Rethinking Backdoor Detection Evaluation for Language Models

0

Sign in to get full access
Overview
- Rethinking the evaluation of backdoor detection for language models
- Highlights issues with current evaluation approaches and proposes improvements
- Focuses on the unique challenges of backdoor detection in language models
Plain English Explanation
The paper Rethinking Backdoor Detection Evaluation for Language Models explores the challenges of detecting backdoors in large language models. Backdoors are vulnerabilities that can be intentionally introduced into AI models, allowing attackers to trigger unintended model behaviors.
The authors argue that existing evaluation approaches for backdoor detection do not fully capture the unique characteristics of language models. They propose new evaluation metrics and methodologies to better assess the effectiveness of backdoor detection techniques for these complex models.
Technical Explanation
The paper first outlines the limitations of current backdoor detection evaluation, which often rely on simple classification tasks or synthetic data. The authors highlight how these approaches fail to capture the nuances of language understanding and generation in large language models.
To address this, the researchers introduce new evaluation protocols that incorporate more realistic attack scenarios and natural language benchmarks. This includes evaluating backdoor detection on downstream tasks like sentiment analysis and question answering, as well as assessing the impact of backdoors on model outputs.
The paper also discusses the challenges of constructing high-quality backdoor trigger sets for language models, which can be more difficult than for computer vision models due to the complexities of natural language. The authors propose techniques to generate diverse and representative backdoor triggers.
Through extensive experiments, the researchers demonstrate that existing backdoor detection methods struggle to reliably identify vulnerabilities in language models. They argue that the community needs to rethink evaluation practices to develop more robust and effective detection approaches.
Critical Analysis
The paper raises important concerns about the limitations of current backdoor detection evaluation for language models. The authors make a compelling case that existing techniques fall short in capturing the unique characteristics of these complex models.
However, the paper does not provide a complete solution to the problem. The proposed evaluation protocols and trigger generation methods are a step in the right direction, but more research is needed to fully address the challenges of backdoor detection in language models.
Additionally, the paper does not delve into the potential societal implications of backdoor vulnerabilities in large language models, which could have far-reaching consequences if exploited. Future research should also consider the ethical and security considerations of these issues.
Conclusion
This paper highlights the need to rethink the evaluation of backdoor detection for language models. The authors demonstrate the shortcomings of existing approaches and propose new methodologies to better assess the effectiveness of detection techniques.
The insights from this research can inform the development of more robust and reliable backdoor detection systems, which will be crucial as large language models become increasingly prevalent in a wide range of applications. Continued efforts in this area can help ensure the security and trustworthiness of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking Backdoor Detection Evaluation for Language Models
Jun Yan, Wenjie Jacky Mo, Xiang Ren, Robin Jia
Backdoor attacks, in which a model behaves maliciously when given an attacker-specified trigger, pose a major security risk for practitioners who depend on publicly released language models. Backdoor detection methods aim to detect whether a released model contains a backdoor, so that practitioners can avoid such vulnerabilities. While existing backdoor detection methods have high accuracy in detecting backdoored models on standard benchmarks, it is unclear whether they can robustly identify backdoors in the wild. In this paper, we examine the robustness of backdoor detectors by manipulating different factors during backdoor planting. We find that the success of existing methods highly depends on how intensely the model is trained on poisoned data during backdoor planting. Specifically, backdoors planted with either more aggressive or more conservative training are significantly more difficult to detect than the default ones. Our results highlight a lack of robustness of existing backdoor detectors and the limitations in current benchmark construction.
Read more9/4/2024

0
Exploiting the Vulnerability of Large Language Models via Defense-Aware Architectural Backdoor
Abdullah Arafat Miah, Yu Bi
Deep neural networks (DNNs) have long been recognized as vulnerable to backdoor attacks. By providing poisoned training data in the fine-tuning process, the attacker can implant a backdoor into the victim model. This enables input samples meeting specific textual trigger patterns to be classified as target labels of the attacker's choice. While such black-box attacks have been well explored in both computer vision and natural language processing (NLP), backdoor attacks relying on white-box attack philosophy have hardly been thoroughly investigated. In this paper, we take the first step to introduce a new type of backdoor attack that conceals itself within the underlying model architecture. Specifically, we propose to design separate backdoor modules consisting of two functions: trigger detection and noise injection. The add-on modules of model architecture layers can detect the presence of input trigger tokens and modify layer weights using Gaussian noise to disturb the feature distribution of the baseline model. We conduct extensive experiments to evaluate our attack methods using two model architecture settings on five different large language datasets. We demonstrate that the training-free architectural backdoor on a large language model poses a genuine threat. Unlike the-state-of-art work, it can survive the rigorous fine-tuning and retraining process, as well as evade output probability-based defense methods (i.e. BDDR). All the code and data is available https://github.com/SiSL-URI/Arch_Backdoor_LLM.
Read more9/10/2024

0
A Survey of Backdoor Attacks and Defenses on Large Language Models: Implications for Security Measures
Shuai Zhao, Meihuizi Jia, Zhongliang Guo, Leilei Gan, Xiaoyu Xu, Xiaobao Wu, Jie Fu, Yichao Feng, Fengjun Pan, Luu Anh Tuan
Large Language Models (LLMs), which bridge the gap between human language understanding and complex problem-solving, achieve state-of-the-art performance on several NLP tasks, particularly in few-shot and zero-shot settings. Despite the demonstrable efficacy of LLMs, due to constraints on computational resources, users have to engage with open-source language models or outsource the entire training process to third-party platforms. However, research has demonstrated that language models are susceptible to potential security vulnerabilities, particularly in backdoor attacks. Backdoor attacks are designed to introduce targeted vulnerabilities into language models by poisoning training samples or model weights, allowing attackers to manipulate model responses through malicious triggers. While existing surveys on backdoor attacks provide a comprehensive overview, they lack an in-depth examination of backdoor attacks specifically targeting LLMs. To bridge this gap and grasp the latest trends in the field, this paper presents a novel perspective on backdoor attacks for LLMs by focusing on fine-tuning methods. Specifically, we systematically classify backdoor attacks into three categories: full-parameter fine-tuning, parameter-efficient fine-tuning, and no fine-tuning Based on insights from a substantial review, we also discuss crucial issues for future research on backdoor attacks, such as further exploring attack algorithms that do not require fine-tuning, or developing more covert attack algorithms.
Read more9/14/2024
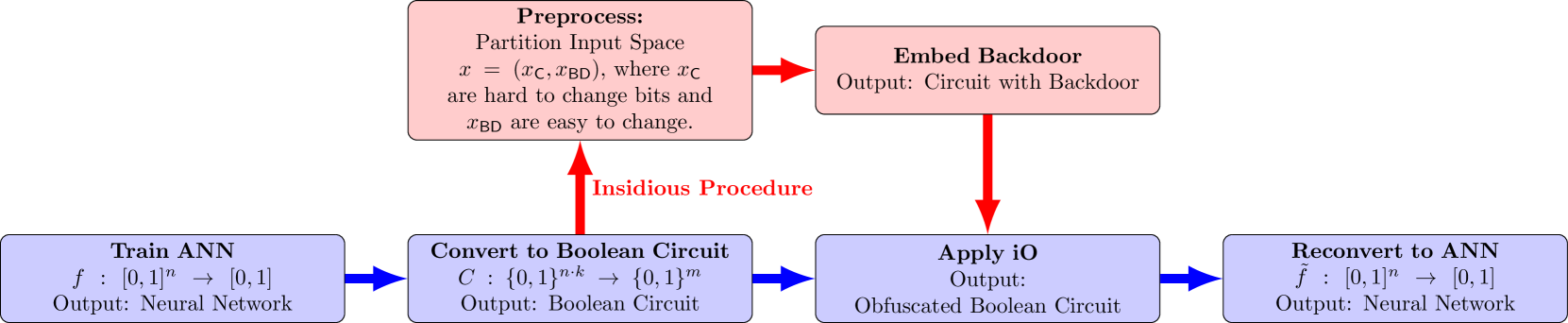
0
Injecting Undetectable Backdoors in Deep Learning and Language Models
Alkis Kalavasis, Amin Karbasi, Argyris Oikonomou, Katerina Sotiraki, Grigoris Velegkas, Manolis Zampetakis
As ML models become increasingly complex and integral to high-stakes domains such as finance and healthcare, they also become more susceptible to sophisticated adversarial attacks. We investigate the threat posed by undetectable backdoors, as defined in Goldwasser et al. (FOCS '22), in models developed by insidious external expert firms. When such backdoors exist, they allow the designer of the model to sell information on how to slightly perturb their input to change the outcome of the model. We develop a general strategy to plant backdoors to obfuscated neural networks, that satisfy the security properties of the celebrated notion of indistinguishability obfuscation. Applying obfuscation before releasing neural networks is a strategy that is well motivated to protect sensitive information of the external expert firm. Our method to plant backdoors ensures that even if the weights and architecture of the obfuscated model are accessible, the existence of the backdoor is still undetectable. Finally, we introduce the notion of undetectable backdoors to language models and extend our neural network backdoor attacks to such models based on the existence of steganographic functions.
Read more9/10/2024