Resource-Efficient Federated Multimodal Learning via Layer-wise and Progressive Training

0

Sign in to get full access
Overview
- This paper introduces a resource-efficient approach to federated multimodal learning using layer-wise and progressive training.
- The key ideas are:
- Layer-wise training: Training different layers of the neural network independently to reduce resource requirements.
- Progressive training: Gradually increasing model complexity during the training process to further optimize resource usage.
- The proposed method aims to improve the efficiency of federated learning for multimodal tasks, such as combining text, image, and audio data.
Plain English Explanation
In the world of machine learning, there is a technique called federated learning that allows multiple devices or organizations to train a shared model without sharing their data directly. This is particularly useful for sensitive or large-scale datasets.
However, when dealing with multimodal data (e.g., text, images, and audio), the training process can become resource-intensive, as the model needs to learn to process and integrate different types of information.
This paper presents a more resource-efficient approach to federated multimodal learning. The key ideas are:
-
Layer-wise training: Instead of training the entire model at once, the researchers train different layers of the neural network independently. This reduces the computational and memory requirements on each device participating in the federated learning process.
-
Progressive training: The model complexity is gradually increased during the training process. This means the model starts with a simpler architecture and becomes more sophisticated over time, further optimizing resource usage.
By using these techniques, the researchers aim to make federated multimodal learning more practical and accessible, especially for devices with limited resources, such as smartphones or edge devices. This could enable a wider range of applications that leverage diverse data sources while preserving privacy.
Technical Explanation
The researchers propose a Resource-Efficient Federated Multimodal Learning (RE-FML) framework that combines layer-wise and progressive training approaches.
Layer-wise training: Instead of training the entire model at once, the researchers train each layer of the neural network independently. This reduces the memory and computational requirements on each client device participating in the federated learning process. The gradients from each layer are then aggregated at the server to update the global model.
Progressive training: The model complexity is gradually increased during the training process. This means the model starts with a simpler architecture and becomes more sophisticated over time. The researchers introduce a progressive training scheduler that determines when to increase the model complexity, such as adding more layers or increasing the number of parameters.
The researchers evaluate their approach on several multimodal datasets, including text, image, and audio data. They compare the performance and resource efficiency of RE-FML to traditional federated learning approaches and find that their method achieves comparable accuracy while significantly reducing the computational and memory requirements on client devices.
Critical Analysis
The researchers have identified an important challenge in federated learning for multimodal tasks and have proposed a novel solution to address it. The layer-wise and progressive training approaches seem promising for improving resource efficiency, which could enable a wider range of real-world applications of federated learning.
However, the paper does not discuss potential limitations or drawbacks of the proposed method. For example, the impact of layer-wise training on model performance and the effectiveness of the progressive training scheduler in different scenarios could be further explored. Additionally, the paper does not provide detailed comparisons to other resource-efficient federated learning approaches, such as federated learning with incomplete sensing modalities, which could provide additional insights.
Overall, the research presented in this paper is a valuable contribution to the field of federated learning, and the proposed techniques could have significant implications for the development of efficient and practical multimodal applications in a privacy-preserving manner.
Conclusion
This paper introduces a resource-efficient approach to federated multimodal learning, combining layer-wise and progressive training techniques. By training different layers of the neural network independently and gradually increasing model complexity, the proposed framework, RE-FML, aims to reduce the computational and memory requirements on client devices while maintaining comparable performance to traditional federated learning methods.
The layer-wise and progressive training strategies could enable a wider adoption of federated learning for multimodal applications, particularly in resource-constrained environments like edge devices or mobile phones. This could lead to the development of novel applications that leverage diverse data sources while preserving user privacy.
Further research is needed to explore the potential limitations and drawbacks of the proposed method, as well as to compare it more extensively with other resource-efficient federated learning approaches. Nevertheless, the ideas presented in this paper represent an important step towards more efficient and practical federated multimodal learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Resource-Efficient Federated Multimodal Learning via Layer-wise and Progressive Training
Ye Lin Tun, Chu Myaet Thwal, Minh N. H. Nguyen, Choong Seon Hong
Combining different data modalities enables deep neural networks to tackle complex tasks more effectively, making multimodal learning increasingly popular. To harness multimodal data closer to end users, it is essential to integrate multimodal learning with privacy-preserving training approaches such as federated learning (FL). However, compared to conventional unimodal learning, multimodal setting requires dedicated encoders for each modality, resulting in larger and more complex models that demand significant resources. This presents a substantial challenge for FL clients operating with limited computational resources and communication bandwidth. To address these challenges, we introduce LW-FedMML, a layer-wise federated multimodal learning approach, which decomposes the training process into multiple steps. Each step focuses on training only a portion of the model, thereby significantly reducing the memory and computational requirements. Moreover, FL clients only need to exchange the trained model portion with the central server, lowering the resulting communication cost. We conduct extensive experiments across various FL scenarios and multimodal learning setups to validate the effectiveness of our proposed method. The results demonstrate that LW-FedMML can compete with conventional end-to-end federated multimodal learning (FedMML) while significantly reducing the resource burden on FL clients. Specifically, LW-FedMML reduces memory usage by up to $2.7times$, computational operations (FLOPs) by $2.4times$, and total communication cost by $2.3times$. We also introduce a progressive training approach called Prog-FedMML. While it offers lesser resource efficiency than LW-FedMML, Prog-FedMML has the potential to surpass the performance of end-to-end FedMML, making it a viable option for scenarios with fewer resource constraints.
Read more7/23/2024

0
MLLM-FL: Multimodal Large Language Model Assisted Federated Learning on Heterogeneous and Long-tailed Data
Jianyi Zhang, Hao Frank Yang, Ang Li, Xin Guo, Pu Wang, Haiming Wang, Yiran Chen, Hai Li
Previous studies on federated learning (FL) often encounter performance degradation due to data heterogeneity among different clients. In light of the recent advances in multimodal large language models (MLLMs), such as GPT-4v and LLaVA, which demonstrate their exceptional proficiency in multimodal tasks, such as image captioning and multimodal question answering. We introduce a novel federated learning framework, named Multimodal Large Language Model Assisted Federated Learning (MLLM-FL), which which employs powerful MLLMs at the server end to address the heterogeneous and long-tailed challenges. Owing to the advanced cross-modality representation capabilities and the extensive open-vocabulary prior knowledge of MLLMs, our framework is adept at harnessing the extensive, yet previously underexploited, open-source data accessible from websites and powerful server-side computational resources. Hence, the MLLM-FL not only enhances the performance but also avoids increasing the risk of privacy leakage and the computational burden on local devices, distinguishing it from prior methodologies. Our framework has three key stages. Initially, prior to local training on local datasets of clients, we conduct global visual-text pretraining of the model. This pretraining is facilitated by utilizing the extensive open-source data available online, with the assistance of multimodal large language models. Subsequently, the pretrained model is distributed among various clients for local training. Finally, once the locally trained models are transmitted back to the server, a global alignment is carried out under the supervision of MLLMs to further enhance the performance. Experimental evaluations on established benchmarks, show that our framework delivers promising performance in the typical scenarios with data heterogeneity and long-tail distribution across different clients in FL.
Read more9/11/2024
⚙️
0
Leveraging Foundation Models for Multi-modal Federated Learning with Incomplete Modality
Liwei Che, Jiaqi Wang, Xinyue Liu, Fenglong Ma
Federated learning (FL) has obtained tremendous progress in providing collaborative training solutions for distributed data silos with privacy guarantees. However, few existing works explore a more realistic scenario where the clients hold multiple data modalities. In this paper, we aim to solve a novel challenge in multi-modal federated learning (MFL) -- modality missing -- the clients may lose part of the modalities in their local data sets. To tackle the problems, we propose a novel multi-modal federated learning method, Federated Multi-modal contrastiVe training with Pre-trained completion (FedMVP), which integrates the large-scale pre-trained models to enhance the federated training. In the proposed FedMVP framework, each client deploys a large-scale pre-trained model with frozen parameters for modality completion and representation knowledge transfer, enabling efficient and robust local training. On the server side, we utilize generated data to uniformly measure the representation similarity among the uploaded client models and construct a graph perspective to aggregate them according to their importance in the system. We demonstrate that the model achieves superior performance over two real-world image-text classification datasets and is robust to the performance degradation caused by missing modality.
Read more6/18/2024
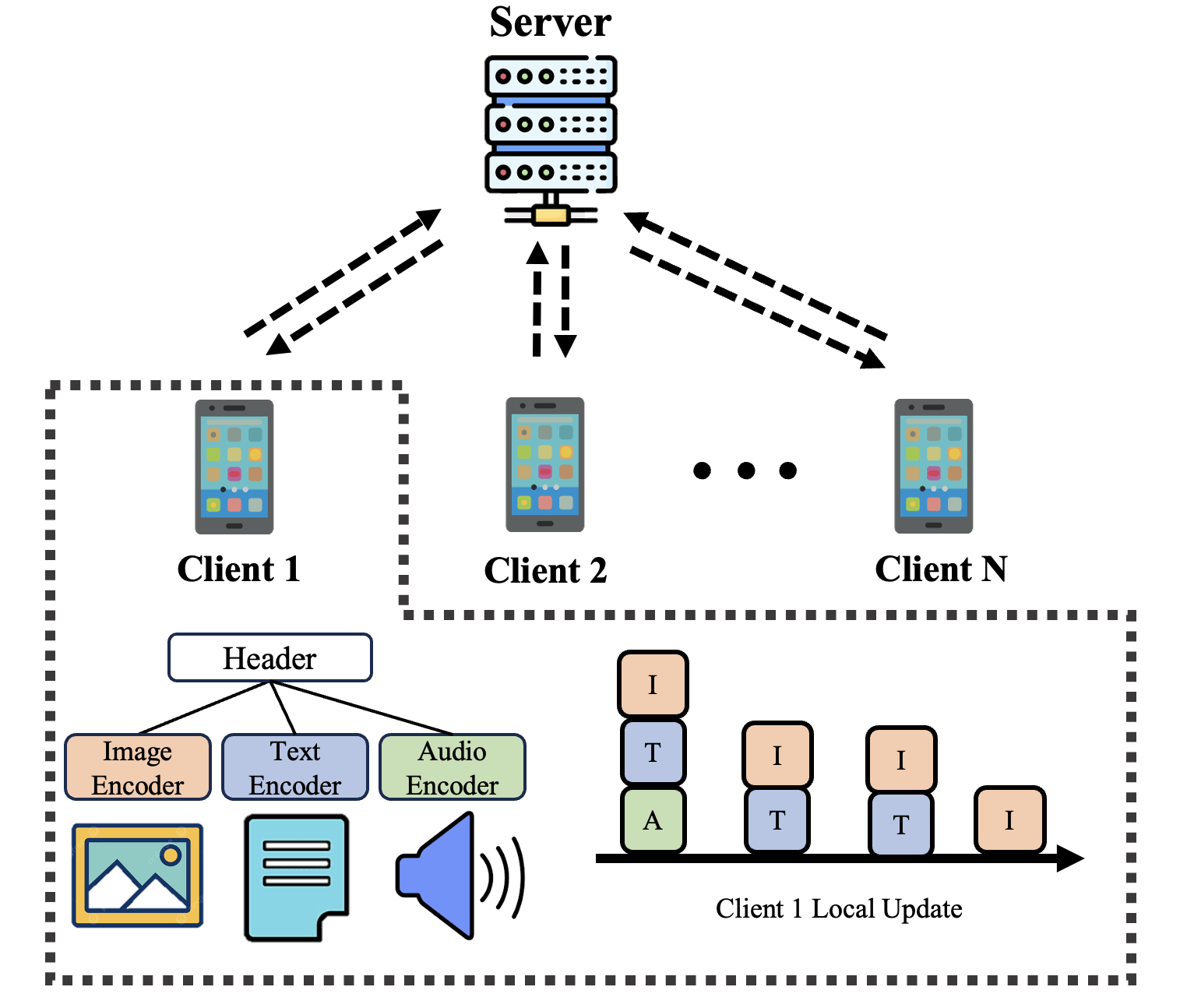
0
Prioritizing Modalities: Flexible Importance Scheduling in Federated Multimodal Learning
Jieming Bian, Lei Wang, Jie Xu
Federated Learning (FL) is a distributed machine learning approach that enables devices to collaboratively train models without sharing their local data, ensuring user privacy and scalability. However, applying FL to real-world data presents challenges, particularly as most existing FL research focuses on unimodal data. Multimodal Federated Learning (MFL) has emerged to address these challenges, leveraging modality-specific encoder models to process diverse datasets. Current MFL methods often uniformly allocate computational frequencies across all modalities, which is inefficient for IoT devices with limited resources. In this paper, we propose FlexMod, a novel approach to enhance computational efficiency in MFL by adaptively allocating training resources for each modality encoder based on their importance and training requirements. We employ prototype learning to assess the quality of modality encoders, use Shapley values to quantify the importance of each modality, and adopt the Deep Deterministic Policy Gradient (DDPG) method from deep reinforcement learning to optimize the allocation of training resources. Our method prioritizes critical modalities, optimizing model performance and resource utilization. Experimental results on three real-world datasets demonstrate that our proposed method significantly improves the performance of MFL models.
Read more8/14/2024