network Pruning, low-rank representation, weights sharing, neural architecture search, knowledge distillation etc. In this research work, we investigate the performance impacts on various trained deep learning models, compressed using quantization and pruning techniques. We implemented both, quantization and pruning, compression techniques on popular deep learning models used in the image classification, object detection, language models and generative models-based problem statements. We also explored performance of various large language models (LLMs) after quantization and low rank adaptation. We used the standard evaluation metrics (model's size, accuracy, and inference time) for all the related problem statements and concluded this paper by discussing the challenges and future work.
Read more7/24/2024
0
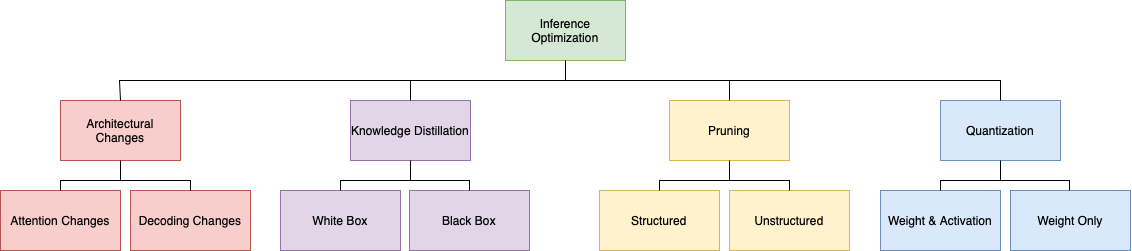
Inference Optimizations for Large Language Models: Effects, Challenges, and Practical Considerations
Leo Donisch, Sigurd Schacht, Carsten Lanquillon
Large language models are ubiquitous in natural language processing because they can adapt to new tasks without retraining. However, their sheer scale and complexity present unique challenges and opportunities, prompting researchers and practitioners to explore novel model training, optimization, and deployment methods. This literature review focuses on various techniques for reducing resource requirements and compressing large language models, including quantization, pruning, knowledge distillation, and architectural optimizations. The primary objective is to explore each method in-depth and highlight its unique challenges and practical applications. The discussed methods are categorized into a taxonomy that presents an overview of the optimization landscape and helps navigate it to understand the research trajectory better.
Read more8/7/2024